Department of Computer Science, Virginia Tech, Blacksburg, Virginia, United States of America.
PLoS One. 2012;7(1):e29509. doi: 10.1371/journal.pone.0029509. Epub 2012 Jan 3.
There are now a multitude of articles published in a diversity of journals providing information about genes, proteins, pathways, and diseases. Each article investigates subsets of a biological process, but to gain insight into the functioning of a system as a whole, we must integrate information from multiple publications. Particularly, unraveling relationships between extra-cellular inputs and downstream molecular response mechanisms requires integrating conclusions from diverse publications.
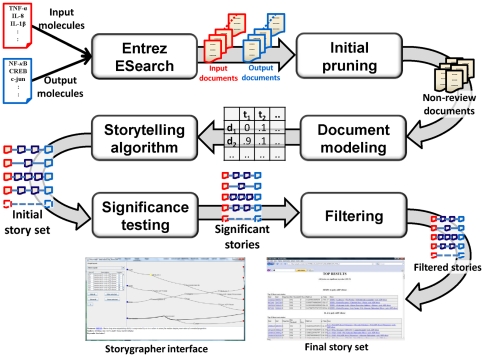
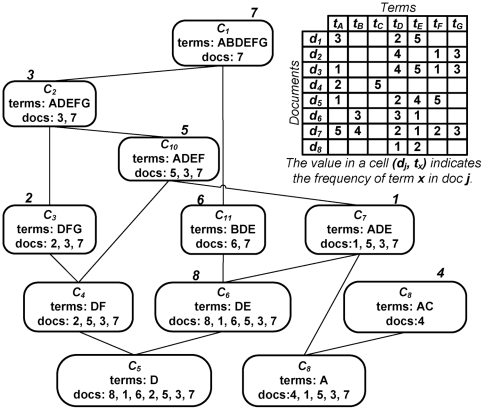
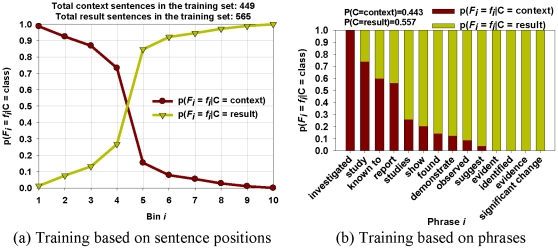
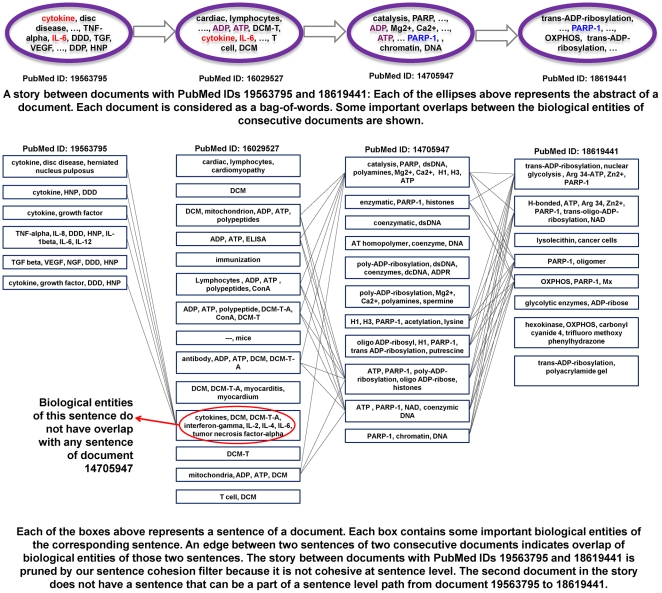
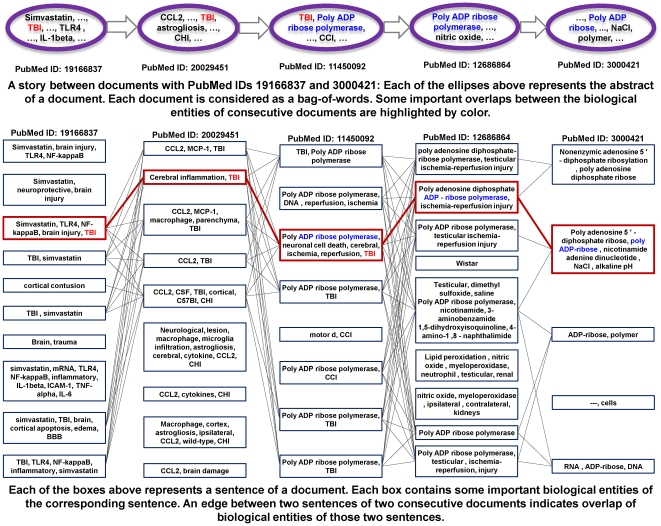
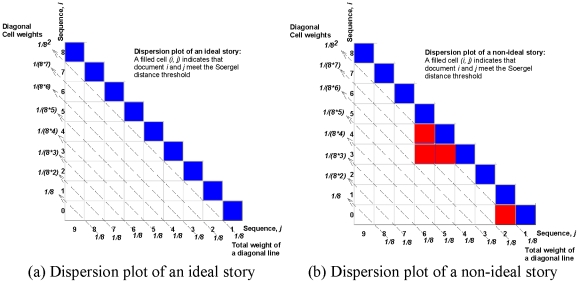
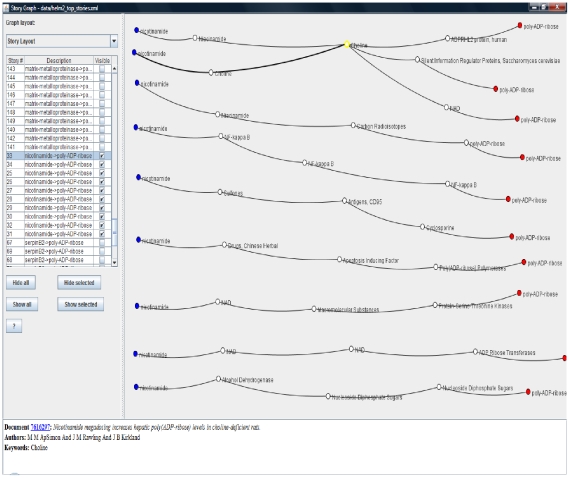
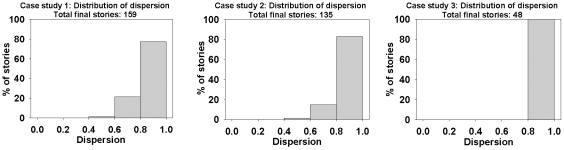
We present an automated approach to biological knowledge discovery from PubMed abstracts, suitable for "connecting the dots" across the literature. We describe a storytelling algorithm that, given a start and end publication, typically with little or no overlap in content, identifies a chain of intermediate publications from one to the other, such that neighboring publications have significant content similarity. The quality of discovered stories is measured using local criteria such as the size of supporting neighborhoods for each link and the strength of individual links connecting publications, as well as global metrics of dispersion. To ensure that the story stays coherent as it meanders from one publication to another, we demonstrate the design of novel coherence and overlap filters for use as post-processing steps.
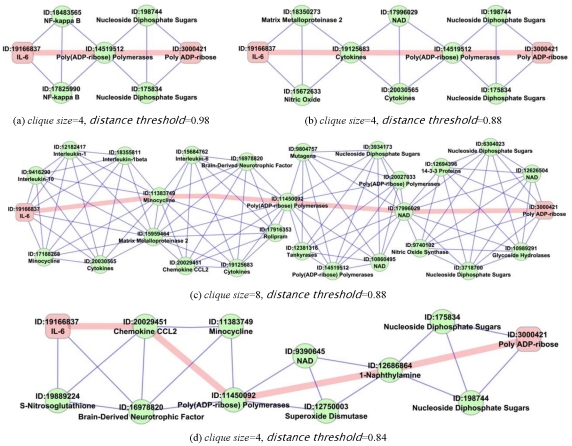
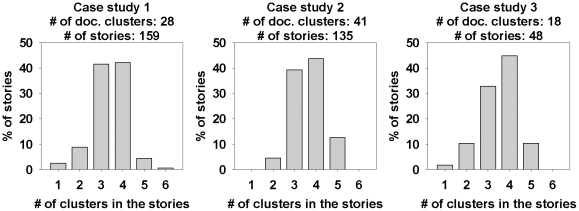
WE DEMONSTRATE THE APPLICATION OF OUR STORYTELLING ALGORITHM TO THREE CASE STUDIES: i) a many-one study exploring relationships between multiple cellular inputs and a molecule responsible for cell-fate decisions, ii) a many-many study exploring the relationships between multiple cytokines and multiple downstream transcription factors, and iii) a one-to-one study to showcase the ability to recover a cancer related association, viz. the Warburg effect, from past literature. The storytelling pipeline helps narrow down a scientist's focus from several hundreds of thousands of relevant documents to only around a hundred stories. We argue that our approach can serve as a valuable discovery aid for hypothesis generation and connection exploration in large unstructured biological knowledge bases.
现在有大量的文章发表在各种期刊上,提供关于基因、蛋白质、途径和疾病的信息。每篇文章都研究了生物过程的子集,但为了深入了解整个系统的功能,我们必须整合来自多个出版物的信息。特别是,要揭示细胞外输入与下游分子反应机制之间的关系,需要整合来自不同出版物的结论。
我们提出了一种从 PubMed 摘要中自动发现生物知识的方法,适用于“连接文献中的点”。我们描述了一种讲故事的算法,给定一个开始和结束的出版物,通常内容上几乎没有或没有重叠,该算法从一个出版物到另一个出版物识别出一连串的中间出版物,使得相邻的出版物具有显著的内容相似性。所发现的故事的质量使用局部标准来衡量,例如每个链接的支持邻域的大小和连接出版物的各个链接的强度,以及全局分散度指标。为了确保故事在从一个出版物到另一个出版物的曲折过程中保持连贯性,我们展示了新颖的连贯性和重叠过滤器的设计,作为后处理步骤。
我们展示了我们的讲故事算法在三个案例研究中的应用:i)一项多对一的研究,探索了多个细胞输入与负责细胞命运决定的分子之间的关系,ii)一项多对多的研究,探索了多个细胞因子与多个下游转录因子之间的关系,以及 iii)一项一对一的研究,展示了从过去文献中恢复与癌症相关的关联的能力,即沃伯格效应。讲故事的管道帮助科学家将注意力从数十万篇相关文献缩小到只有大约一百个故事。我们认为,我们的方法可以作为在大型非结构化生物知识库中生成假设和探索连接的有价值的发现辅助工具。