Rosenholtz Ruth, Huang Jie, Ehinger Krista A
Department of Brain and Cognitive Sciences, Massachusetts Institute of Technology Cambridge, MA, USA.
Front Psychol. 2012 Feb 6;3:13. doi: 10.3389/fpsyg.2012.00013. eCollection 2012.
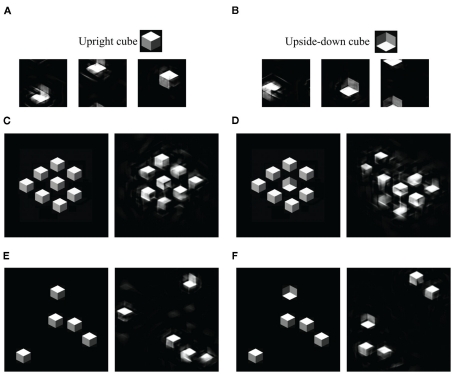
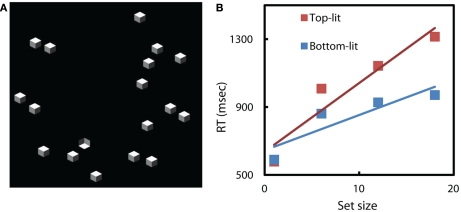
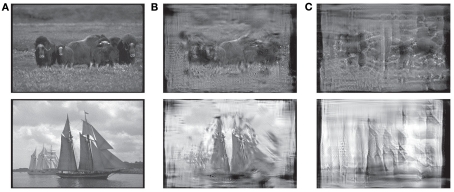
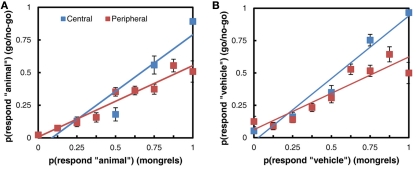
According to common wisdom in the field of visual perception, top-down selective attention is required in order to bind features into objects. In this view, even simple tasks, such as distinguishing a rotated T from a rotated L, require selective attention since they require feature binding. Selective attention, in turn, is commonly conceived as involving volition, intention, and at least implicitly, awareness. There is something non-intuitive about the notion that we might need so expensive (and possibly human) a resource as conscious awareness in order to perform so basic a function as perception. In fact, we can carry out complex sensorimotor tasks, seemingly in the near absence of awareness or volitional shifts of attention ("zombie behaviors"). More generally, the tight association between attention and awareness, and the presumed role of attention on perception, is problematic. We propose that under normal viewing conditions, the main processes of feature binding and perception proceed largely independently of top-down selective attention. Recent work suggests that there is a significant loss of information in early stages of visual processing, especially in the periphery. In particular, our texture tiling model (TTM) represents images in terms of a fixed set of "texture" statistics computed over local pooling regions that tile the visual input. We argue that this lossy representation produces the perceptual ambiguities that have previously been as ascribed to a lack of feature binding in the absence of selective attention. At the same time, the TTM representation is sufficiently rich to explain performance in such complex tasks as scene gist recognition, pop-out target search, and navigation. A number of phenomena that have previously been explained in terms of voluntary attention can be explained more parsimoniously with the TTM. In this model, peripheral vision introduces a specific kind of information loss, and the information available to an observer varies greatly depending upon shifts of the point of gaze (which usually occur without awareness). The available information, in turn, provides a key determinant of the visual system's capabilities and deficiencies. This scheme dissociates basic perceptual operations, such as feature binding, from both top-down attention and conscious awareness.
根据视觉感知领域的普遍观点,为了将特征绑定到物体中,需要自上而下的选择性注意。按照这种观点,即使是简单的任务,比如区分旋转的T和旋转的L,也需要选择性注意,因为它们需要特征绑定。反过来,选择性注意通常被认为涉及意志、意图,并且至少隐含着意识。认为我们可能需要像有意识的觉知这样昂贵(且可能是人类独有的)资源来执行像感知这样基本的功能,这一观点有些违背直觉。事实上,我们可以在几乎没有意识或注意力的意志性转移(“僵尸行为”)的情况下执行复杂的感觉运动任务。更一般地说,注意与意识之间的紧密关联以及注意在感知中假定的作用是有问题的。我们提出,在正常观察条件下,特征绑定和感知的主要过程在很大程度上独立于自上而下的选择性注意进行。最近的研究表明,在视觉处理的早期阶段存在大量信息损失,尤其是在视觉边缘区域。特别是,我们的纹理平铺模型(TTM)根据在平铺视觉输入的局部池化区域上计算的一组固定的“纹理”统计量来表示图像。我们认为这种有损表示产生了以前被归因于在没有选择性注意时缺乏特征绑定的感知模糊性。同时,TTM表示足够丰富,可以解释诸如场景主旨识别、弹出式目标搜索和导航等复杂任务中的表现。以前用自愿注意来解释的许多现象可以用TTM更简洁地解释。在这个模型中,周边视觉引入了一种特定类型的信息损失,并且观察者可获得的信息会因注视点的移动(通常在无意识的情况下发生)而有很大变化。反过来,可用信息是视觉系统能力和缺陷的关键决定因素。这种方案将诸如特征绑定等基本感知操作与自上而下的注意和意识分离开来。