Faculty of Health Sciences, University of Maribor, Maribor, Slovenia.
PLoS One. 2012;7(3):e33812. doi: 10.1371/journal.pone.0033812. Epub 2012 Mar 30.
Classification is an important and widely used machine learning technique in bioinformatics. Researchers and other end-users of machine learning software often prefer to work with comprehensible models where knowledge extraction and explanation of reasoning behind the classification model are possible.
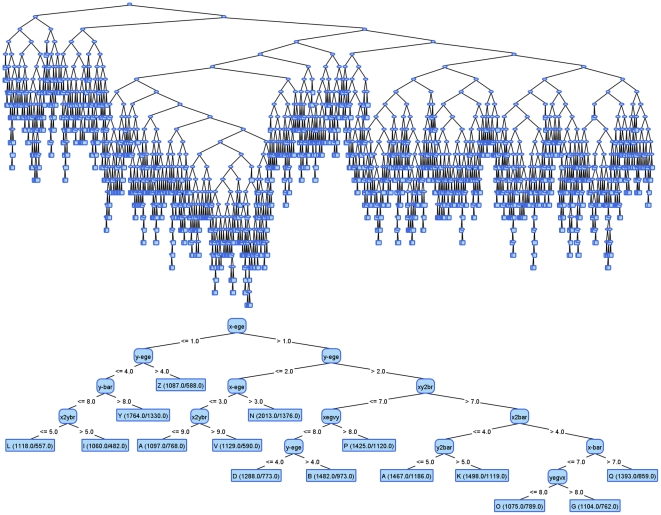
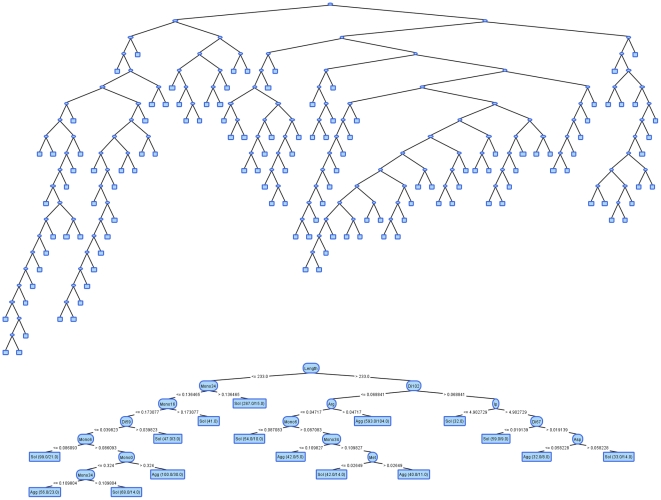
This paper presents an extension to an existing machine learning environment and a study on visual tuning of decision tree classifiers. The motivation for this research comes from the need to build effective and easily interpretable decision tree models by so called one-button data mining approach where no parameter tuning is needed. To avoid bias in classification, no classification performance measure is used during the tuning of the model that is constrained exclusively by the dimensions of the produced decision tree.
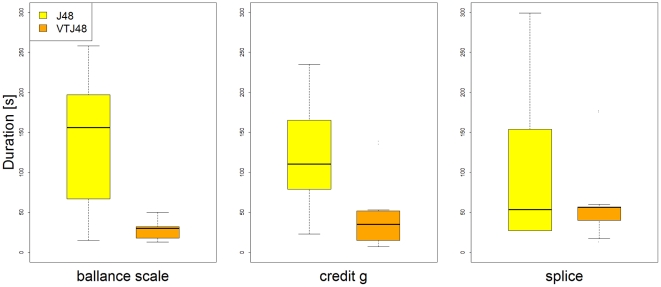
The proposed visual tuning of decision trees was evaluated on 40 datasets containing classical machine learning problems and 31 datasets from the field of bioinformatics. Although we did not expected significant differences in classification performance, the results demonstrate a significant increase of accuracy in less complex visually tuned decision trees. In contrast to classical machine learning benchmarking datasets, we observe higher accuracy gains in bioinformatics datasets. Additionally, a user study was carried out to confirm the assumption that the tree tuning times are significantly lower for the proposed method in comparison to manual tuning of the decision tree.
The empirical results demonstrate that by building simple models constrained by predefined visual boundaries, one not only achieves good comprehensibility, but also very good classification performance that does not differ from usually more complex models built using default settings of the classical decision tree algorithm. In addition, our study demonstrates the suitability of visually tuned decision trees for datasets with binary class attributes and a high number of possibly redundant attributes that are very common in bioinformatics.
分类是生物信息学中一种重要且广泛使用的机器学习技术。机器学习软件的研究人员和其他最终用户通常更愿意使用可理解的模型,这些模型可以提取知识并解释分类模型背后的推理。
本文提出了对现有机器学习环境的扩展以及对决策树分类器的可视化调整的研究。这项研究的动机来自于通过所谓的一键式数据挖掘方法构建有效且易于解释的决策树模型的需求,在这种方法中不需要进行参数调整。为了避免分类偏差,在调整模型时不使用任何分类性能度量标准,该模型仅受生成的决策树的维度限制。
在所提出的决策树可视化调整中,我们在包含经典机器学习问题的 40 个数据集和来自生物信息学领域的 31 个数据集上进行了评估。虽然我们预计在分类性能方面不会有显著差异,但结果表明,在视觉上调整后的决策树中,准确性显著提高,并且决策树更简单。与经典机器学习基准数据集相比,我们观察到生物信息学数据集的准确性增益更高。此外,进行了用户研究以验证这样的假设,即与手动调整决策树相比,所提出的方法的树调整时间明显更短。
实验结果表明,通过构建受预定义可视化边界约束的简单模型,不仅可以实现良好的可理解性,而且还可以获得非常好的分类性能,其与通常使用经典决策树算法的默认设置构建的更复杂模型没有区别。此外,我们的研究还表明,对于具有二进制类属性和许多可能冗余属性的数据集,可视化调整后的决策树是合适的,这些数据集在生物信息学中非常常见。