Department of Biology, University of Florida, Gainesville, FL 32611, USA.
Syst Biol. 2012 Dec 1;61(6):955-72. doi: 10.1093/sysbio/sys055. Epub 2012 May 30.
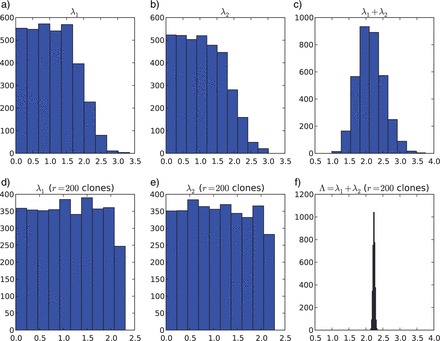
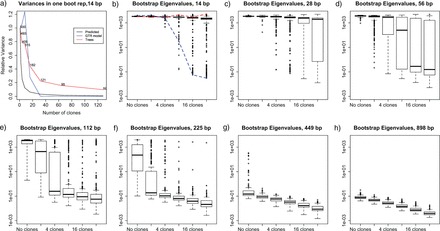
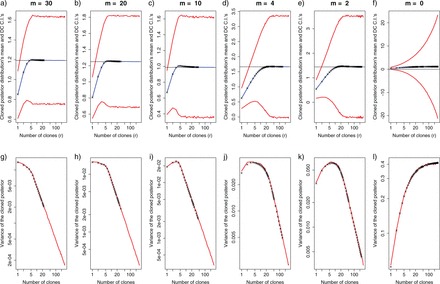
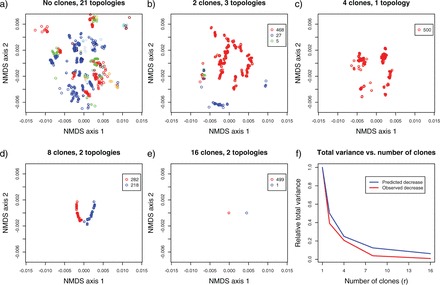
The success of model-based methods in phylogenetics has motivated much research aimed at generating new, biologically informative models. This new computer-intensive approach to phylogenetics demands validation studies and sound measures of performance. To date there has been little practical guidance available as to when and why the parameters in a particular model can be identified reliably. Here, we illustrate how Data Cloning (DC), a recently developed methodology to compute the maximum likelihood estimates along with their asymptotic variance, can be used to diagnose structural parameter nonidentifiability (NI) and distinguish it from other parameter estimability problems, including when parameters are structurally identifiable, but are not estimable in a given data set (INE), and when parameters are identifiable, and estimable, but only weakly so (WE). The application of the DC theorem uses well-known and widely used Bayesian computational techniques. With the DC approach, practitioners can use Bayesian phylogenetics software to diagnose nonidentifiability. Theoreticians and practitioners alike now have a powerful, yet simple tool to detect nonidentifiability while investigating complex modeling scenarios, where getting closed-form expressions in a probabilistic study is complicated. Furthermore, here we also show how DC can be used as a tool to examine and eliminate the influence of the priors, in particular if the process of prior elicitation is not straightforward. Finally, when applied to phylogenetic inference, DC can be used to study at least two important statistical questions: assessing identifiability of discrete parameters, like the tree topology, and developing efficient sampling methods for computationally expensive posterior densities.
基于模型的方法在系统发育学中的成功激发了大量旨在生成新的、具有生物学信息量的模型的研究。这种新的计算机密集型系统发育学方法需要验证研究和可靠的性能衡量标准。迄今为止,关于何时以及为何可以可靠地识别特定模型中的参数,几乎没有实际的指导。在这里,我们将说明如何使用最近开发的一种方法 Data Cloning(DC)来计算最大似然估计及其渐近方差,以诊断结构参数不可识别性(NI),并将其与其他参数可估计性问题区分开来,包括参数在结构上可识别但在给定数据集中不可估计(INE)的情况,以及参数在结构上可识别且可估计但仅微弱可估计(WE)的情况。DC 定理的应用使用了众所周知且广泛使用的贝叶斯计算技术。通过使用 DC 方法,从业者可以使用贝叶斯系统发育学软件来诊断不可识别性。理论家和从业者现在都有了一个强大而简单的工具,可以在调查复杂的建模场景时检测不可识别性,在这种情况下,在概率研究中获得闭式表达式是很复杂的。此外,我们还展示了如何将 DC 用作一种工具来检查和消除先验的影响,特别是如果先验的启发过程不直接。最后,当应用于系统发育推断时,DC 可用于研究至少两个重要的统计问题:评估离散参数(如树拓扑)的可识别性,以及为计算昂贵的后验密度开发有效的抽样方法。