Institute of Computer Science, University of Tartu, Liivi 2, Tartu 50409, Estonia.
Bioinformatics. 2013 Apr 1;29(7):886-93. doi: 10.1093/bioinformatics/btt066. Epub 2013 Feb 14.
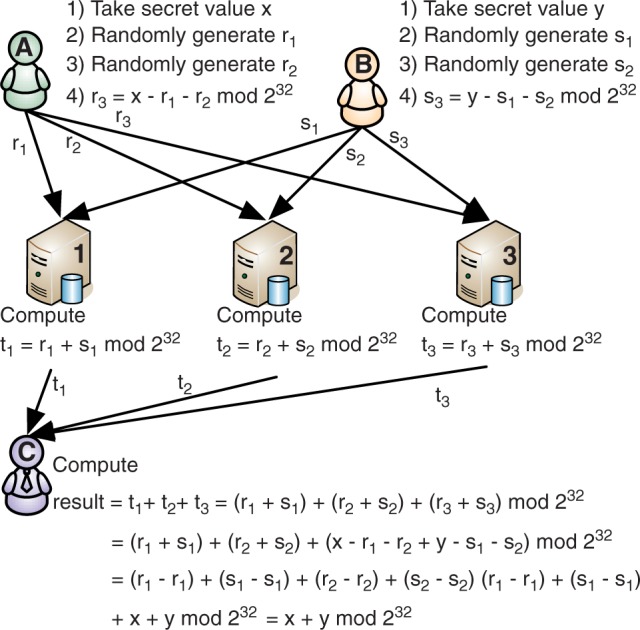
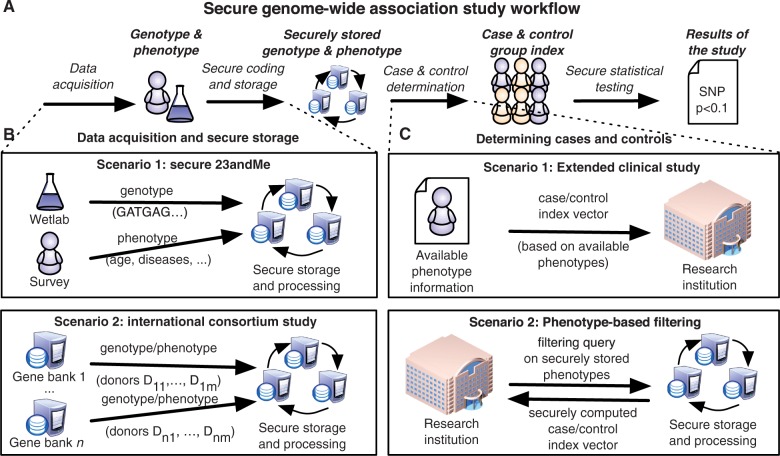
Increased availability of various genotyping techniques has initiated a race for finding genetic markers that can be used in diagnostics and personalized medicine. Although many genetic risk factors are known, key causes of common diseases with complex heritage patterns are still unknown. Identification of such complex traits requires a targeted study over a large collection of data. Ideally, such studies bring together data from many biobanks. However, data aggregation on such a large scale raises many privacy issues.
We show how to conduct such studies without violating privacy of individual donors and without leaking the data to third parties. The presented solution has provable security guarantees.
Supplementary data are available at Bioinformatics online.
各种基因分型技术的可用性不断提高,引发了一场寻找可用于诊断和个性化医疗的遗传标记物的竞赛。尽管已经发现了许多遗传风险因素,但具有复杂遗传模式的常见疾病的关键病因仍不清楚。识别此类复杂特征需要对大量数据进行有针对性的研究。理想情况下,此类研究将汇集来自多个生物库的数据。然而,如此大规模的数据聚合引发了许多隐私问题。
我们展示了如何在不侵犯个体捐赠者隐私的情况下进行此类研究,并且不会将数据泄露给第三方。所提出的解决方案具有可证明的安全保证。
补充数据可在“Bioinformatics”在线获取。