Department of Psychology, University of Texas at Austin, USA.
Psychol Sci. 2013 May;24(5):751-61. doi: 10.1177/0956797612463080. Epub 2013 Apr 4.
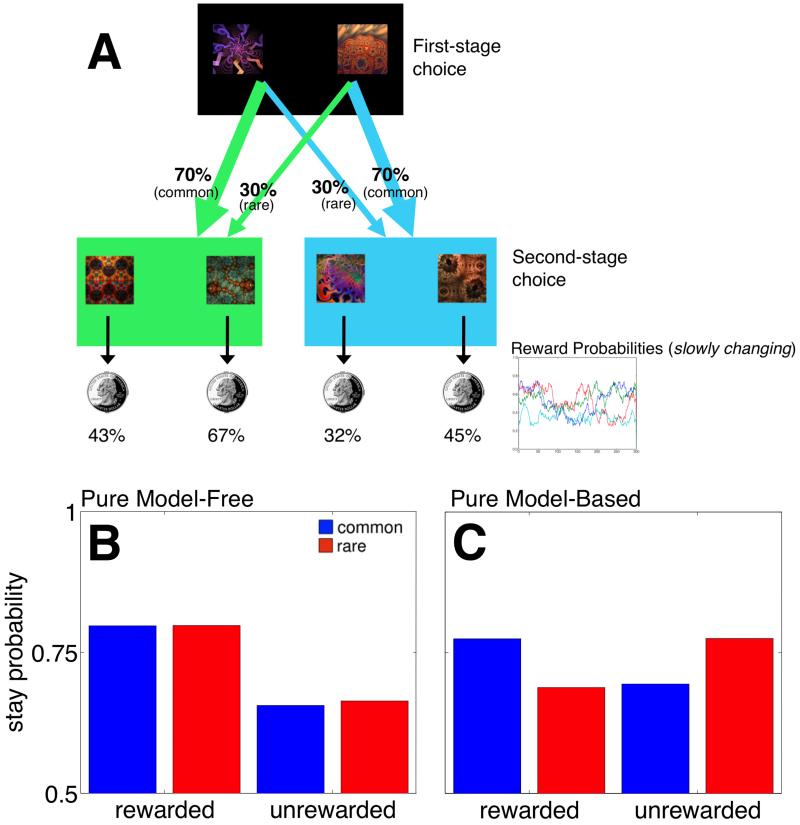
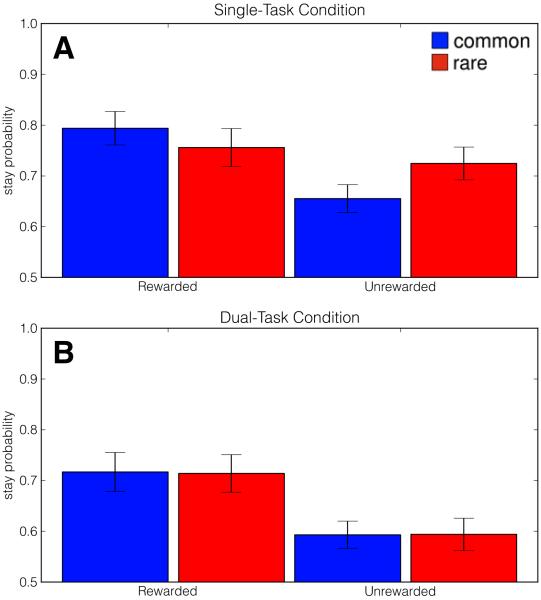
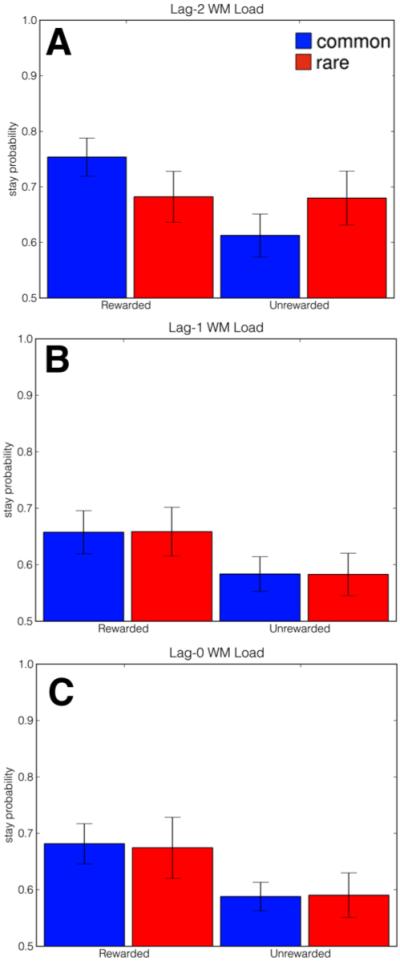
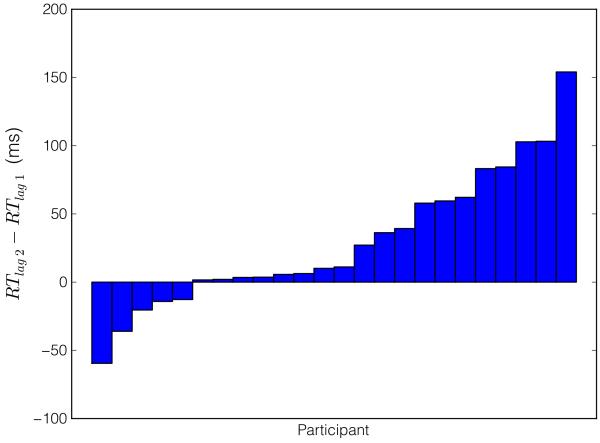
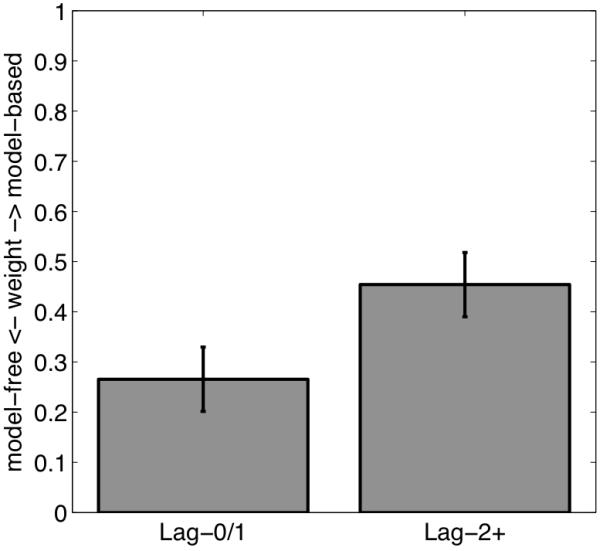
A number of accounts of human and animal behavior posit the operation of parallel and competing valuation systems in the control of choice behavior. In these accounts, a flexible but computationally expensive model-based reinforcement-learning system has been contrasted with a less flexible but more efficient model-free reinforcement-learning system. The factors governing which system controls behavior-and under what circumstances-are still unclear. Following the hypothesis that model-based reinforcement learning requires cognitive resources, we demonstrated that having human decision makers perform a demanding secondary task engenders increased reliance on a model-free reinforcement-learning strategy. Further, we showed that, across trials, people negotiate the trade-off between the two systems dynamically as a function of concurrent executive-function demands, and people's choice latencies reflect the computational expenses of the strategy they employ. These results demonstrate that competition between multiple learning systems can be controlled on a trial-by-trial basis by modulating the availability of cognitive resources.
许多关于人类和动物行为的描述都假设,在控制选择行为时,存在并行且相互竞争的估值系统在起作用。在这些描述中,一个灵活但计算成本高的基于模型的强化学习系统与一个不那么灵活但更有效的无模型强化学习系统形成了对比。然而,控制哪个系统来控制行为的因素——以及在什么情况下——仍然不清楚。根据基于模型的强化学习需要认知资源的假设,我们证明了让人类决策者执行一项要求很高的次要任务会导致更多地依赖无模型强化学习策略。此外,我们还表明,在整个试验过程中,人们会根据并发执行功能需求,动态地协商两个系统之间的权衡取舍,并且人们的选择潜伏期反映了他们所采用策略的计算成本。这些结果表明,通过调节认知资源的可用性,可以在每次试验的基础上控制多个学习系统之间的竞争。