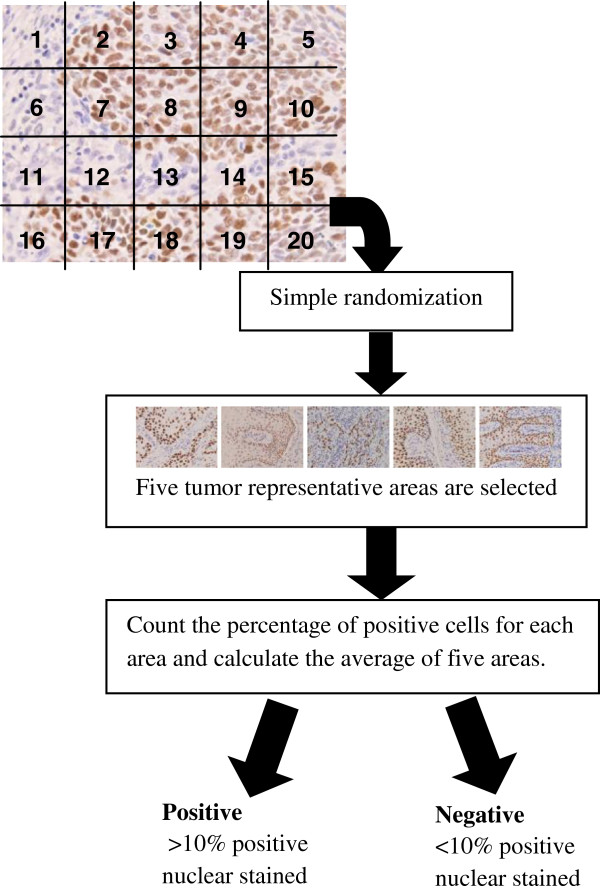
Bioinformatics and Computational Biology, Institute of Biological Science, Faculty of Science, University of Malaya, Kuala Lumpur, Malaysia.
BMC Bioinformatics. 2013 May 31;14:170. doi: 10.1186/1471-2105-14-170.
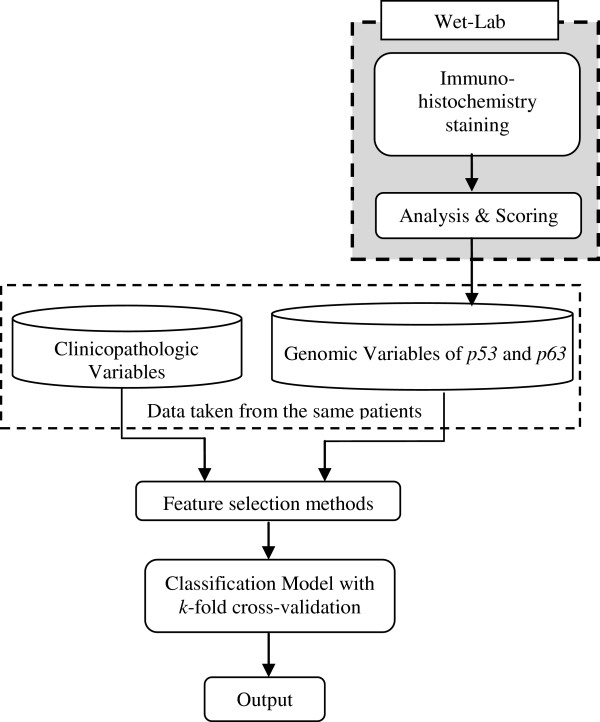
Machine learning techniques are becoming useful as an alternative approach to conventional medical diagnosis or prognosis as they are good for handling noisy and incomplete data, and significant results can be attained despite a small sample size. Traditionally, clinicians make prognostic decisions based on clinicopathologic markers. However, it is not easy for the most skilful clinician to come out with an accurate prognosis by using these markers alone. Thus, there is a need to use genomic markers to improve the accuracy of prognosis. The main aim of this research is to apply a hybrid of feature selection and machine learning methods in oral cancer prognosis based on the parameters of the correlation of clinicopathologic and genomic markers.
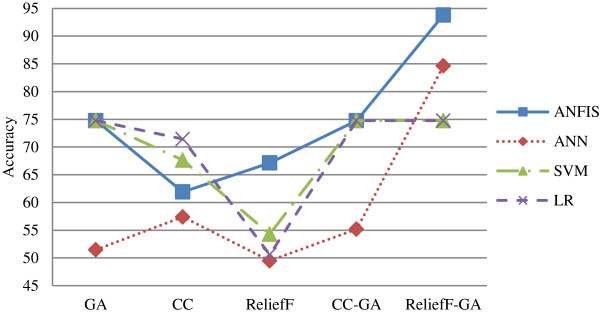
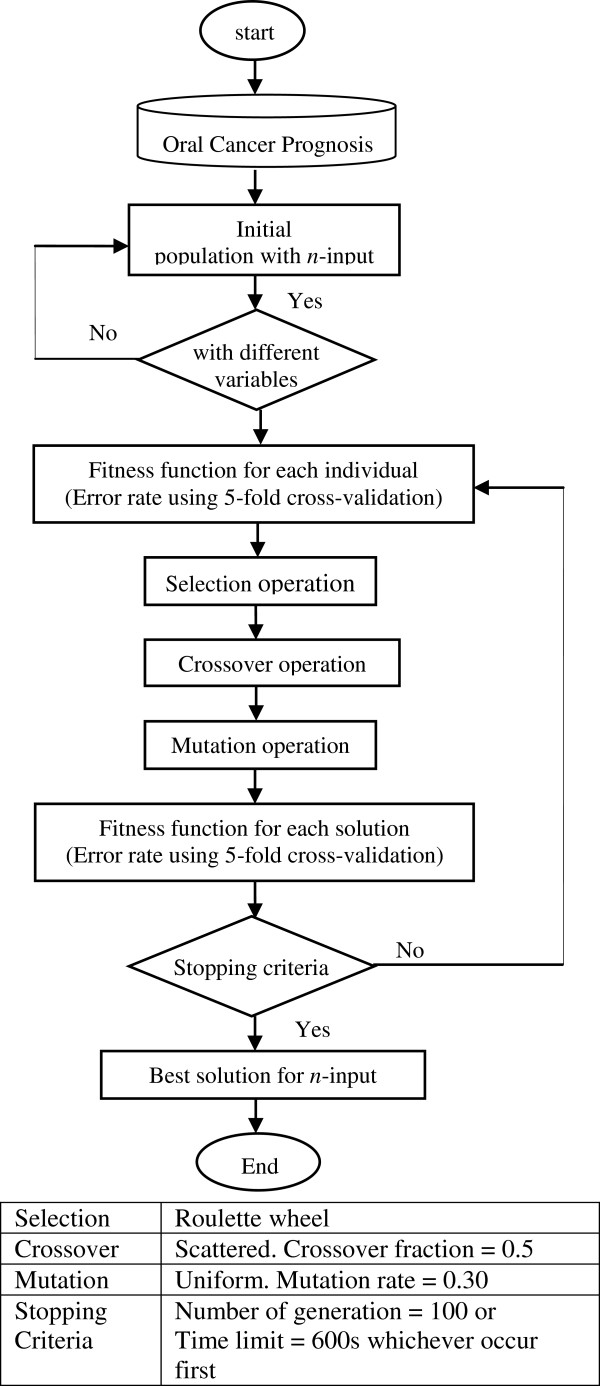
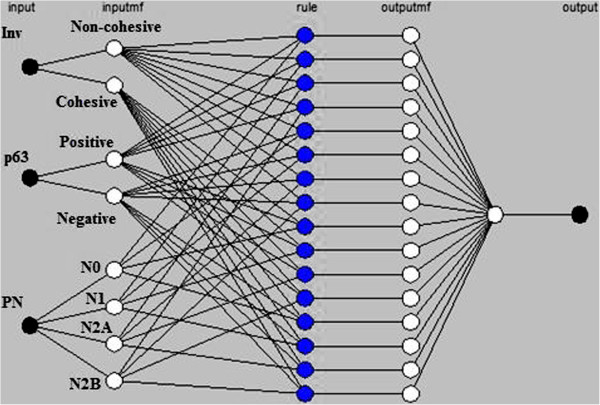
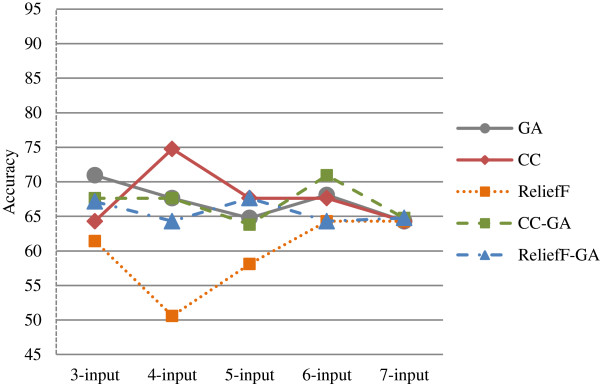
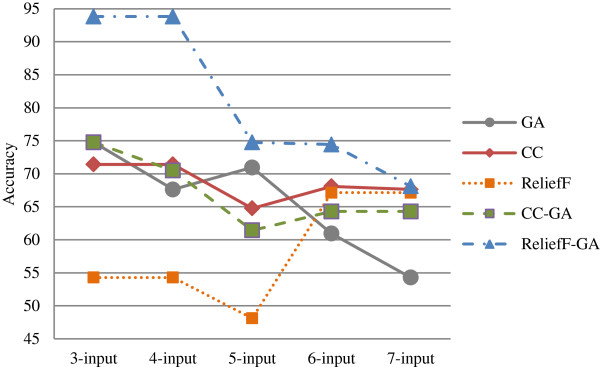
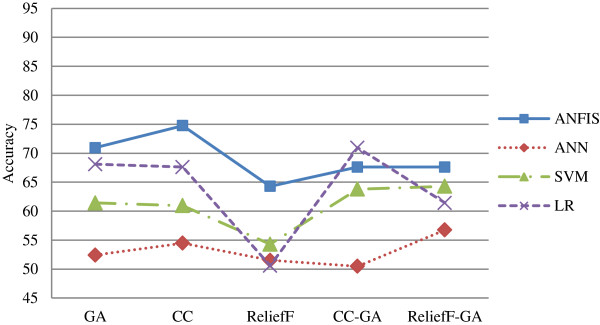
In the first stage of this research, five feature selection methods have been proposed and experimented on the oral cancer prognosis dataset. In the second stage, the model with the features selected from each feature selection methods are tested on the proposed classifiers. Four types of classifiers are chosen; these are namely, ANFIS, artificial neural network, support vector machine and logistic regression. A k-fold cross-validation is implemented on all types of classifiers due to the small sample size. The hybrid model of ReliefF-GA-ANFIS with 3-input features of drink, invasion and p63 achieved the best accuracy (accuracy = 93.81%; AUC = 0.90) for the oral cancer prognosis.
The results revealed that the prognosis is superior with the presence of both clinicopathologic and genomic markers. The selected features can be investigated further to validate the potential of becoming as significant prognostic signature in the oral cancer studies.
机器学习技术作为传统医学诊断或预后的替代方法变得越来越有用,因为它们擅长处理嘈杂和不完整的数据,并且即使样本量很小也能取得显著的结果。传统上,临床医生根据临床病理标志物做出预后决策。然而,即使是最熟练的临床医生,仅使用这些标志物也不容易做出准确的预后。因此,需要使用基因组标志物来提高预后的准确性。本研究的主要目的是应用特征选择和机器学习方法的混合方法,基于临床病理和基因组标志物的相关性参数,对口腔癌预后进行分析。
在本研究的第一阶段,提出了五种特征选择方法,并在口腔癌预后数据集上进行了实验。在第二阶段,使用从每种特征选择方法中选择的特征来测试所提出的分类器上的模型。选择了四种类型的分类器;这些是自适应神经模糊推理系统 (ANFIS)、人工神经网络、支持向量机和逻辑回归。由于样本量小,对所有类型的分类器都实施了 k 折交叉验证。具有 3 个输入特征(饮酒、侵袭和 p63)的 ReliefF-GA-ANFIS 混合模型在口腔癌预后中取得了最佳的准确性(准确性=93.81%;AUC=0.90)。
结果表明,同时存在临床病理和基因组标志物的预后效果更好。所选特征可以进一步研究,以验证其在口腔癌研究中成为有意义的预后标志物的潜力。