Departamento de Biología Molecular de Plantas, Instituto de Biotecnología, Universidad Nacional Autónoma de México Cuernavaca, Morelos, México.
Front Plant Sci. 2013 Jun 20;4:208. doi: 10.3389/fpls.2013.00208. eCollection 2013.
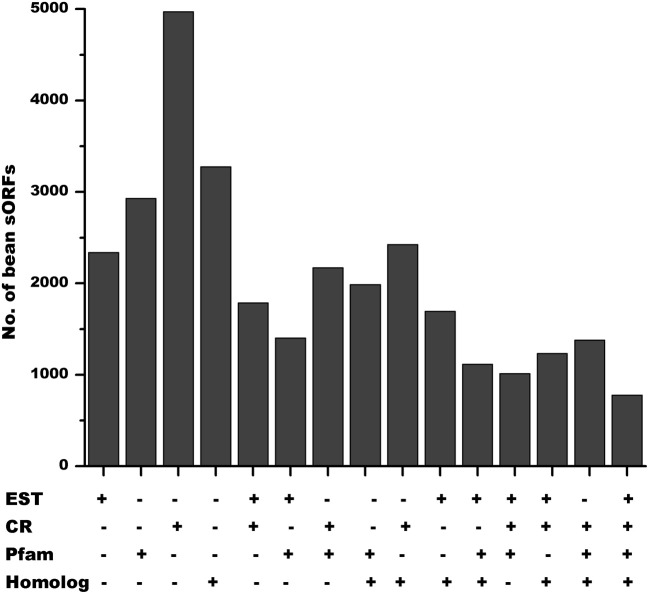
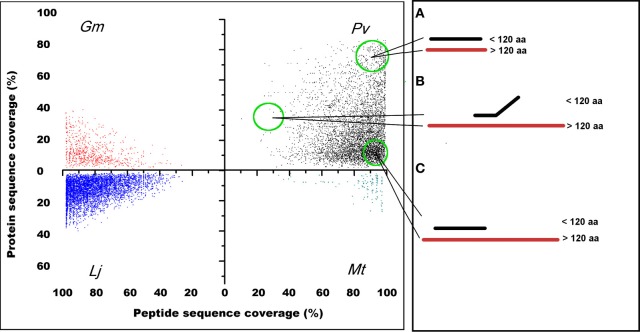
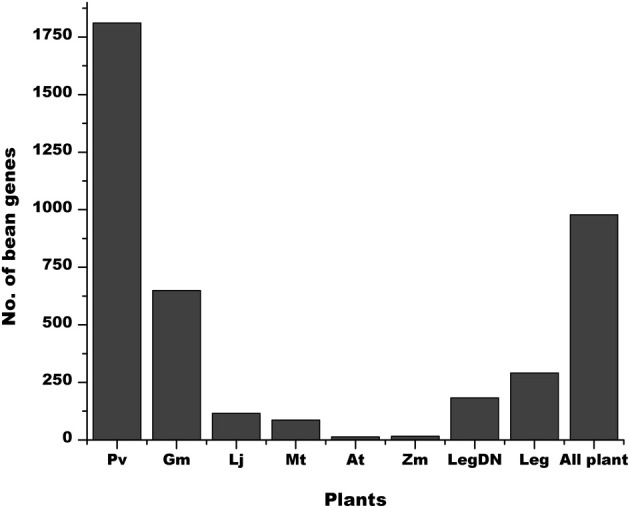
Diverse plant genome sequencing projects coupled with powerful bioinformatics tools have facilitated massive data analysis to construct specialized databases classified according to cellular function. However, there are still a considerable number of genes encoding proteins whose function has not yet been characterized. Included in this category are small proteins (SPs, 30-150 amino acids) encoded by short open reading frames (sORFs). SPs play important roles in plant physiology, growth, and development. Unfortunately, protocols focused on the genome-wide identification and characterization of sORFs are scarce or remain poorly implemented. As a result, these genes are underrepresented in many genome annotations. In this work, we exploited publicly available genome sequences of Phaseolus vulgaris, Medicago truncatula, Glycine max, and Lotus japonicus to analyze the abundance of annotated SPs in plant legumes. Our strategy to uncover bona fide sORFs at the genome level was centered in bioinformatics analysis of characteristics such as evidence of expression (transcription), presence of known protein regions or domains, and identification of orthologous genes in the genomes explored. We collected 6170, 10,461, 30,521, and 23,599 putative sORFs from P. vulgaris, G. max, M. truncatula, and L. japonicus genomes, respectively. Expressed sequence tags (ESTs) available in the DFCI Gene Index database provided evidence that ~one-third of the predicted legume sORFs are expressed. Most potential SPs have a counterpart in a different plant species and counterpart regions or domains in larger proteins. Potential functional sORFs were also classified according to a reduced set of GO categories, and the expression of 13 of them during P. vulgaris nodule ontogeny was confirmed by qPCR. This analysis provides a collection of sORFs that potentially encode for meaningful SPs, and offers the possibility of their further functional evaluation.
多样化的植物基因组测序项目结合强大的生物信息学工具,促进了大规模数据分析,构建了根据细胞功能分类的专业数据库。然而,仍然有相当数量的编码蛋白质的基因,其功能尚未被描述。这包括由短开放阅读框(sORFs)编码的小蛋白(SPs,30-150 个氨基酸)。SPs 在植物生理学、生长和发育中发挥着重要作用。不幸的是,专注于基因组范围内鉴定和描述 sORFs 的方案很少或实施效果不佳。因此,这些基因在许多基因组注释中代表性不足。在这项工作中,我们利用 Phaseolus vulgaris、Medicago truncatula、Glycine max 和 Lotus japonicus 的公开基因组序列,分析豆科植物中注释的 SPs 的丰度。我们在基因组水平上发现真正的 sORFs 的策略集中在对特征的生物信息学分析上,例如表达(转录)的证据、已知蛋白质区域或结构域的存在,以及在探索的基因组中鉴定同源基因。我们从 P. vulgaris、G. max、M. truncatula 和 L. japonicus 基因组中分别收集了 6170、10461、30521 和 23599 个推定的 sORFs。DFCI Gene Index 数据库中提供的表达序列标签(ESTs)证据表明,预测的豆科 sORFs 中有~三分之一是表达的。大多数潜在的 SPs 在不同的植物物种中都有对应的蛋白,并且在更大的蛋白质中有对应的区域或结构域。潜在的功能 sORFs 还根据一组减少的 GO 类别进行了分类,并且通过 qPCR 证实了其中 13 个在 P. vulgaris 根瘤发生过程中的表达。这项分析提供了一组可能编码有意义的 SPs 的 sORFs,并提供了进一步对其进行功能评估的可能性。