Department of Pediatrics, College of Medicine, Texas A&M University, College Station, TX, USA,
Qual Life Res. 2014 May;23(4):1233-43. doi: 10.1007/s11136-013-0544-0. Epub 2013 Oct 2.
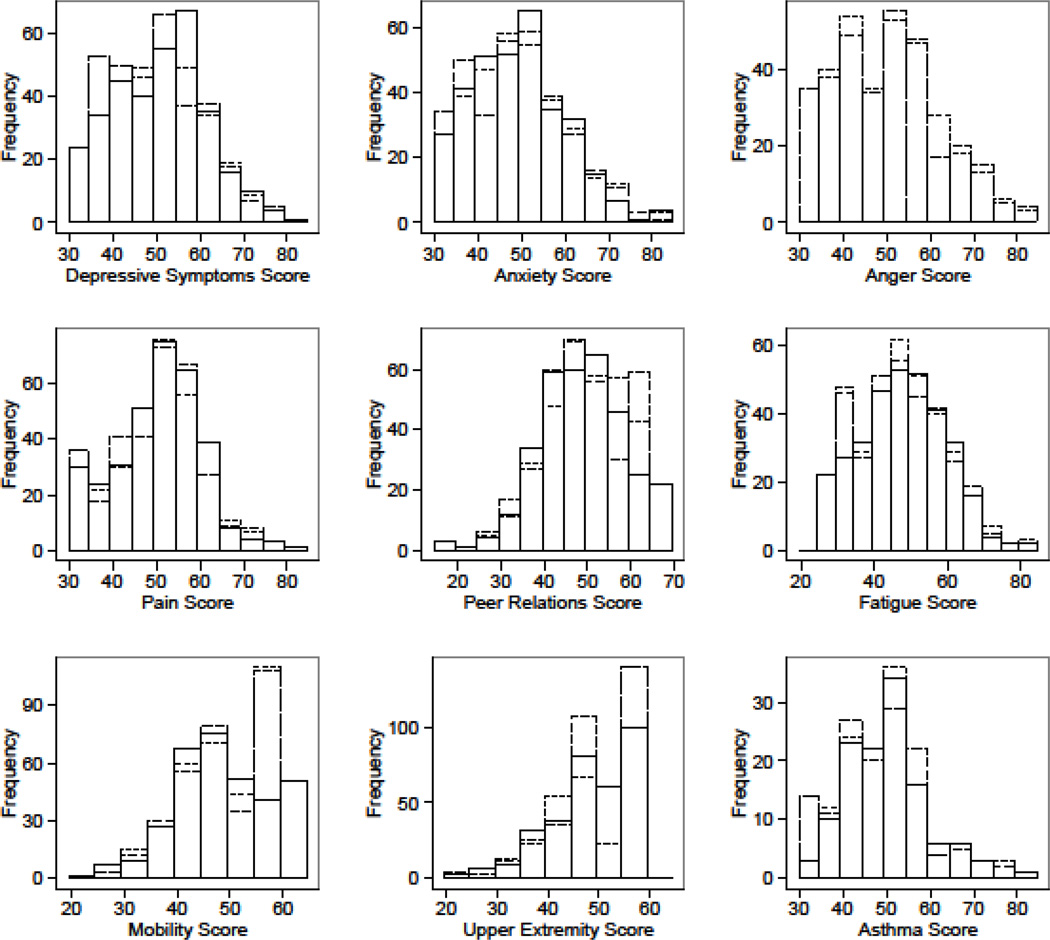
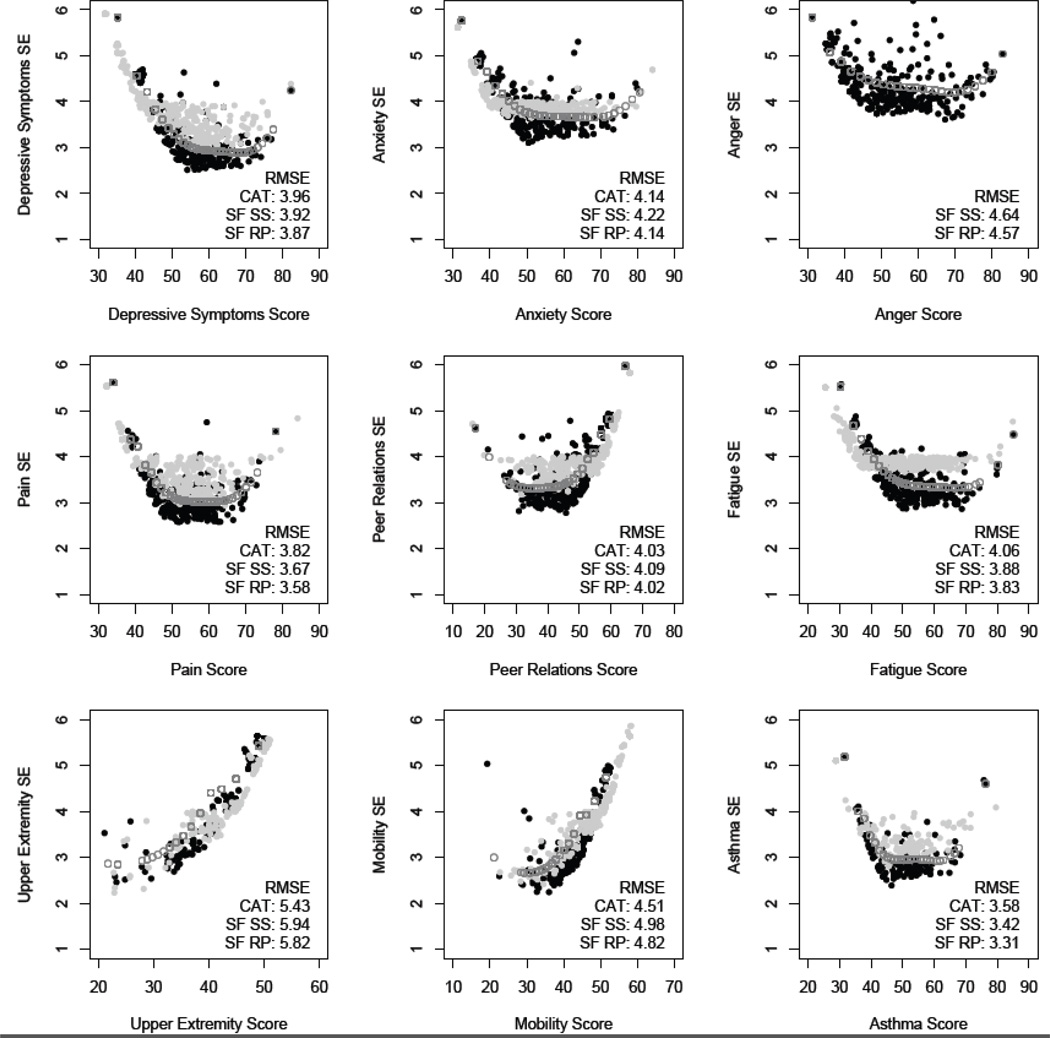
The objectives of the present study are to investigate the precision of static (fixed-length) short forms versus computerized adaptive testing (CAT) administration, response pattern scoring versus summed score conversion, and test-retest reliability (stability) of the Patient-Reported Outcomes Measurement Information System (PROMIS(®)) pediatric self-report scales measuring the latent constructs of depressive symptoms, anxiety, anger, pain interference, peer relationships, fatigue, mobility, upper extremity functioning, and asthma impact with polytomous items.
Participants (N = 331) between the ages of 8 and 17 were recruited from outpatient general pediatrics and subspecialty clinics. Of the 331 participants, 137 were diagnosed with asthma. Three scores based on item response theory (IRT) were computed for each respondent: CAT response pattern expected a posteriori estimates, short-form response pattern expected a posteriori estimates, and short-form summed score expected a posteriori estimates. Scores were also compared between participants with and without asthma. To examine test-retest reliability, 54 children were selected for retesting approximately 2 weeks after the first assessment.
A short CAT (maximum 12 items with a standard error of 0.4) was found, on average, to be less precise than the static short forms. The CAT appears to have limited usefulness over and above what can be accomplished with the existing static short forms (8-10 items). Stability of the scale scores over a 2-week period was generally supported.
The study provides further information on the psychometric properties of the PROMIS pediatric scales and extends the previous IRT analyses to include precision estimates of dynamic versus static administration, test-retest reliability, and validity of administration across groups. Both the positive and negative aspects of using CAT versus short forms are highlighted.
本研究旨在调查静态(固定长度)短式与计算机自适应测试(CAT)、反应模式评分与总和评分转换以及患者报告结局测量信息系统(PROMIS(®))儿科自评量表的测试重测信度(稳定性)的精确性,这些量表用于测量潜在的抑郁症状、焦虑、愤怒、疼痛干扰、同伴关系、疲劳、活动能力、上肢功能和哮喘影响等构念,这些量表的项目为多项选择题。
参与者(N=331)年龄在 8 至 17 岁之间,从门诊普通儿科和专科诊所招募。331 名参与者中,有 137 人被诊断为哮喘。为每位受访者计算了三种基于项目反应理论(IRT)的分数:CAT 反应模式后验预期估计值、短式反应模式后验预期估计值和短式总和评分后验预期估计值。还比较了有和没有哮喘的参与者之间的分数。为了检验测试重测信度,大约在第一次评估后两周,选择了 54 名儿童进行重测。
平均而言,一个简短的 CAT(最多 12 个项目,标准误为 0.4)发现比静态短式更不精确。CAT 似乎除了现有的静态短式(8-10 个项目)之外,并没有太多的用处。在两周的时间内,量表得分的稳定性得到了普遍支持。
本研究进一步提供了关于 PROMIS 儿科量表心理测量特性的信息,并将之前的 IRT 分析扩展到包括动态与静态管理的精确估计、测试重测信度以及跨组管理的有效性。强调了使用 CAT 与短式的优缺点。