Division of Plant Sciences, College of Life Sciences, University of Dundee at The James Hutton Institute, Invergowrie, Dundee DD2 5DA, UK.
Biotechnol Biofuels. 2013 Dec 21;6(1):185. doi: 10.1186/1754-6834-6-185.
In this study, a multi-parent population of barley cultivars was grown in the field for two consecutive years and then straw saccharification (sugar release by enzymes) was subsequently analysed in the laboratory to identify the cultivars with the highest consistent sugar yield. This experiment was used to assess the benefit of accounting for both the multi-phase and multi-environment aspects of large-scale phenotyping experiments with field-grown germplasm through sound statistical design and analysis.
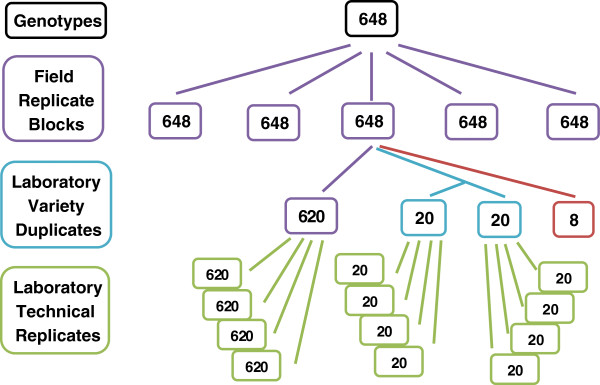
Complementary designs at both the field and laboratory phases of the experiment ensured that non-genetic sources of variation could be separated from the genetic variation of cultivars, which was the main target of the study. The field phase included biological replication and plot randomisation. The laboratory phase employed re-randomisation and technical replication of samples within a batch, with a subset of cultivars chosen as duplicates that were randomly allocated across batches. The resulting data was analysed using a linear mixed model that incorporated field and laboratory variation and a cultivar by trial interaction, and ensured that the cultivar means were more accurately represented than if the non-genetic variation was ignored. The heritability detected was more than doubled in each year of the trial by accounting for the non-genetic variation in the analysis, clearly showing the benefit of this design and approach.
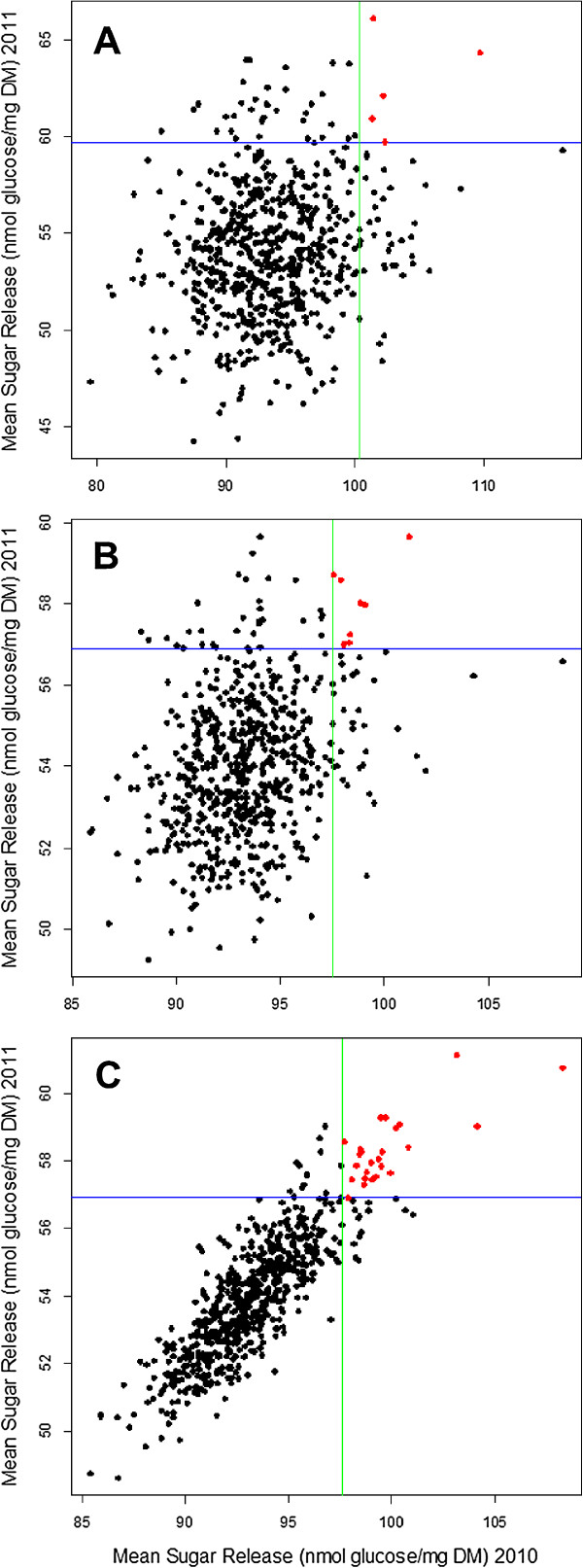
The importance of accounting for both field and laboratory variation, as well as the cultivar by trial interaction, by fitting a single statistical model (multi-environment trial, MET, model), was evidenced by the changes in list of the top 40 cultivars showing the highest sugar yields. Failure to account for this interaction resulted in only eight cultivars that were consistently in the top 40 in different years. The correspondence between the rankings of cultivars was much higher at 25 in the MET model. This approach is suited to any multi-phase and multi-environment population-based genetic experiment.
本研究在田间种植了一个大麦品种的多亲本群体,连续两年进行田间试验,然后在实验室进行秸秆糖化(酶促释放糖)分析,以鉴定具有最高一致性产糖量的品种。该实验用于评估通过合理的统计设计和分析,考虑到田间种质大规模表型实验的多阶段和多环境方面,是否会带来益处。
实验的田间和实验室阶段的补充设计确保了可以将非遗传来源的变异与品种的遗传变异区分开来,这是本研究的主要目标。田间阶段包括生物学重复和小区随机化。实验室阶段采用重随机化和批次内样本的技术重复,并选择部分品种作为重复,在批次间随机分配。使用包含田间和实验室变异以及品种试验互作的线性混合模型对结果进行分析,并确保比忽略非遗传变异更准确地表示品种均值。通过在分析中考虑非遗传变异,每年的试验检测到的遗传力都增加了一倍以上,这清楚地表明了这种设计和方法的优势。
通过拟合单个统计模型(多环境试验模型,MET 模型)来考虑田间和实验室的变异以及品种试验互作的重要性,通过该模型确定的前 40 个高糖产量品种列表发生了变化。如果不考虑这种互作,只有 8 个品种在不同年份始终排在前 40 位。在 MET 模型中,品种排名的一致性更高,达到 25。这种方法适用于任何多阶段和多环境的基于群体的遗传实验。