Min Jian-Liang, Xiao Xuan, Chou Kuo-Chen
Computer Department, Jing-De-Zhen Ceramic Institute, Jing-De-Zhen 333046, China.
Computer Department, Jing-De-Zhen Ceramic Institute, Jing-De-Zhen 333046, China ; Information School, ZheJiang Textile & Fashion College, NingBo 315211, China ; Gordon Life Science Institute, Belmont, MA 02478, USA.
Biomed Res Int. 2013;2013:701317. doi: 10.1155/2013/701317. Epub 2013 Nov 26.
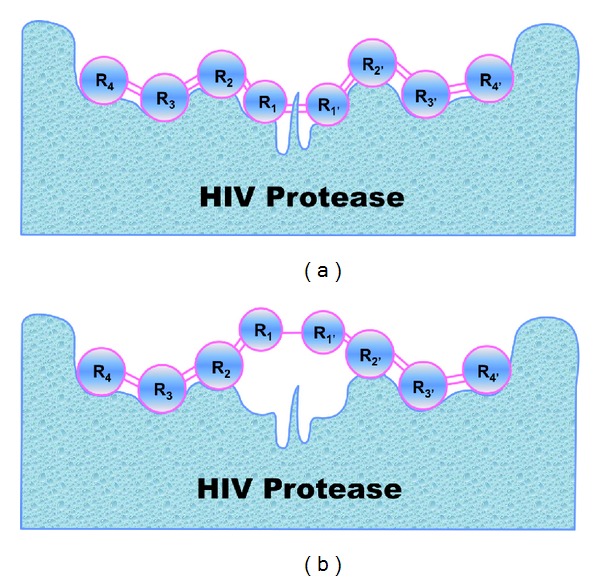
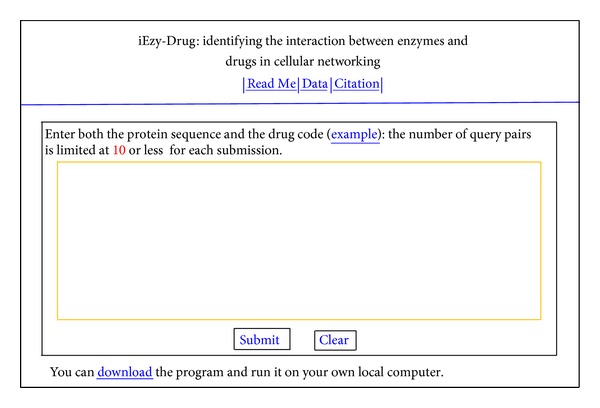
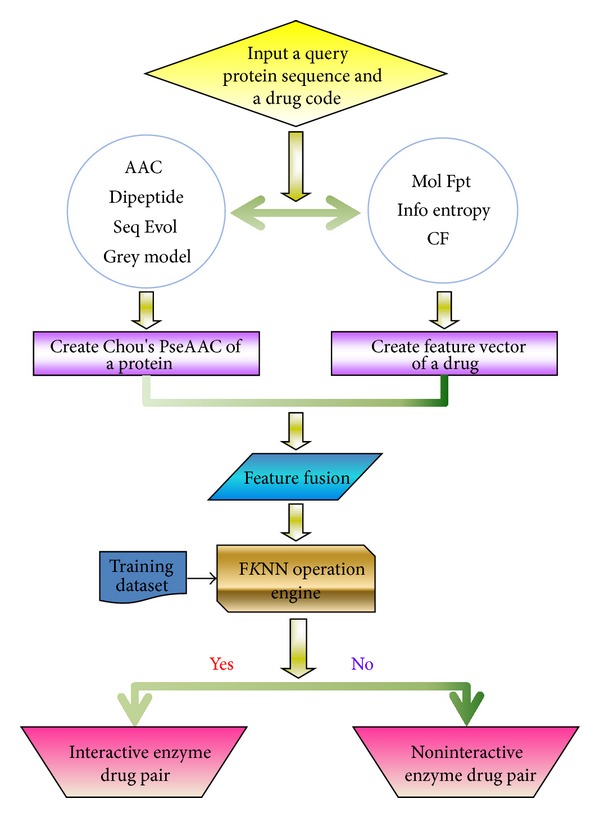
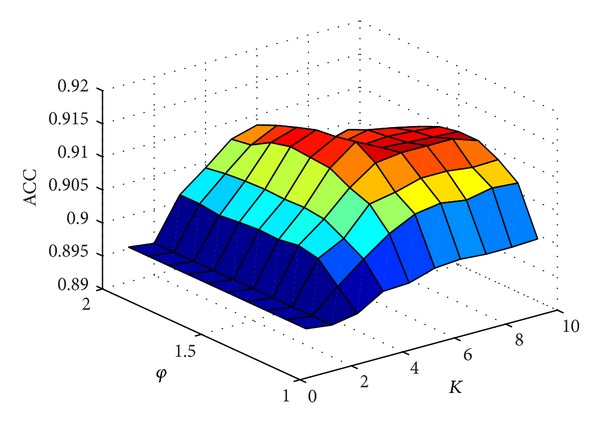
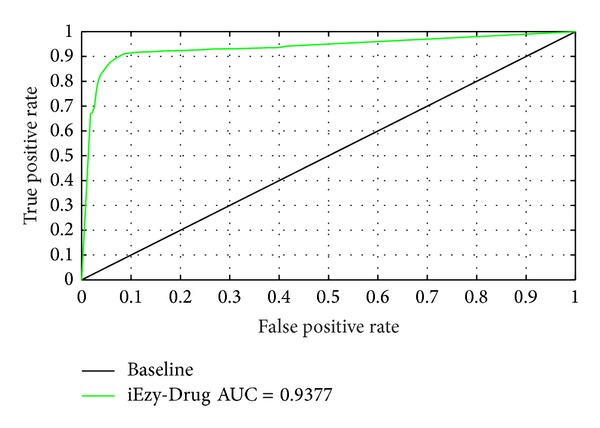
With the features of extremely high selectivity and efficiency in catalyzing almost all the chemical reactions in cells, enzymes play vitally important roles for the life of an organism and hence have become frequent targets for drug design. An essential step in developing drugs by targeting enzymes is to identify drug-enzyme interactions in cells. It is both time-consuming and costly to do this purely by means of experimental techniques alone. Although some computational methods were developed in this regard based on the knowledge of the three-dimensional structure of enzyme, unfortunately their usage is quite limited because three-dimensional structures of many enzymes are still unknown. Here, we reported a sequence-based predictor, called "iEzy-Drug," in which each drug compound was formulated by a molecular fingerprint with 258 feature components, each enzyme by the Chou's pseudo amino acid composition generated via incorporating sequential evolution information and physicochemical features derived from its sequence, and the prediction engine was operated by the fuzzy K-nearest neighbor algorithm. The overall success rate achieved by iEzy-Drug via rigorous cross-validations was about 91%. Moreover, to maximize the convenience for the majority of experimental scientists, a user-friendly web server was established, by which users can easily obtain their desired results.
酶具有极高的选择性和效率,能催化细胞内几乎所有化学反应,对生物体的生命活动起着至关重要的作用,因此成为药物设计的常见靶点。通过靶向酶来开发药物的一个关键步骤是确定细胞内药物与酶的相互作用。单纯依靠实验技术来完成这一工作既耗时又昂贵。尽管基于酶的三维结构知识已开发出一些计算方法,但遗憾的是,由于许多酶的三维结构仍未知,这些方法的应用非常有限。在此,我们报道了一种基于序列的预测工具,名为“iEzy-Drug”,其中每个药物化合物由具有258个特征成分的分子指纹表示,每个酶由通过整合序列进化信息和从其序列衍生的物理化学特征生成的周氏伪氨基酸组成表示,预测引擎由模糊K近邻算法运行。通过严格的交叉验证,iEzy-Drug实现的总体成功率约为91%。此外,为了最大限度地方便大多数实验科学家,我们建立了一个用户友好的网络服务器,用户可以通过它轻松获得他们想要的结果。