Penrod Nadia M, Moore Jason H
Department of Genetics, Geisel School of Medicine at Dartmouth College, HB7937 One Medical Center Dr,, Lebanon, NH 03766, USA.
BMC Syst Biol. 2014 Feb 5;8:12. doi: 10.1186/1752-0509-8-12.
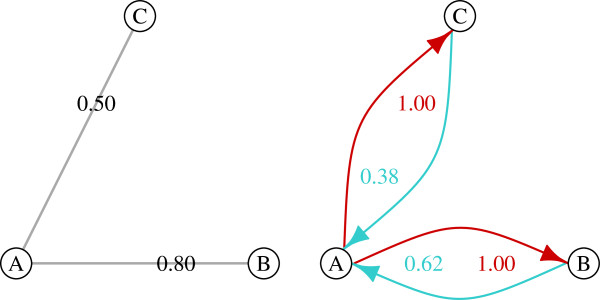
The demand for novel molecularly targeted drugs will continue to rise as we move forward toward the goal of personalizing cancer treatment to the molecular signature of individual tumors. However, the identification of targets and combinations of targets that can be safely and effectively modulated is one of the greatest challenges facing the drug discovery process. A promising approach is to use biological networks to prioritize targets based on their relative positions to one another, a property that affects their ability to maintain network integrity and propagate information-flow. Here, we introduce influence networks and demonstrate how they can be used to generate influence scores as a network-based metric to rank genes as potential drug targets.
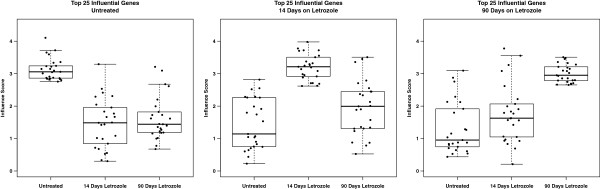
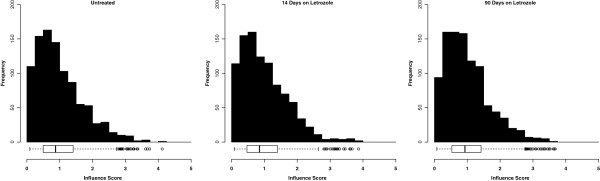
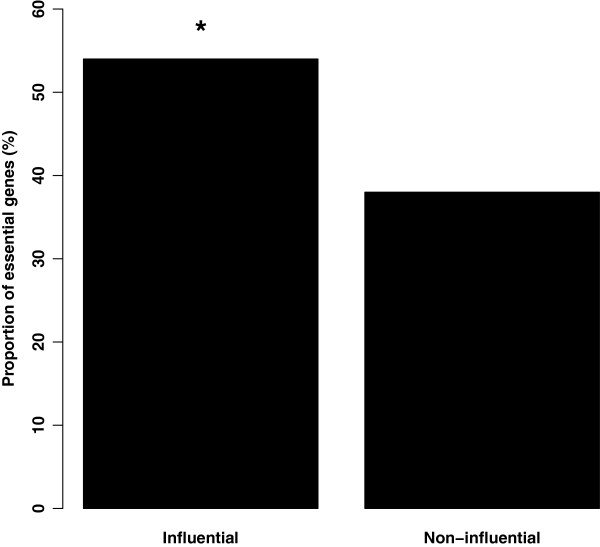
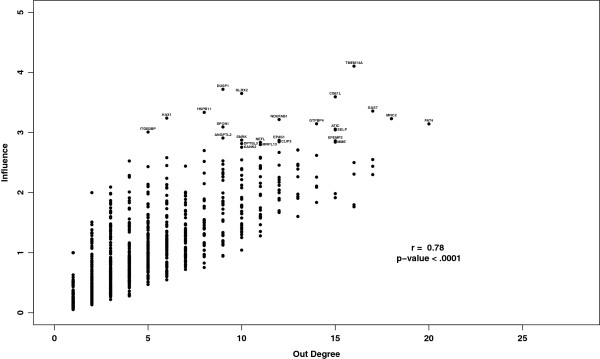
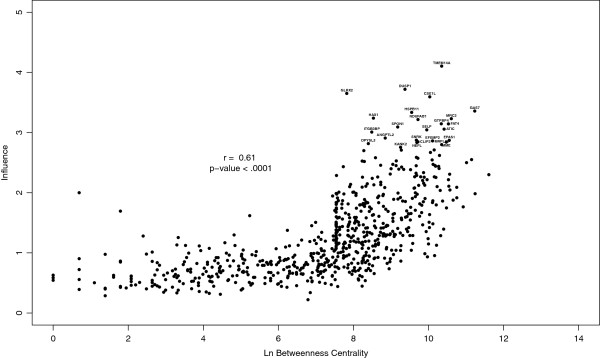
We use this approach to prioritize genes as drug target candidates in a set of ER⁺ breast tumor samples collected during the course of neoadjuvant treatment with the aromatase inhibitor letrozole. We show that influential genes, those with high influence scores, tend to be essential and include a higher proportion of essential genes than those prioritized based on their position (i.e. hubs or bottlenecks) within the same network. Additionally, we show that influential genes represent novel biologically relevant drug targets for the treatment of ER⁺ breast cancers. Moreover, we demonstrate that gene influence differs between untreated tumors and residual tumors that have adapted to drug treatment. In this way, influence scores capture the context-dependent functions of genes and present the opportunity to design combination treatment strategies that take advantage of the tumor adaptation process.
Influence networks efficiently find essential genes as promising drug targets and combinations of targets to inform the development of molecularly targeted drugs and their use.
随着我们朝着根据个体肿瘤的分子特征实现癌症治疗个性化的目标迈进,对新型分子靶向药物的需求将持续上升。然而,确定能够被安全有效地调节的靶点以及靶点组合是药物研发过程中面临的最大挑战之一。一种有前景的方法是利用生物网络,根据靶点彼此之间的相对位置对其进行优先级排序,这种相对位置会影响它们维持网络完整性和传播信息流的能力。在此,我们引入影响网络,并展示如何利用它们生成影响分数,作为一种基于网络的指标来对基因进行排名,以确定其作为潜在药物靶点的可能性。
我们使用这种方法,在一组接受芳香化酶抑制剂来曲唑新辅助治疗过程中收集的雌激素受体阳性(ER⁺)乳腺肿瘤样本中,对作为药物靶点候选的基因进行优先级排序。我们发现,具有高影响分数的有影响的基因往往是必需基因,并且与基于其在同一网络中的位置(即中心节点或瓶颈节点)进行优先级排序的基因相比,它们包含的必需基因比例更高。此外,我们表明有影响的基因代表了治疗ER⁺乳腺癌的新型生物学相关药物靶点。而且,我们证明未治疗肿瘤与已适应药物治疗的残留肿瘤之间的基因影响存在差异。通过这种方式,影响分数捕捉到了基因的上下文依赖性功能,并为设计利用肿瘤适应过程的联合治疗策略提供了机会。
影响网络能够有效地找到作为有前景的药物靶点的必需基因以及靶点组合,为分子靶向药物的开发及其应用提供信息。