Department of Neurobiology and Anatomy, University of Texas Health Science Center at Houston Houston, TX, USA.
Department of Psychology, University of Oregon Eugene, OR, USA.
Front Integr Neurosci. 2014 Mar 28;8:28. doi: 10.3389/fnint.2014.00028. eCollection 2014.
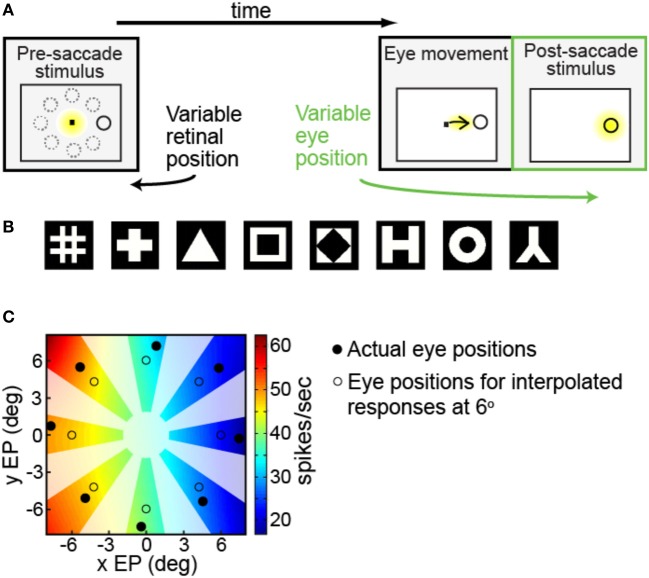
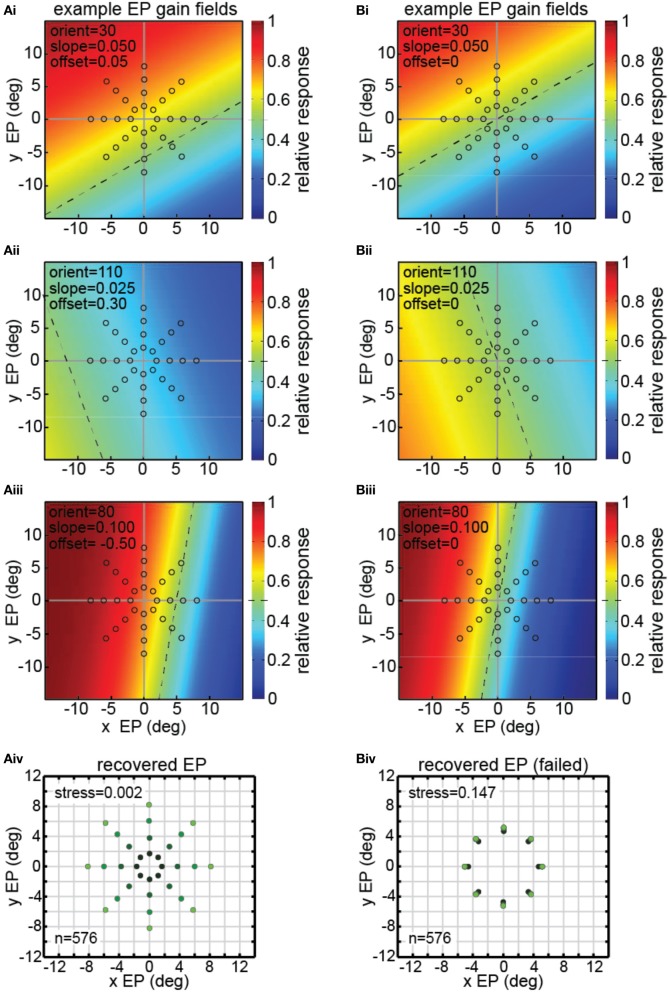
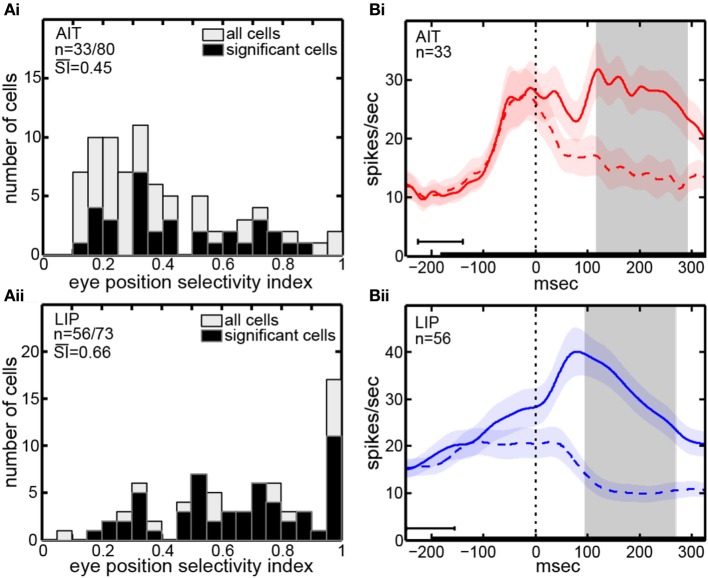
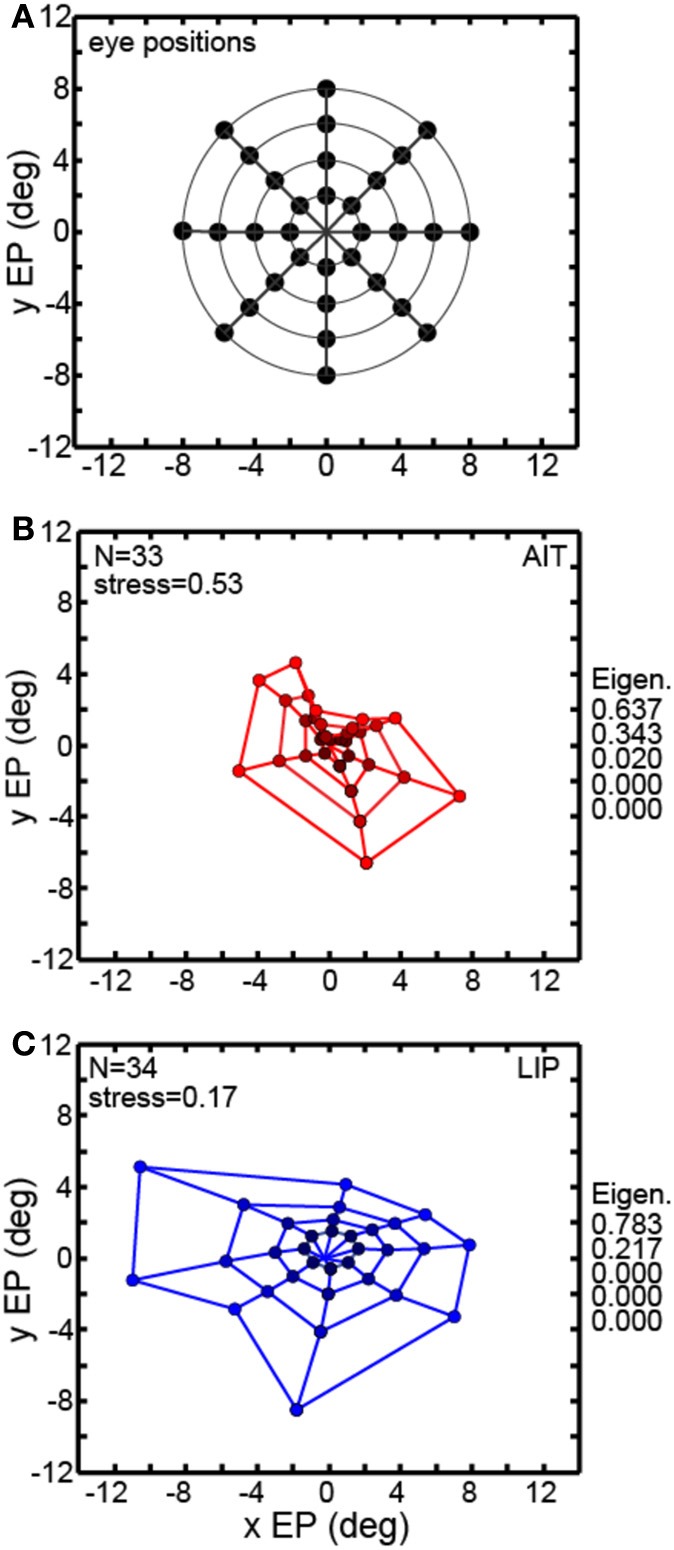
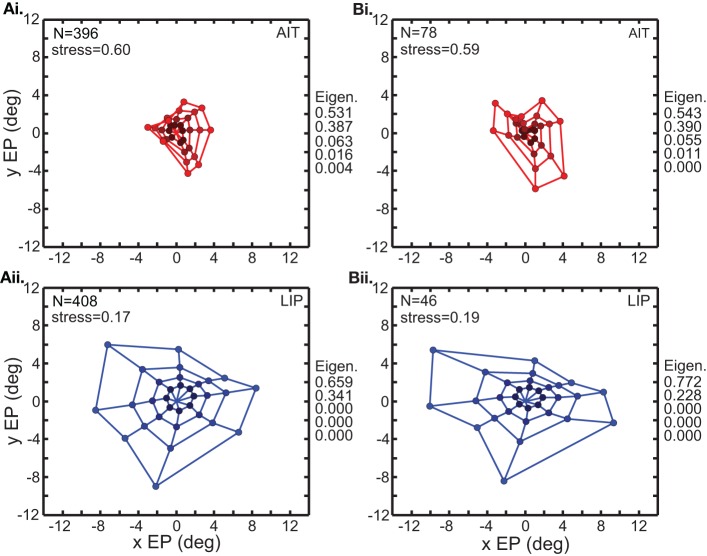
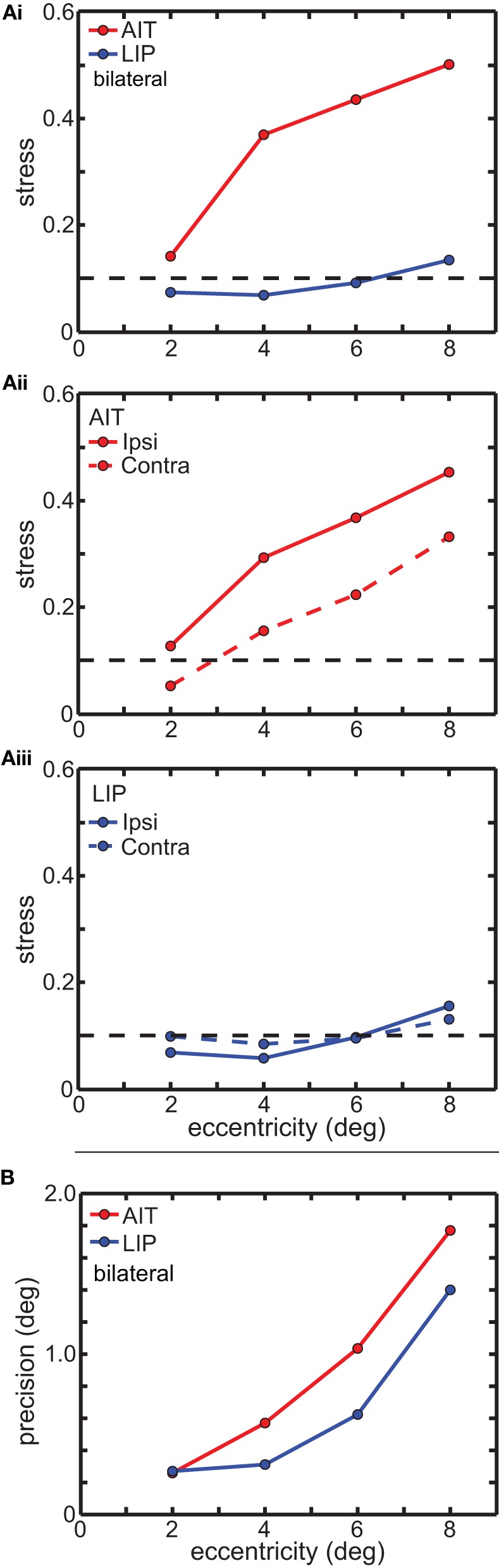
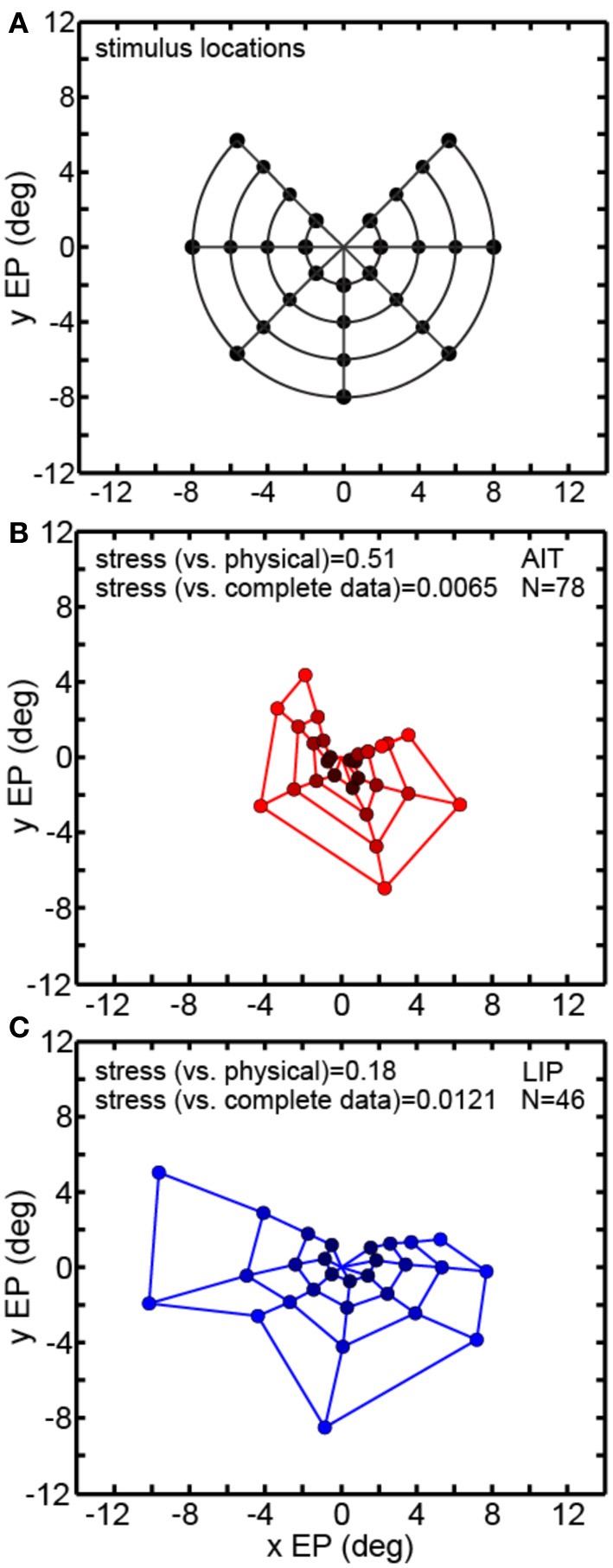
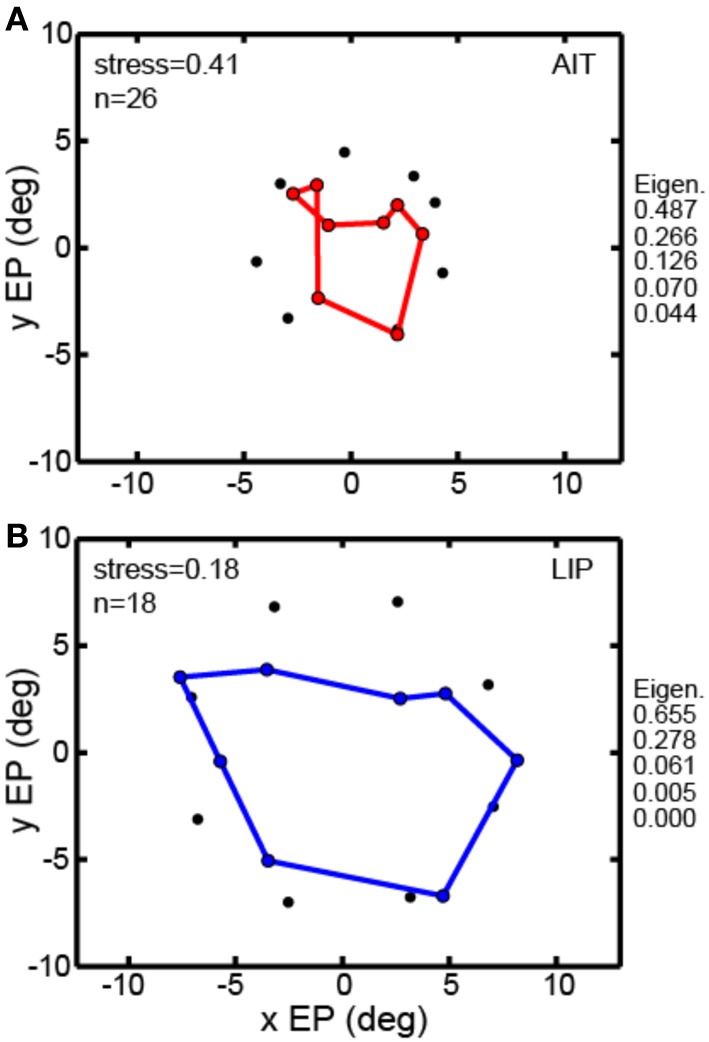
We recorded visual responses while monkeys fixated the same target at different gaze angles, both dorsally (lateral intraparietal cortex, LIP) and ventrally (anterior inferotemporal cortex, AIT). While eye-position modulations occurred in both areas, they were both more frequent and stronger in LIP neurons. We used an intrinsic population decoding technique, multidimensional scaling (MDS), to recover eye positions, equivalent to recovering fixated target locations. We report that eye-position based visual space in LIP was more accurate (i.e., metric). Nevertheless, the AIT spatial representation remained largely topologically correct, perhaps indicative of a categorical spatial representation (i.e., a qualitative description such as "left of" or "above" as opposed to a quantitative, metrically precise description). Additionally, we developed a simple neural model of eye position signals and illustrate that differences in single cell characteristics can influence the ability to recover target position in a population of cells. We demonstrate for the first time that the ventral stream contains sufficient information for constructing an eye-position based spatial representation. Furthermore we demonstrate, in dorsal and ventral streams as well as modeling, that target locations can be extracted directly from eye position signals in cortical visual responses without computing coordinate transforms of visual space.
我们记录了猴子在不同注视角度注视同一目标时的视觉反应,包括背侧(顶内沟外侧部,LIP)和腹侧(前下颞叶皮层,AIT)。虽然眼位调制在两个区域都发生,但 LIP 神经元中的眼位调制更频繁、更强。我们使用了一种内在的群体解码技术,多维尺度(MDS),来恢复眼位,相当于恢复注视目标的位置。我们报告说,LIP 中的基于眼位的视觉空间更准确(即度量)。然而,AIT 的空间表示仍然在很大程度上保持拓扑正确,这可能表明存在类别化的空间表示(即定性描述,如“左”或“上”,而不是定量的、精确的度量描述)。此外,我们开发了一种简单的眼位信号神经模型,并说明单个细胞特征的差异会影响群体细胞中目标位置的恢复能力。我们首次证明,腹侧流包含构建基于眼位的空间表示所需的足够信息。此外,我们在背侧和腹侧流以及建模中证明,在皮质视觉反应中,可以直接从眼位信号中提取目标位置,而无需计算视觉空间的坐标变换。