Department of Molecular and Cellular Biochemistry, University of Kentucky Lexington, KY, USA.
Department of Anatomical Sciences and Neurobiology, University of Louisville Louisville, KY, USA ; Department of Neurological Surgery, Kentucky Spinal Cord Injury Research Center, University of Louisville Louisville, KY, USA.
Front Genet. 2014 Apr 29;5:98. doi: 10.3389/fgene.2014.00098. eCollection 2014.
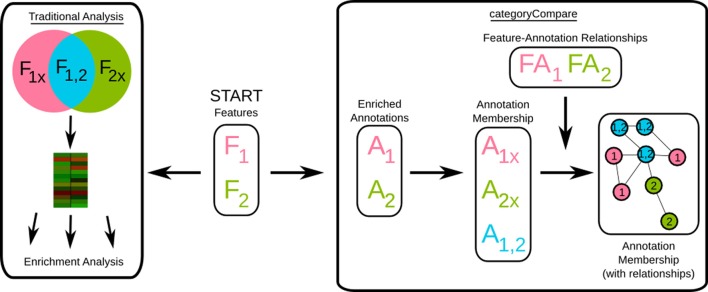
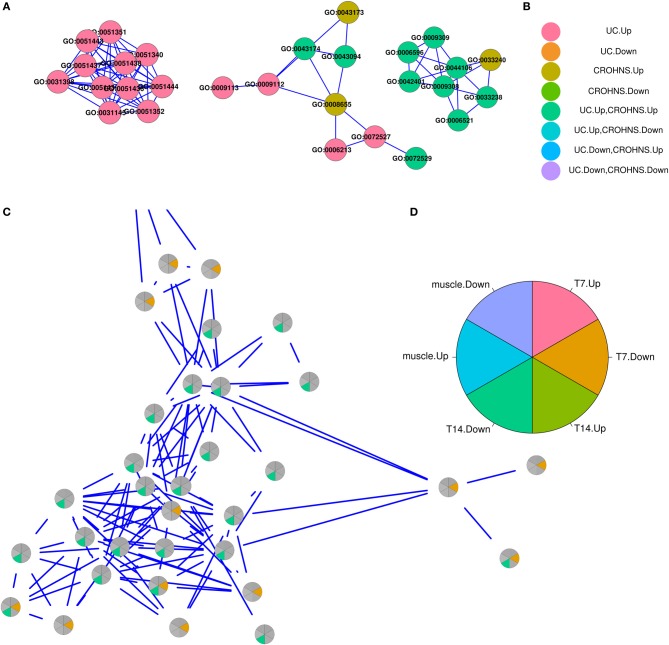
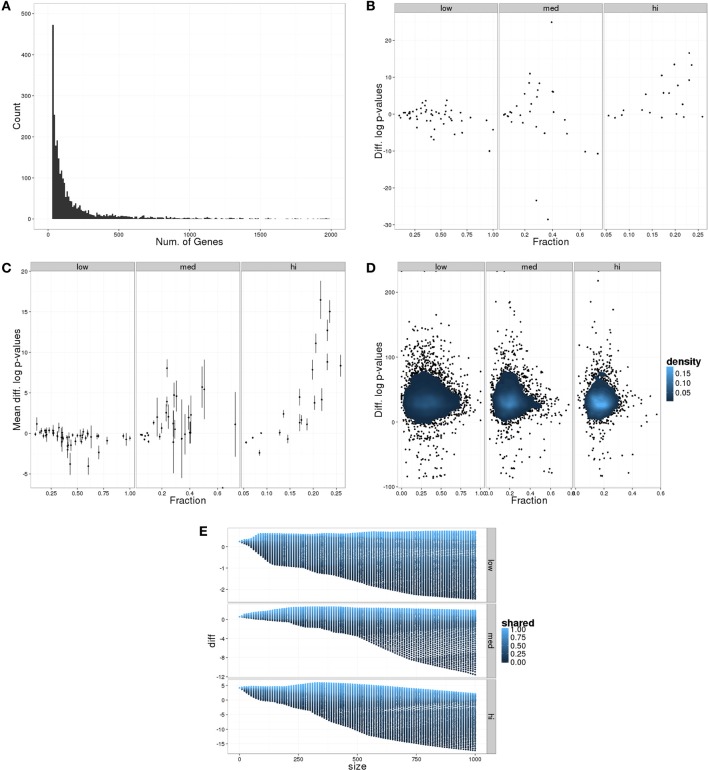
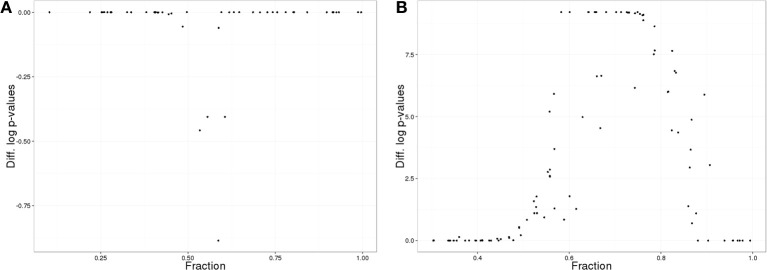
Assessment of high-throughput-omics data initially focuses on relative or raw levels of a particular feature, such as an expression value for a transcript, protein, or metabolite. At a second level, analyses of annotations including known or predicted functions and associations of each individual feature, attempt to distill biological context. Most currently available comparative- and meta-analyses methods are dependent on the availability of identical features across data sets, and concentrate on determining features that are differentially expressed across experiments, some of which may be considered "biomarkers." The heterogeneity of measurement platforms and inherent variability of biological systems confounds the search for robust biomarkers indicative of a particular condition. In many instances, however, multiple data sets show involvement of common biological processes or signaling pathways, even though individual features are not commonly measured or differentially expressed between them. We developed a methodology, categoryCompare, for cross-platform and cross-sample comparison of high-throughput data at the annotation level. We assessed the utility of the approach using hypothetical data, as well as determining similarities and differences in the set of processes in two instances: (1) denervated skin vs. denervated muscle, and (2) colon from Crohn's disease vs. colon from ulcerative colitis (UC). The hypothetical data showed that in many cases comparing annotations gave superior results to comparing only at the gene level. Improved analytical results depended as well on the number of genes included in the annotation term, the amount of noise in relation to the number of genes expressing in unenriched annotation categories, and the specific method in which samples are combined. In the skin vs. muscle denervation comparison, the tissues demonstrated markedly different responses. The Crohn's vs. UC comparison showed gross similarities in inflammatory response in the two diseases, with particular processes specific to each disease.
高通量组学数据的评估最初集中在特定特征的相对或原始水平上,例如转录本、蛋白质或代谢物的表达值。在第二个层次上,对包括已知或预测功能以及每个特征个体的关联的注释的分析,试图提炼生物学背景。目前大多数可用的比较和荟萃分析方法都依赖于数据集之间具有相同特征的可用性,并集中于确定在实验中差异表达的特征,其中一些可能被认为是“生物标志物”。测量平台的异质性和生物系统的固有可变性使寻找指示特定条件的稳健生物标志物变得复杂。然而,在许多情况下,即使个别特征在它们之间没有共同测量或差异表达,多个数据集也显示出常见的生物学过程或信号通路的参与。我们开发了一种名为 categoryCompare 的方法,用于在注释级别上进行高通量数据的跨平台和跨样本比较。我们使用假设数据评估了该方法的实用性,以及在两种情况下确定过程集的相似性和差异:(1)去神经支配的皮肤与去神经支配的肌肉,以及(2)克罗恩病的结肠与溃疡性结肠炎(UC)的结肠。假设数据表明,在许多情况下,比较注释比仅在基因水平上比较结果更好。分析结果的改善还取决于注释中包含的基因数量、与表达在非富集注释类别的基因数量相关的噪声量,以及样本组合的具体方法。在皮肤与肌肉去神经支配的比较中,两种组织表现出明显不同的反应。克罗恩病与 UC 的比较显示出两种疾病中炎症反应的显著相似性,而每种疾病都有特定的过程。