Lun Aaron T L, Smyth Gordon K
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Australia Department of Medical Biology, The University of Melbourne, Parkville, VIC 3010, Australia.
The Walter and Eliza Hall Institute of Medical Research, 1G Royal Parade, Parkville, VIC 3052, Australia Department of Mathematics and Statistics, The University of Melbourne, Parkville, VIC 3010, Australia
Nucleic Acids Res. 2014 Jun;42(11):e95. doi: 10.1093/nar/gku351. Epub 2014 May 22.
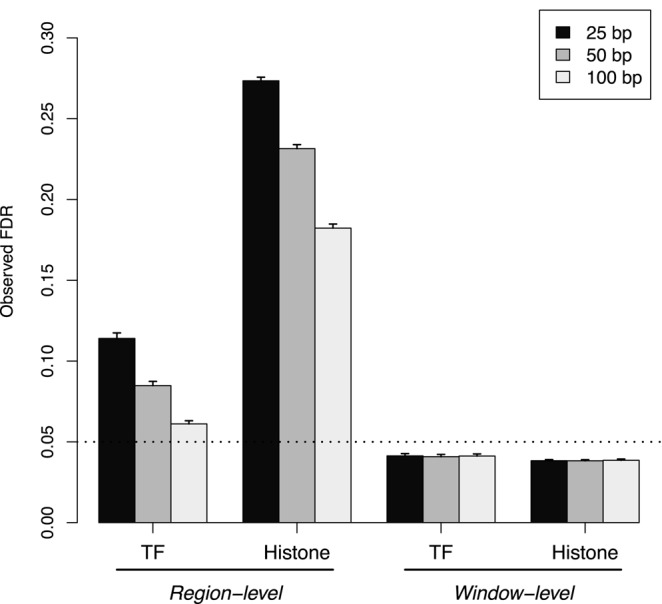
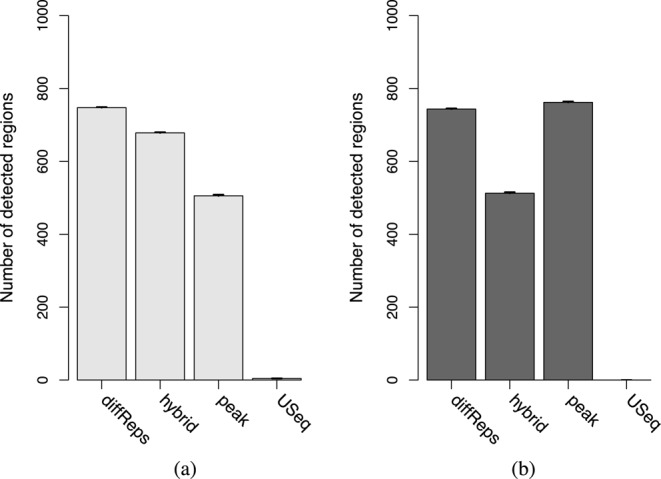
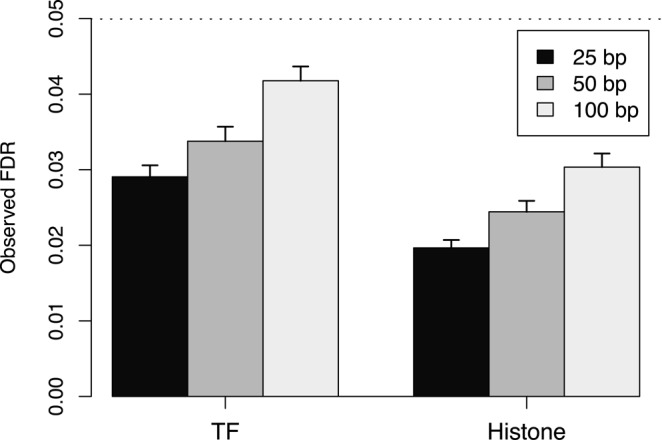
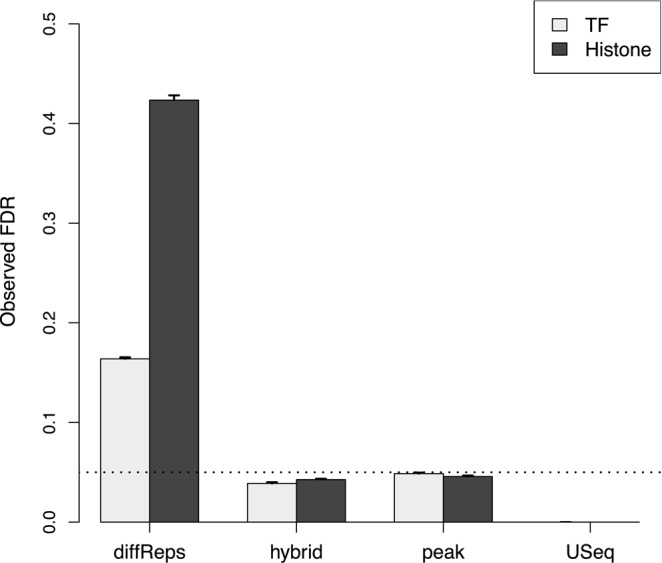
A common aim in ChIP-seq experiments is to identify changes in protein binding patterns between conditions, i.e. differential binding. A number of peak- and window-based strategies have been developed to detect differential binding when the regions of interest are not known in advance. However, careful consideration of error control is needed when applying these methods. Peak-based approaches use the same data set to define peaks and to detect differential binding. Done improperly, this can result in loss of type I error control. For window-based methods, controlling the false discovery rate over all detected windows does not guarantee control across all detected regions. Misinterpreting the former as the latter can result in unexpected liberalness. Here, several solutions are presented to maintain error control for these de novo counting strategies. For peak-based methods, peak calling should be performed on pooled libraries prior to the statistical analysis. For window-based methods, a hybrid approach using Simes' method is proposed to maintain control of the false discovery rate across regions. More generally, the relative advantages of peak- and window-based strategies are explored using a range of simulated and real data sets. Implementations of both strategies also compare favourably to existing programs for differential binding analyses.
染色质免疫沉淀测序(ChIP-seq)实验的一个常见目标是识别不同条件下蛋白质结合模式的变化,即差异结合。当预先不知道感兴趣的区域时,已经开发了许多基于峰和窗口的策略来检测差异结合。然而,在应用这些方法时需要仔细考虑误差控制。基于峰的方法使用相同的数据集来定义峰并检测差异结合。如果操作不当,这可能导致第一类错误控制的丧失。对于基于窗口的方法,控制所有检测到的窗口中的错误发现率并不能保证在所有检测到的区域中都能得到控制。将前者误解为后者可能会导致意外的宽松。在这里,提出了几种解决方案来维持这些从头计数策略的误差控制。对于基于峰的方法,在统计分析之前应在合并的文库上进行峰识别。对于基于窗口的方法,提出了一种使用西姆斯方法的混合方法来维持跨区域错误发现率的控制。更一般地说,使用一系列模拟和真实数据集探索了基于峰和窗口的策略的相对优势。这两种策略的实现与现有的差异结合分析程序相比也具有优势。