Guillera-Arroita Gurutzeta, Lahoz-Monfort José J, MacKenzie Darryl I, Wintle Brendan A, McCarthy Michael A
School of Botany, University of Melbourne, Parkville, Victoria, Australia.
Proteus Wildlife Research Consultants, Outram, New Zealand.
PLoS One. 2014 Jul 30;9(7):e99571. doi: 10.1371/journal.pone.0099571. eCollection 2014.
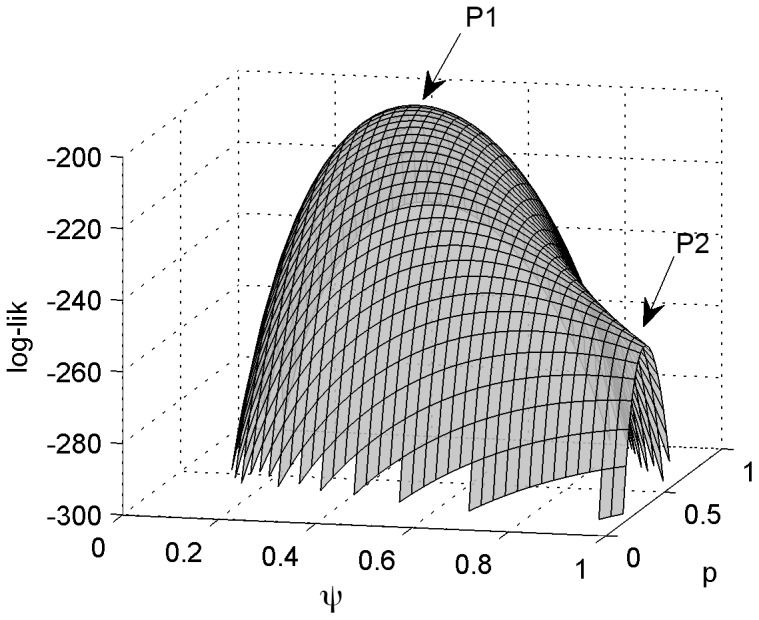
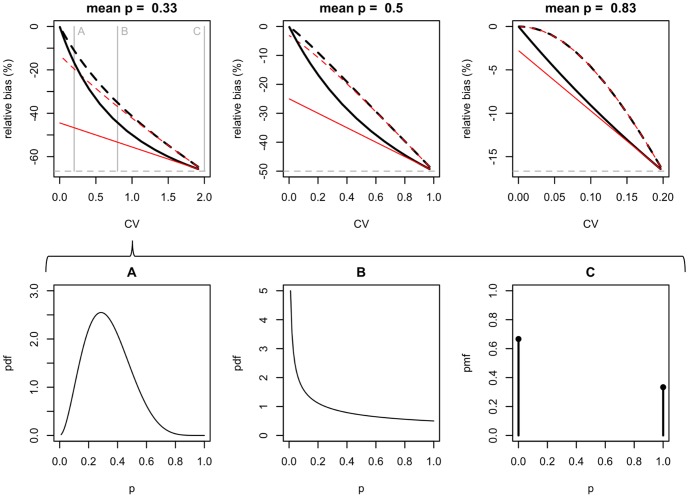
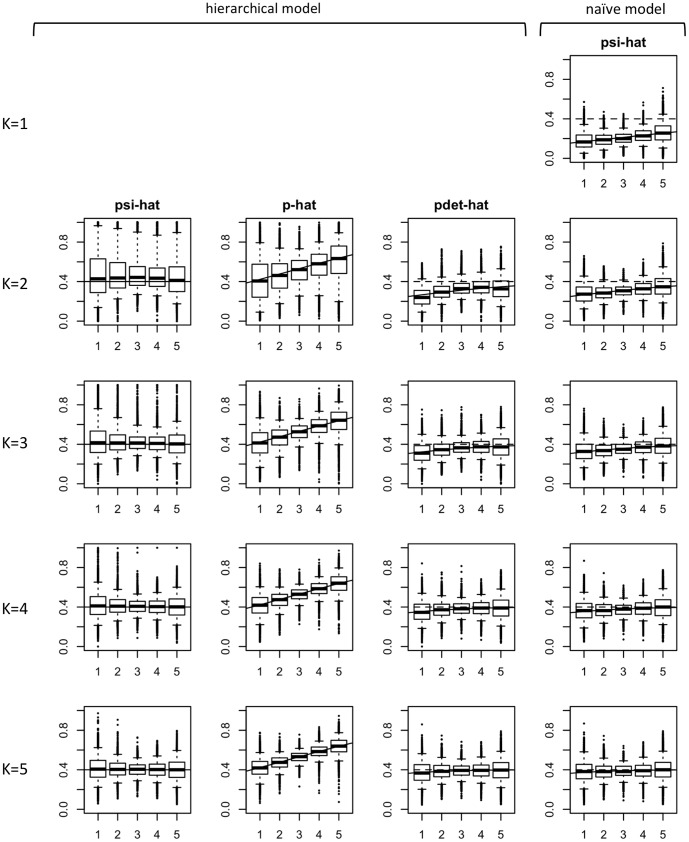
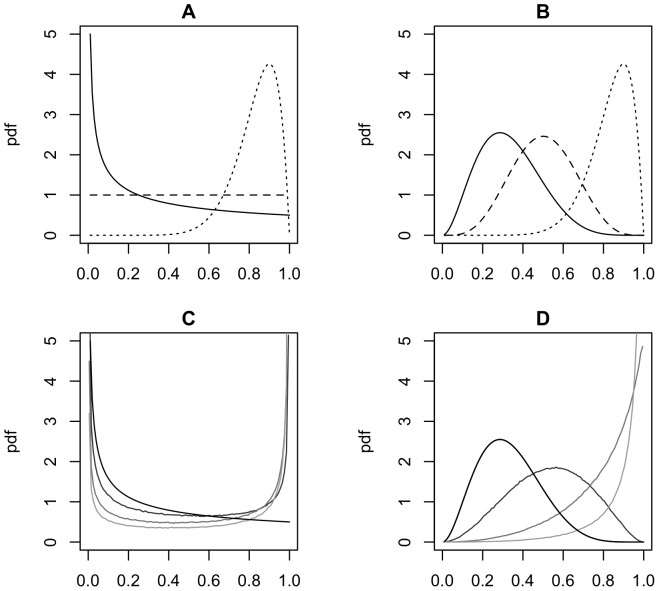
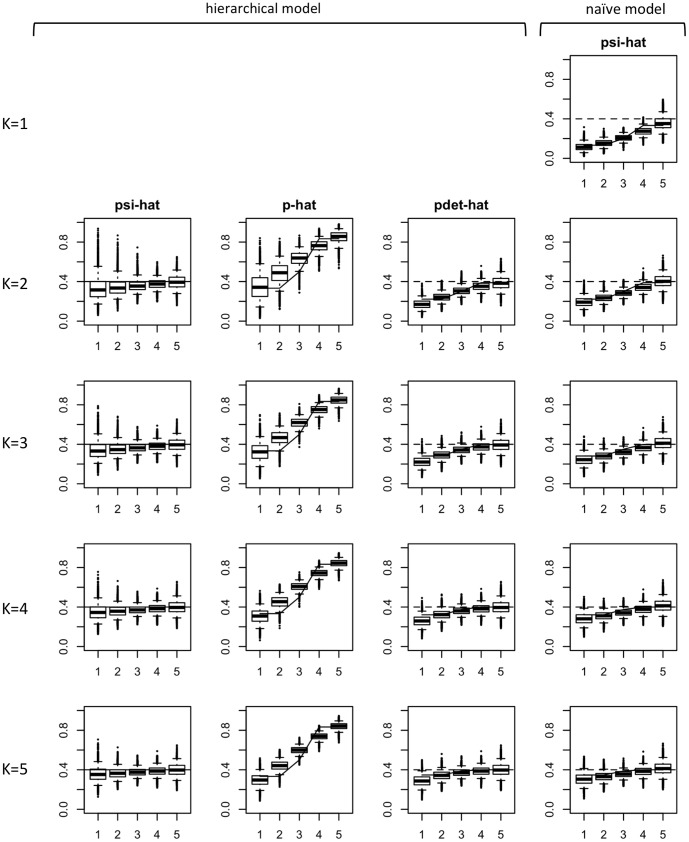
In a recent paper, Welsh, Lindenmayer and Donnelly (WLD) question the usefulness of models that estimate species occupancy while accounting for detectability. WLD claim that these models are difficult to fit and argue that disregarding detectability can be better than trying to adjust for it. We think that this conclusion and subsequent recommendations are not well founded and may negatively impact the quality of statistical inference in ecology and related management decisions. Here we respond to WLD's claims, evaluating in detail their arguments, using simulations and/or theory to support our points. In particular, WLD argue that both disregarding and accounting for imperfect detection lead to the same estimator performance regardless of sample size when detectability is a function of abundance. We show that this, the key result of their paper, only holds for cases of extreme heterogeneity like the single scenario they considered. Our results illustrate the dangers of disregarding imperfect detection. When ignored, occupancy and detection are confounded: the same naïve occupancy estimates can be obtained for very different true levels of occupancy so the size of the bias is unknowable. Hierarchical occupancy models separate occupancy and detection, and imprecise estimates simply indicate that more data are required for robust inference about the system in question. As for any statistical method, when underlying assumptions of simple hierarchical models are violated, their reliability is reduced. Resorting in those instances where hierarchical occupancy models do no perform well to the naïve occupancy estimator does not provide a satisfactory solution. The aim should instead be to achieve better estimation, by minimizing the effect of these issues during design, data collection and analysis, ensuring that the right amount of data is collected and model assumptions are met, considering model extensions where appropriate.
在最近的一篇论文中,威尔士、林登迈耶和唐纳利(WLD)对在考虑可探测性的情况下估计物种占有率的模型的实用性提出了质疑。WLD声称这些模型很难拟合,并认为忽略可探测性可能比试图对其进行调整更好。我们认为这一结论及后续建议没有充分依据,可能会对生态学中的统计推断质量以及相关管理决策产生负面影响。在此,我们回应WLD的观点,详细评估他们的论点,使用模拟和/或理论来支持我们的观点。特别是,WLD认为当可探测性是丰度的函数时,无论样本量大小,忽略和考虑不完美探测都会导致相同的估计器性能。我们表明,他们论文的这一关键结果仅适用于他们所考虑的单一极端异质性情况。我们的结果说明了忽略不完美探测的危险性。当被忽略时,占有率和探测会相互混淆:对于非常不同的真实占有率水平,可以得到相同的简单占有率估计值,因此偏差的大小是不可知的。分层占有率模型将占有率和探测区分开来,不精确的估计仅仅表明需要更多数据才能对相关系统进行可靠推断。对于任何统计方法,当简单分层模型的基本假设被违反时,其可靠性就会降低。在分层占有率模型表现不佳的情况下求助于简单占有率估计器并不能提供令人满意的解决方案。相反,目标应该是通过在设计、数据收集和分析过程中尽量减少这些问题的影响来实现更好的估计,确保收集到适量的数据并满足模型假设,在适当的时候考虑模型扩展。