Drenos Fotios, Grossi Enzo, Buscema Massimo, Humphries Steve E
Centre for Cardiovascular Genetics, Institute of Cardiovascular Science, University College London, London, United Kingdom; MRC Integrative Epidemiology Unit, School of Social and Community Medicine, University of Bristol, Bristol, United Kingdom.
Medical Department-Bracco Pharmaceuticals, San Donato Milanese, Italy; current affiliation: Villa Santa Maria Institute, Tavernerio, Italy; Semeion Research Center of Sciences of Communication, Rome, Italy.
PLoS One. 2015 May 7;10(5):e0125876. doi: 10.1371/journal.pone.0125876. eCollection 2015.
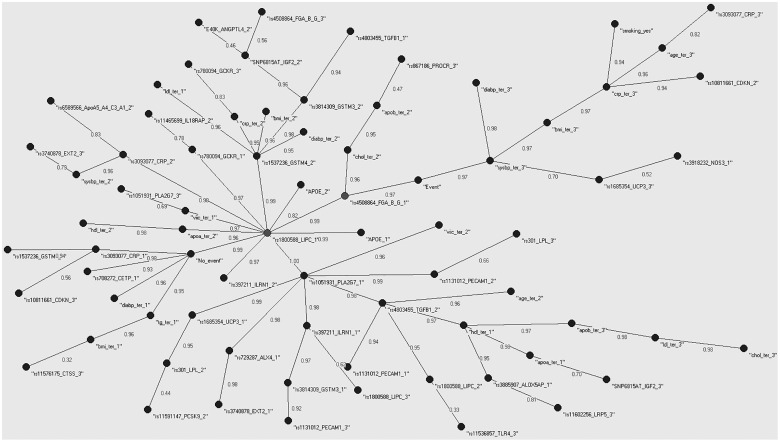
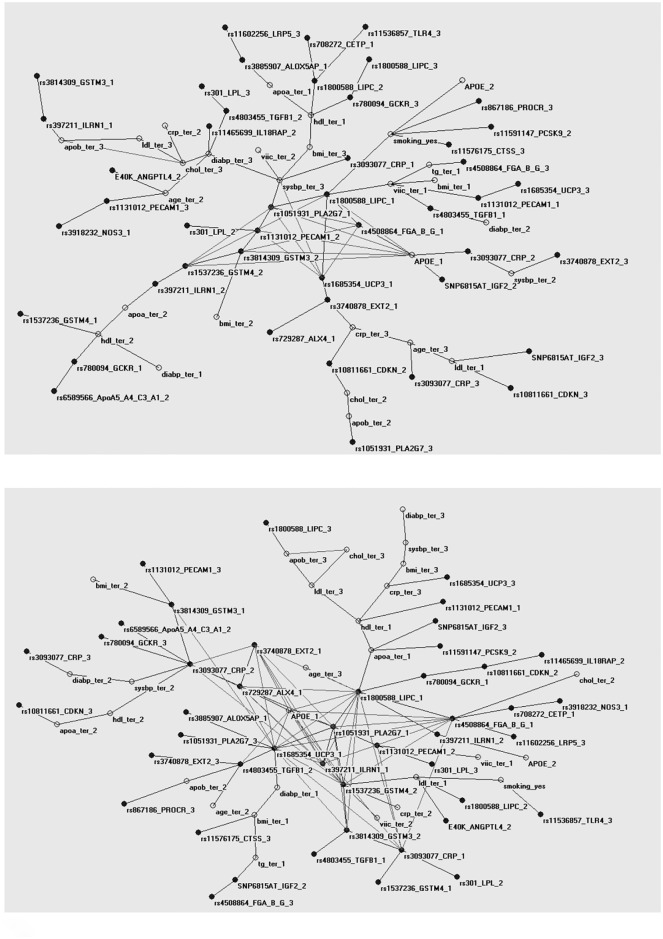
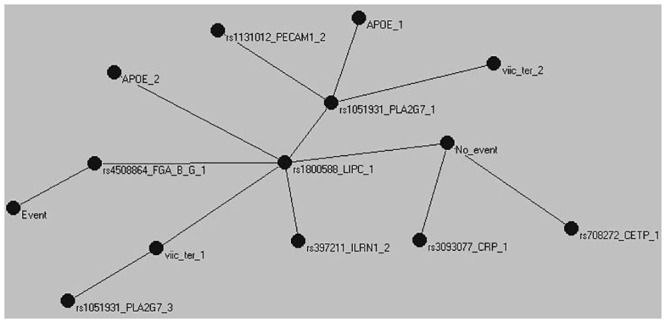
We present the use of innovative machine learning techniques in the understanding of Coronary Heart Disease (CHD) through intermediate traits, as an example of the use of this class of methods as a first step towards a systems epidemiology approach of complex diseases genetics. Using a sample of 252 middle-aged men, of which 102 had a CHD event in 10 years follow-up, we applied machine learning algorithms for the selection of CHD intermediate phenotypes, established markers, risk factors, and their previously associated genetic polymorphisms, and constructed a map of relationships between the selected variables. Of the 52 variables considered, 42 were retained after selection of the most informative variables for CHD. The constructed map suggests that most selected variables were related to CHD in a context dependent manner while only a small number of variables were related to a specific outcome. We also observed that loss of complexity in the network was linked to a future CHD event. We propose that novel, non-linear, and integrative epidemiological approaches are required to combine all available information, in order to truly translate the new advances in medical sciences to gains in preventive measures and patients care.
我们展示了如何通过中间性状利用创新的机器学习技术来理解冠心病(CHD),以此作为将此类方法用作迈向复杂疾病遗传学系统流行病学方法的第一步的示例。我们使用了252名中年男性的样本,其中102人在10年随访中有冠心病事件发生,我们应用机器学习算法来选择冠心病中间表型、既定标志物、危险因素及其先前相关的基因多态性,并构建所选变量之间的关系图。在所考虑的52个变量中,在选择了对冠心病最具信息性的变量后,保留了42个。构建的关系图表明,大多数所选变量以依赖于背景的方式与冠心病相关,而只有少数变量与特定结果相关。我们还观察到网络复杂性的丧失与未来的冠心病事件有关。我们建议需要新颖、非线性和综合的流行病学方法来整合所有可用信息,以便真正将医学科学的新进展转化为预防措施和患者护理方面的收益。