He Zhesi, Cheng Feng, Li Yi, Wang Xiaowu, Parkin Isobel A P, Chalhoub Boulos, Liu Shengyi, Bancroft Ian
Department of Biology, University of York, Heslington, York YO10 5DD, UK.
Institute of Vegetables and Flowers, Chinese Academy of Agricultural Sciences, Beijing 100081, China.
Data Brief. 2015 Jul 2;4:357-62. doi: 10.1016/j.dib.2015.06.016. eCollection 2015 Sep.
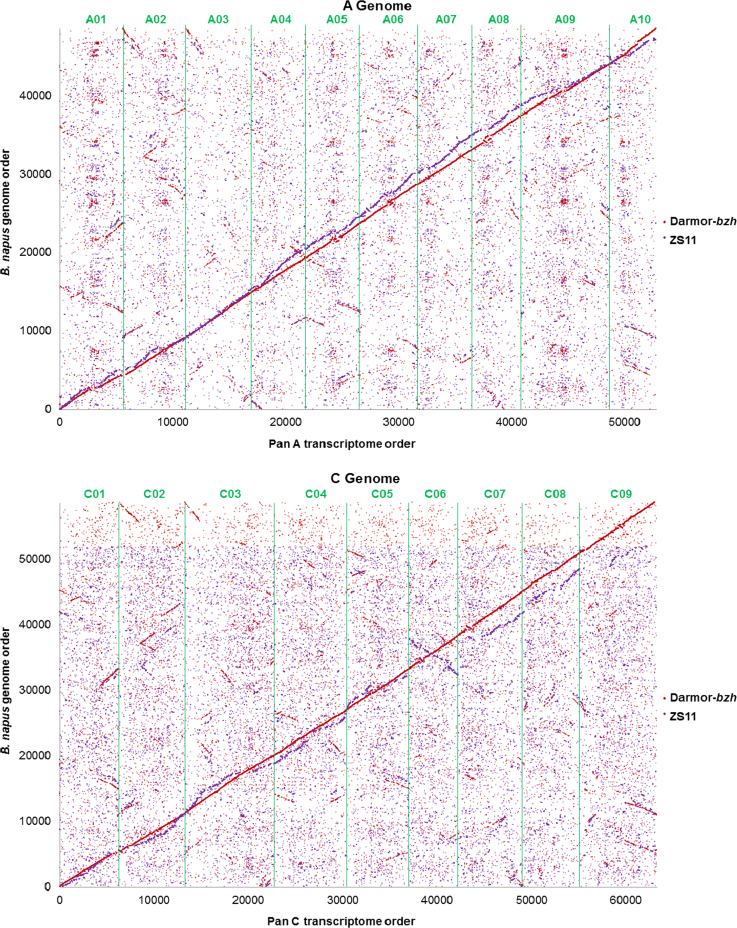
This data article reports the establishment of the first pan-transcriptome resources for the Brassica A and C genomes. These were developed using existing coding DNA sequence (CDS) gene models from the now-published Brassica oleracea TO1000 and Brassica napus Darmor-bzh genome sequence assemblies representing the chromosomes of these species, along with preliminary CDS models from an updated Brassica rapa Chiifu genome sequence assembly. The B. rapa genome sequence scaffolds required splitting and re-ordering to match the expected genome organisation based on a high density SNP linkage map, but the B. oleracea assembly was used unchanged. The resulting B. rapa (A genome) pseudomolecules contained 47,656 ordered CDS models and the B. oleracea (C genome) pseudomolecules contained 54,766 ordered CDS models. Interpolation of B. napus CDS models not already represented by orthologues resulted in 52,790 and 63,308 ordered CDS models in the A and C pan-transcriptomes, an increase of 13,676 overall. Comparison of the organisation of this resource with publicly available genome sequences for B. napus showed excellent consistency for the B. napus Darmor-bzh resource, but more breakdown of collinearity for the B. napus ZS11 resource. CDS datasets comprising the pan-transcriptomes are available with this article (B. rapa) or from public repositories (B. oleracea and B. napus).
本数据文章报道了首个甘蓝型油菜A和C基因组的泛转录组资源的建立。这些资源是利用现已发表的代表这些物种染色体的甘蓝型油菜TO1000和甘蓝型油菜Darmor-bzh基因组序列组装中的现有编码DNA序列(CDS)基因模型,以及来自更新的白菜型油菜Chiifu基因组序列组装的初步CDS模型开发而成。白菜型油菜基因组序列支架需要进行拆分和重新排序,以匹配基于高密度SNP连锁图谱的预期基因组组织,但甘蓝型油菜的组装未作改动。由此得到的白菜型油菜(A基因组)假分子包含47,656个有序CDS模型,甘蓝型油菜(C基因组)假分子包含54,766个有序CDS模型。对甘蓝型油菜中尚未由直系同源物代表的CDS模型进行内插,在A和C泛转录组中分别产生了52,790和63,308个有序CDS模型,总体增加了13,676个。将该资源的组织与公开可用的甘蓝型油菜基因组序列进行比较,结果表明甘蓝型油菜Darmor-bzh资源具有出色的一致性,但甘蓝型油菜ZS11资源的共线性更多地出现了断裂。包含泛转录组的CDS数据集可随本文一同获取(白菜型油菜),或从公共数据库获取(甘蓝型油菜和甘蓝型油菜)。