Nienałtowski Karol, Włodarczyk Michał, Lipniacki Tomasz, Komorowski Michał
Institute of Fundamental Technological Research, Polish Academy of Sciences, Warsaw, Poland.
Faculty of Mathematics Informatics and Mechanics, University of Warsaw, Warsaw, Poland.
BMC Syst Biol. 2015 Sep 29;9:65. doi: 10.1186/s12918-015-0205-8.
Compared to engineering or physics problems, dynamical models in quantitative biology typically depend on a relatively large number of parameters. Progress in developing mathematics to manipulate such multi-parameter models and so enable their efficient interplay with experiments has been slow. Existing solutions are significantly limited by model size.
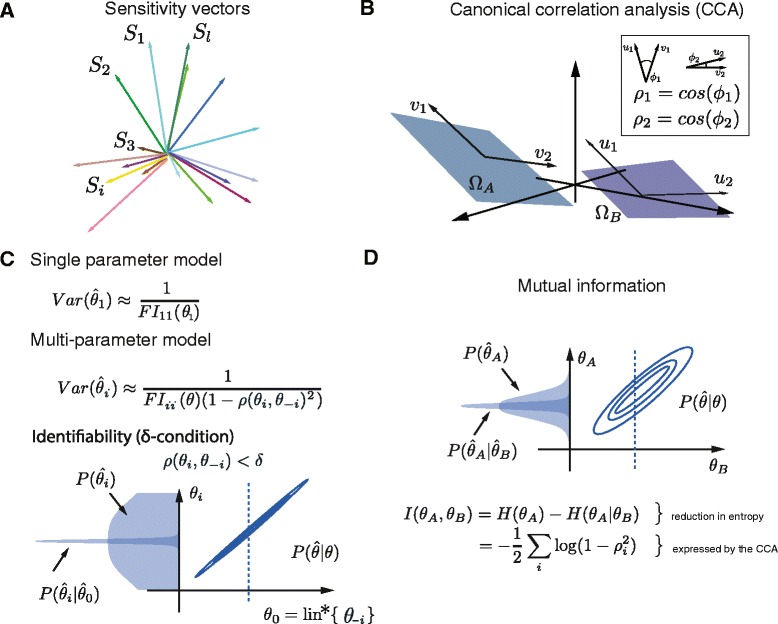
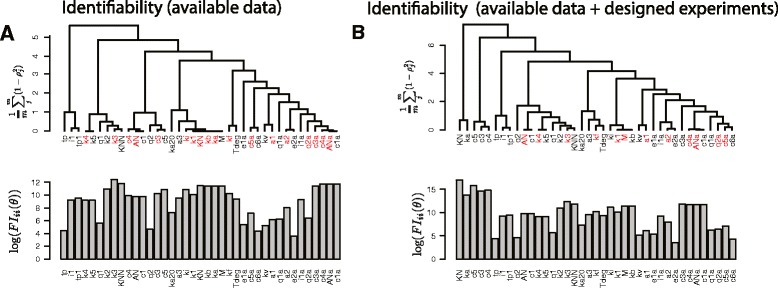
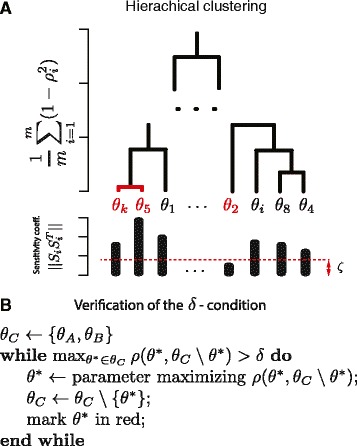
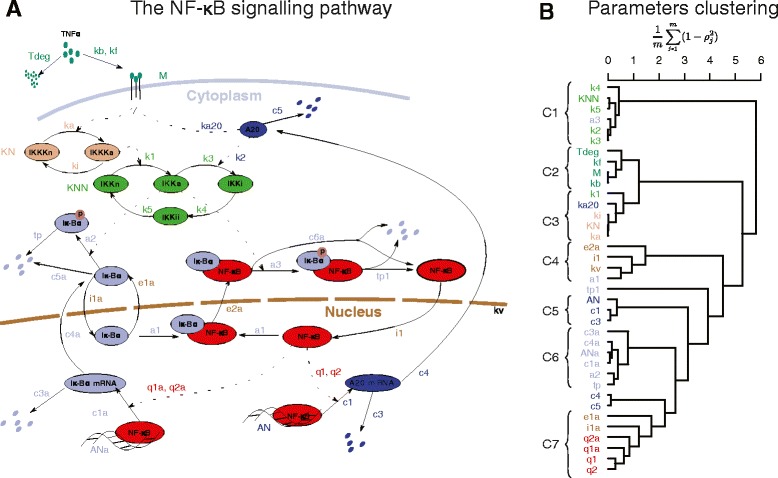
In order to simplify analysis of multi-parameter models a method for clustering of model parameters is proposed. It is based on a derived statistically meaningful measure of similarity between groups of parameters. The measure quantifies to what extend changes in values of some parameters can be compensated by changes in values of other parameters. The proposed methodology provides a natural mathematical language to precisely communicate and visualise effects resulting from compensatory changes in values of parameters. As a results, a relevant insight into identifiability analysis and experimental planning can be obtained. Analysis of NF-κB and MAPK pathway models shows that highly compensative parameters constitute clusters consistent with the network topology. The method applied to examine an exceptionally rich set of published experiments on the NF-κB dynamics reveals that the experiments jointly ensure identifiability of only 60% of model parameters. The method indicates which further experiments should be performed in order to increase the number of identifiable parameters.
We currently lack methods that simplify broadly understood analysis of multi-parameter models. The introduced tools depict mutually compensative effects between parameters to provide insight regarding role of individual parameters, identifiability and experimental design. The method can also find applications in related methodological areas of model simplification and parameters estimation.
与工程学或物理学问题相比,定量生物学中的动力学模型通常依赖于相对大量的参数。在发展数学方法以处理此类多参数模型并使其能与实验有效相互作用方面进展缓慢。现有解决方案受到模型规模的显著限制。
为了简化多参数模型的分析,提出了一种模型参数聚类方法。它基于一种导出的参数组间具有统计意义的相似性度量。该度量量化了某些参数值的变化在何种程度上可由其他参数值的变化来补偿。所提出的方法提供了一种自然的数学语言,用于精确传达和可视化参数值补偿性变化所产生的效应。结果,可以获得对可识别性分析和实验规划的相关见解。对NF-κB和MAPK信号通路模型的分析表明,高度补偿性的参数构成了与网络拓扑一致的聚类。应用该方法检查一组关于NF-κB动力学的极为丰富的已发表实验发现,这些实验共同仅能确保60%的模型参数可识别。该方法指出了为增加可识别参数的数量应进一步开展哪些实验。
我们目前缺乏能简化对多参数模型广义分析的方法。所引入的工具描述了参数之间的相互补偿效应,以提供关于单个参数的作用、可识别性和实验设计的见解。该方法还可在模型简化和参数估计等相关方法领域找到应用。