Masuch Thorsten, Kusnezowa Anna, Nilewski Sebastian, Bautista José T, Kourist Robert, Leichert Lars I
Department of Microbial Biochemistry, Institute of Biochemistry and Pathobiochemistry, Ruhr University Bochum Bochum, Germany.
Junior Research Group for Microbial Biotechnology - Department for Biology and Biotechnology, Ruhr University Bochum Bochum, Germany.
Front Microbiol. 2015 Oct 13;6:1110. doi: 10.3389/fmicb.2015.01110. eCollection 2015.
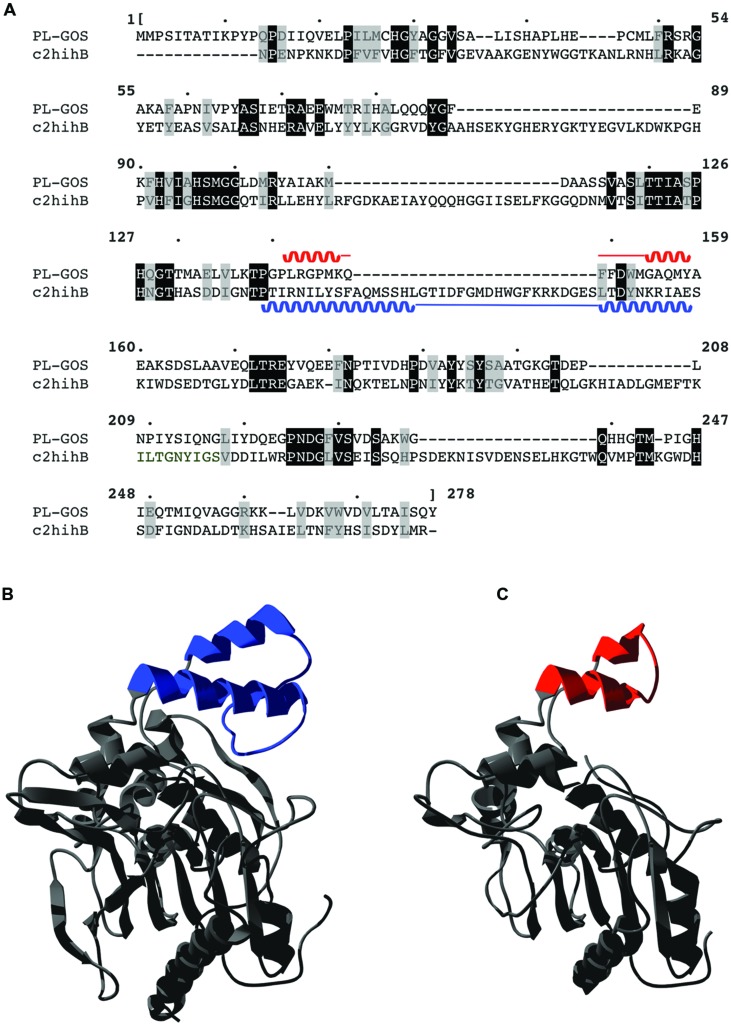
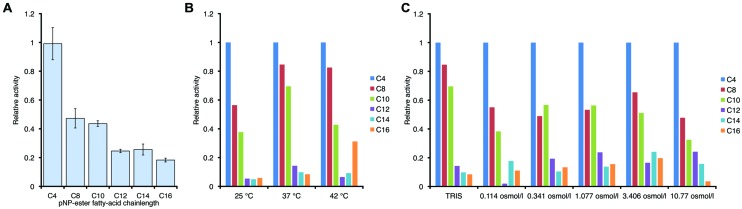
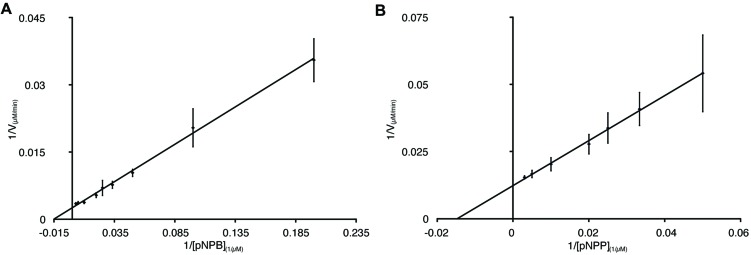
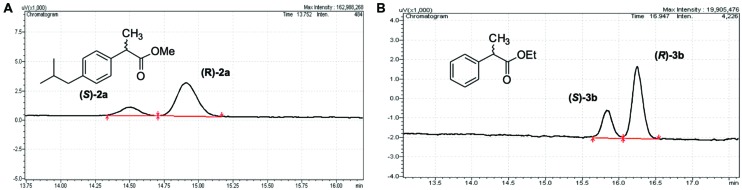
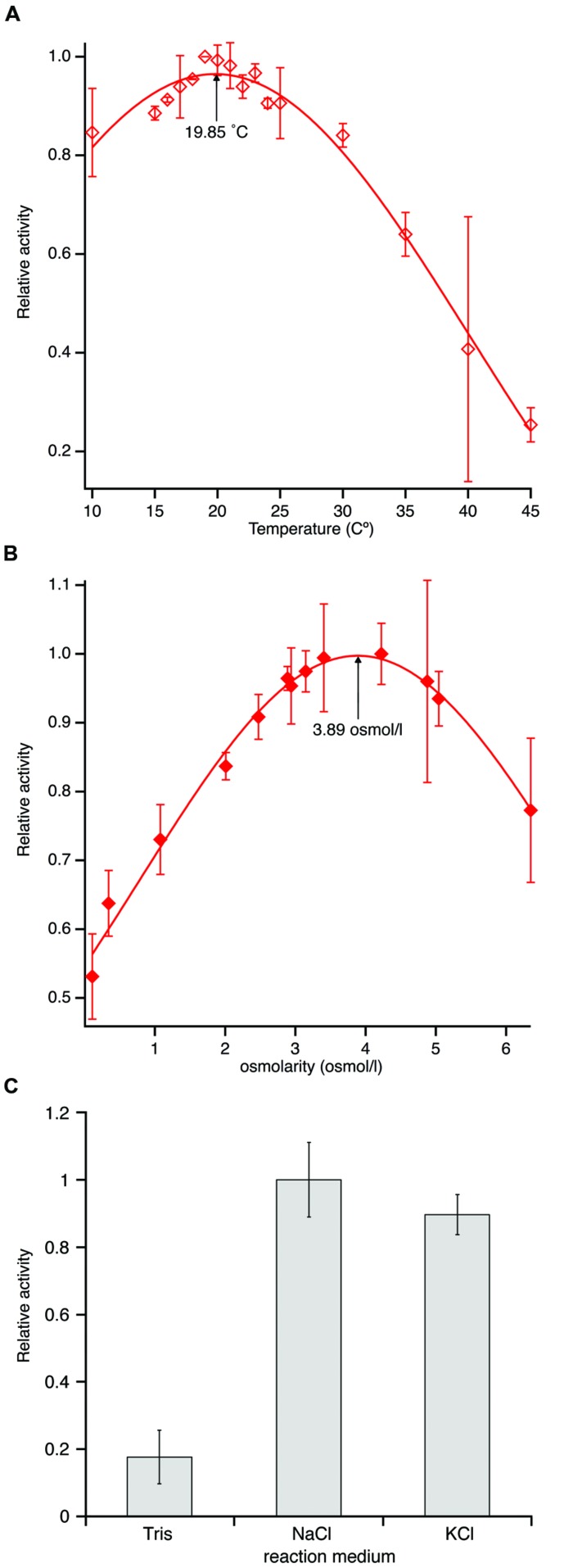
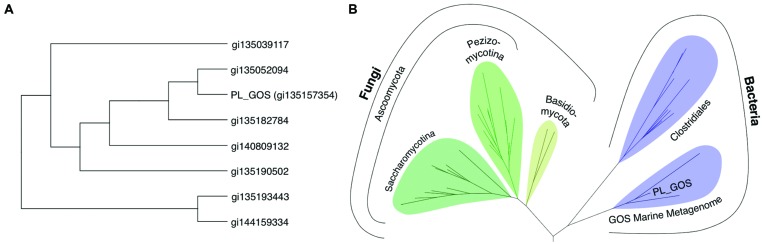
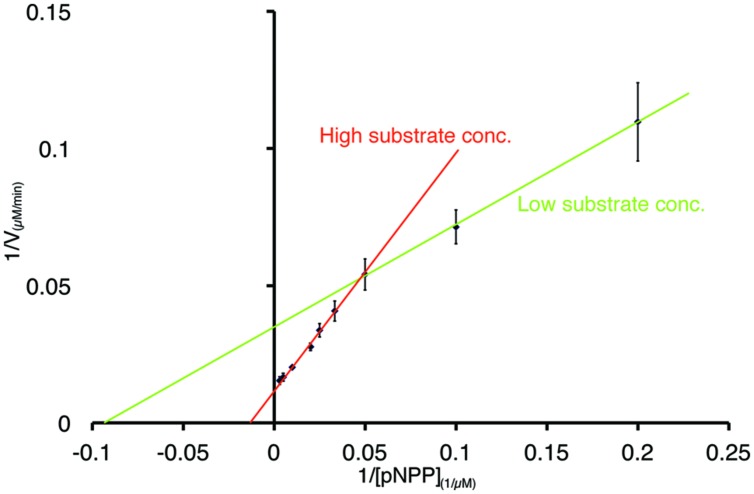
The majority of protein sequence data published today is of metagenomic origin. However, our ability to assign functions to these sequences is often hampered by our general inability to cultivate the larger part of microbial species and the sheer amount of sequence data generated in these projects. Here we present a combination of bioinformatics, synthetic biology, and Escherichia coli genetics to discover biocatalysts in metagenomic datasets. We created a subset of the Global Ocean Sampling dataset, the largest metagenomic project published to date, by removing all proteins that matched Hidden Markov Models of known protein families from PFAM and TIGRFAM with high confidence (E-value > 10(-5)). This essentially left us with proteins with low or no homology to known protein families, still encompassing ~1.7 million different sequences. In this subset, we then identified protein families de novo with a Markov clustering algorithm. For each protein family, we defined a single representative based on its phylogenetic relationship to all other members in that family. This reduced the dataset to ~17,000 representatives of protein families with more than 10 members. Based on conserved regions typical for lipases and esterases, we selected a representative gene from a family of 27 members for synthesis. This protein, when expressed in E. coli, showed lipolytic activity toward para-nitrophenyl (pNP) esters. The K m-value of the enzyme was 66.68 μM for pNP-butyrate and 68.08 μM for pNP-palmitate with k cat/K m values at 3.4 × 10(6) and 6.6 × 10(5) M(-1)s(-1), respectively. Hydrolysis of model substrates showed enantiopreference for the R-form. Reactions yielded 43 and 61% enantiomeric excess of products with ibuprofen methyl ester and 2-phenylpropanoic acid ethyl ester, respectively. The enzyme retains 50% of its maximum activity at temperatures as low as 10°C, its activity is enhanced in artificial seawater and buffers with higher salt concentrations with an optimum osmolarity of 3,890 mosmol/l.
如今发布的大多数蛋白质序列数据都源自宏基因组学。然而,我们为这些序列赋予功能的能力常常受到阻碍,这是因为我们普遍无法培养大部分微生物物种,以及这些项目中产生的海量序列数据。在此,我们展示了一种结合生物信息学、合成生物学和大肠杆菌遗传学的方法,用于在宏基因组数据集中发现生物催化剂。我们通过从PFAM和TIGRFAM中高置信度地去除所有与已知蛋白质家族的隐马尔可夫模型匹配的蛋白质(E值>10^(-5)),创建了全球海洋采样数据集(迄今为止发布的最大宏基因组项目)的一个子集。这基本上给我们留下了与已知蛋白质家族同源性低或无同源性的蛋白质,仍然包含约170万个不同序列。在这个子集中,我们随后使用马尔可夫聚类算法从头识别蛋白质家族。对于每个蛋白质家族,我们根据其与该家族中所有其他成员的系统发育关系定义了一个单一代表。这将数据集减少到约17,000个具有10个以上成员的蛋白质家族代表。基于脂肪酶和酯酶典型的保守区域,我们从一个有27个成员的家族中选择了一个代表性基因进行合成。这种蛋白质在大肠杆菌中表达时,对硝基苯(pNP)酯显示出脂解活性。该酶对pNP - 丁酸酯的K_m值为66.68 μM,对pNP - 棕榈酸酯的K_m值为68.08 μM,k_cat/K_m值分别为3.4×10^6和6.6×10^5 M^(-1)s^(-1)。对模型底物的水解显示出对R型的对映体选择性。反应分别产生了43%和61%对映体过量的布洛芬甲酯和2 - 苯丙酸乙酯产物。该酶在低至10°C的温度下仍保留其最大活性的50%,其活性在人工海水和盐浓度较高的缓冲液中增强,最佳渗透压为3890 mosmol/l。