Fan Liqiong, Yeatts Sharon D, Wolf Bethany J, McClure Leslie A, Selim Magdy, Palesch Yuko Y
1 Department of Public Health Sciences, Medical University of South Carolina, Charleston, SC, USA.
2 Department of Epidemiology & Biostatistics, Drexel University, Philadelphia, PA, USA.
Stat Methods Med Res. 2018 Jan;27(1):20-34. doi: 10.1177/0962280215616405. Epub 2015 Nov 23.
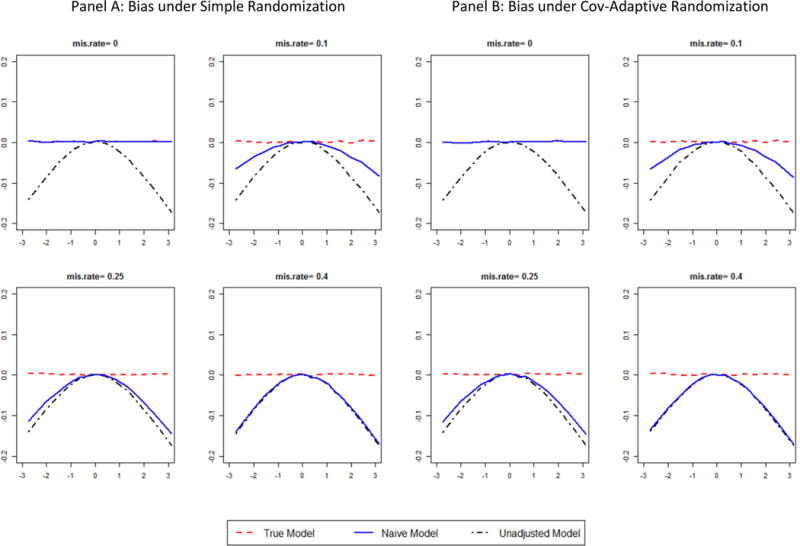
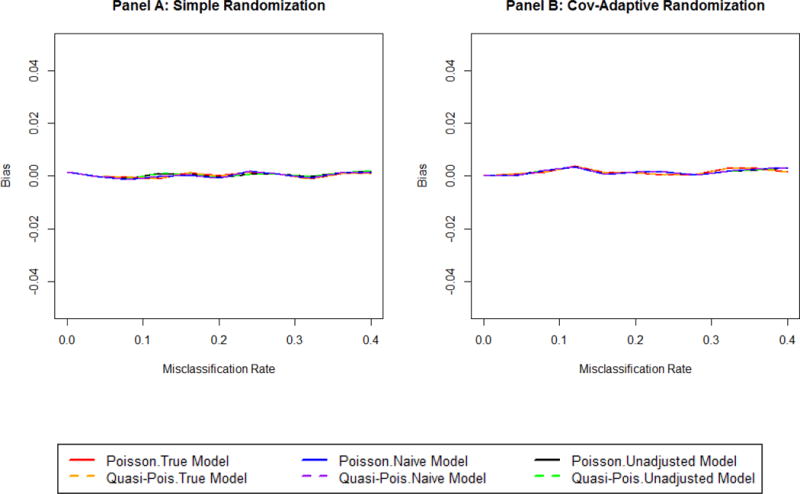
Under covariate adaptive randomization, the covariate is tied to both randomization and analysis. Misclassification of such covariate will impact the intended treatment assignment; further, it is unclear what the appropriate analysis strategy should be. We explore the impact of such misclassification on the trial's statistical operating characteristics. Simulation scenarios were created based on the misclassification rate and the covariate effect on the outcome. Models including unadjusted, adjusted for the misclassified, or adjusted for the corrected covariate were compared using logistic regression for a binary outcome and Poisson regression for a count outcome. For the binary outcome using logistic regression, type I error can be maintained in the adjusted model, but the test is conservative using an unadjusted model. Power decreased with both increasing covariate effect on the outcome as well as the misclassification rate. Treatment effect estimates were biased towards the null for both the misclassified and unadjusted models. For the count outcome using a Poisson model, covariate misclassification led to inflated type I error probabilities and reduced power in the misclassified and the unadjusted model. The impact of covariate misclassification under covariate-adaptive randomization differs depending on the underlying distribution of the outcome.
在协变量自适应随机化中,协变量与随机化和分析都相关联。此类协变量的错误分类会影响预期的治疗分配;此外,尚不清楚合适的分析策略应该是什么。我们探讨了这种错误分类对试验统计操作特征的影响。根据错误分类率和协变量对结局的影响创建了模拟场景。对于二元结局使用逻辑回归,对于计数结局使用泊松回归,比较了包括未调整、针对错误分类进行调整或针对校正后的协变量进行调整的模型。对于使用逻辑回归的二元结局,在调整后的模型中可以维持第一类错误,但使用未调整模型时检验是保守的。随着协变量对结局的影响增加以及错误分类率增加,检验效能均降低。对于错误分类模型和未调整模型,治疗效果估计均偏向于无效值。对于使用泊松模型的计数结局,协变量错误分类导致在错误分类模型和未调整模型中第一类错误概率膨胀且检验效能降低。协变量自适应随机化下协变量错误分类的影响因结局的潜在分布而异。