Bussotti Giovanni, Leonardi Tommaso, Clark Michael B, Mercer Tim R, Crawford Joanna, Malquori Lorenzo, Notredame Cedric, Dinger Marcel E, Mattick John S, Enright Anton J
EMBL, European Bioinformatics Institute, Cambridge, CB10 1SD, United Kingdom;
Garvan Institute of Medical Research, Sydney, New South Wales 2010, Australia; MRC Functional Genomics Unit, Department of Physiology, Anatomy, and Genetics, University of Oxford, Oxford OX1 3PT, United Kingdom;
Genome Res. 2016 May;26(5):705-16. doi: 10.1101/gr.199760.115.
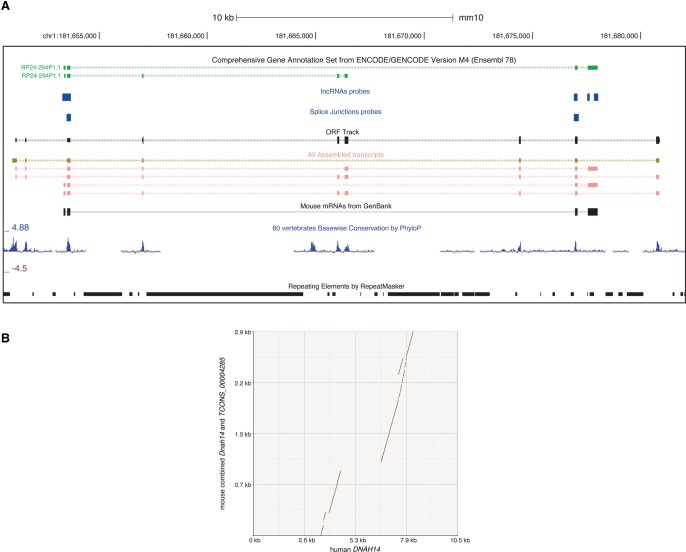
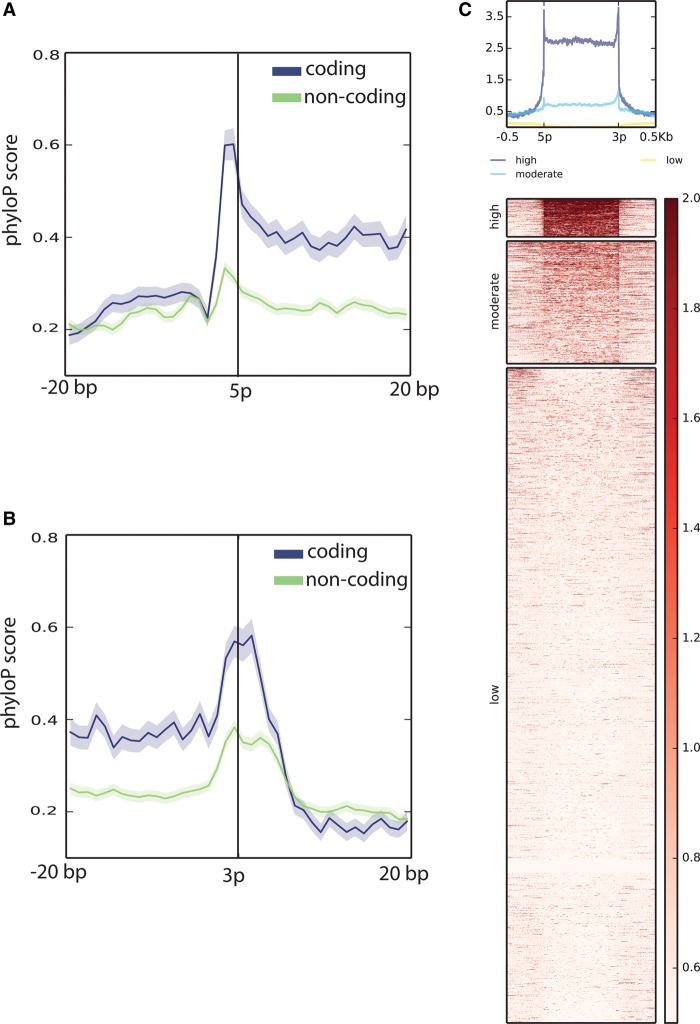
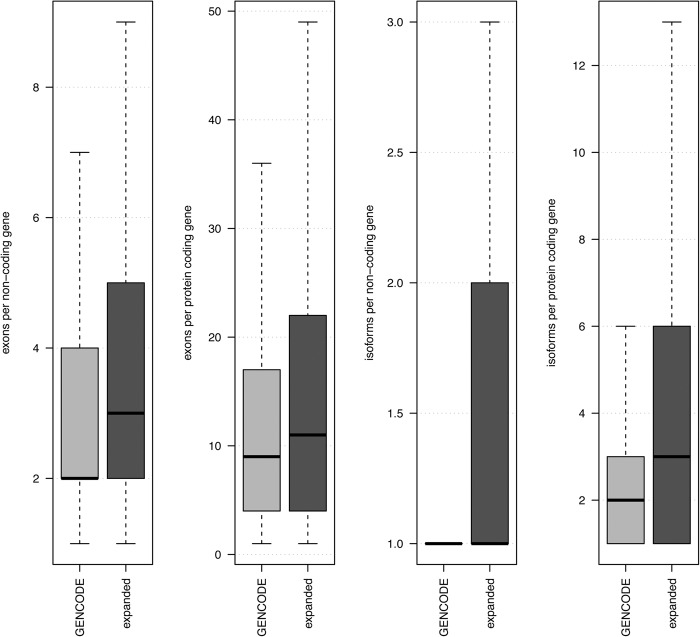
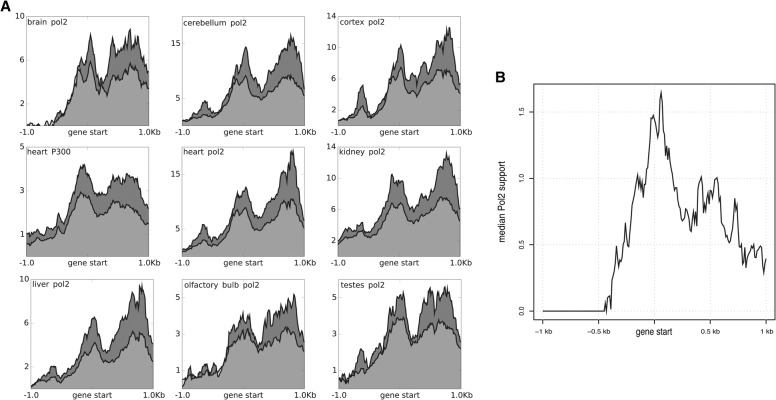
Targeted RNA sequencing (CaptureSeq) uses oligonucleotide probes to capture RNAs for sequencing, providing enriched read coverage, accurate measurement of gene expression, and quantitative expression data. We applied CaptureSeq to refine transcript annotations in the current murine GRCm38 assembly. More than 23,000 regions corresponding to putative or annotated long noncoding RNAs (lncRNAs) and 154,281 known splicing junction sites were selected for targeted sequencing across five mouse tissues and three brain subregions. The results illustrate that the mouse transcriptome is considerably more complex than previously thought. We assemble more complete transcript isoforms than GENCODE, expand transcript boundaries, and connect interspersed islands of mapped reads. We describe a novel filtering pipeline that identifies previously unannotated but high-quality transcript isoforms. In this set, 911 GENCODE neighboring genes are condensed into 400 expanded gene models. Additionally, 594 GENCODE lncRNAs acquire an open reading frame (ORF) when their structure is extended with CaptureSeq. Finally, we validate our observations using current FANTOM and Mouse ENCODE resources.
靶向RNA测序(CaptureSeq)使用寡核苷酸探针捕获RNA用于测序,可提供丰富的读取覆盖度、准确的基因表达测量以及定量表达数据。我们应用CaptureSeq来完善当前小鼠GRCm38基因组组装中的转录本注释。在五个小鼠组织和三个脑亚区域中,选择了超过23,000个对应于假定或注释的长链非编码RNA(lncRNA)的区域以及154,281个已知的剪接连接位点进行靶向测序。结果表明,小鼠转录组比以前认为的要复杂得多。我们组装的转录本异构体比GENCODE更完整,扩展了转录本边界,并连接了散布的映射读取岛。我们描述了一种新颖的过滤流程,可识别以前未注释但高质量的转录本异构体。在这个集合中,911个GENCODE相邻基因被整合为400个扩展的基因模型。此外,当594个GENCODE lncRNA的结构通过CaptureSeq扩展时,它们获得了开放阅读框(ORF)。最后,我们使用当前的FANTOM和小鼠ENCODE资源验证了我们的观察结果。