Center for Vulnerable Populations & Division of General Internal Medicine at the Zuckerberg San Francisco General Hospital, Department of Medicine, University of California San Francisco, San Francisco, CA, United States.
JMIR Public Health Surveill. 2016 Jun 10;2(1):e21. doi: 10.2196/publichealth.5308.
It is difficult to synthesize the vast amount of textual data available from social media websites. Capturing real-world discussions via social media could provide insights into individuals' opinions and the decision-making process.
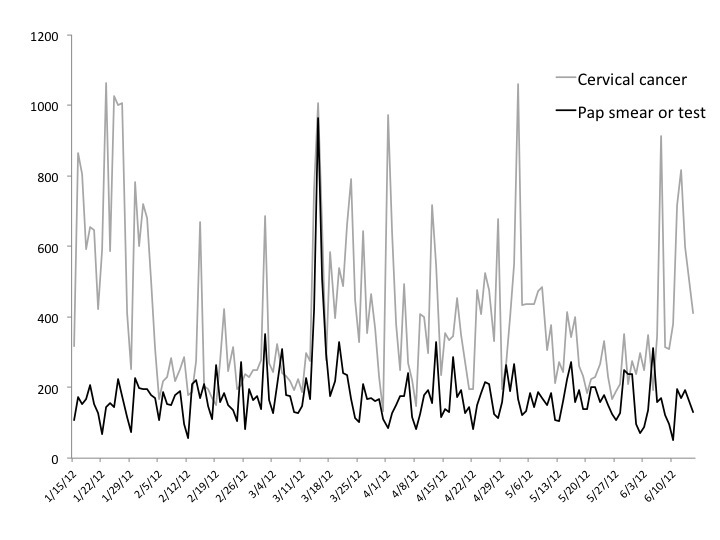
We conducted a sequential mixed methods study to determine the utility of sparse machine learning techniques in summarizing Twitter dialogues. We chose a narrowly defined topic for this approach: cervical cancer discussions over a 6-month time period surrounding a change in Pap smear screening guidelines.
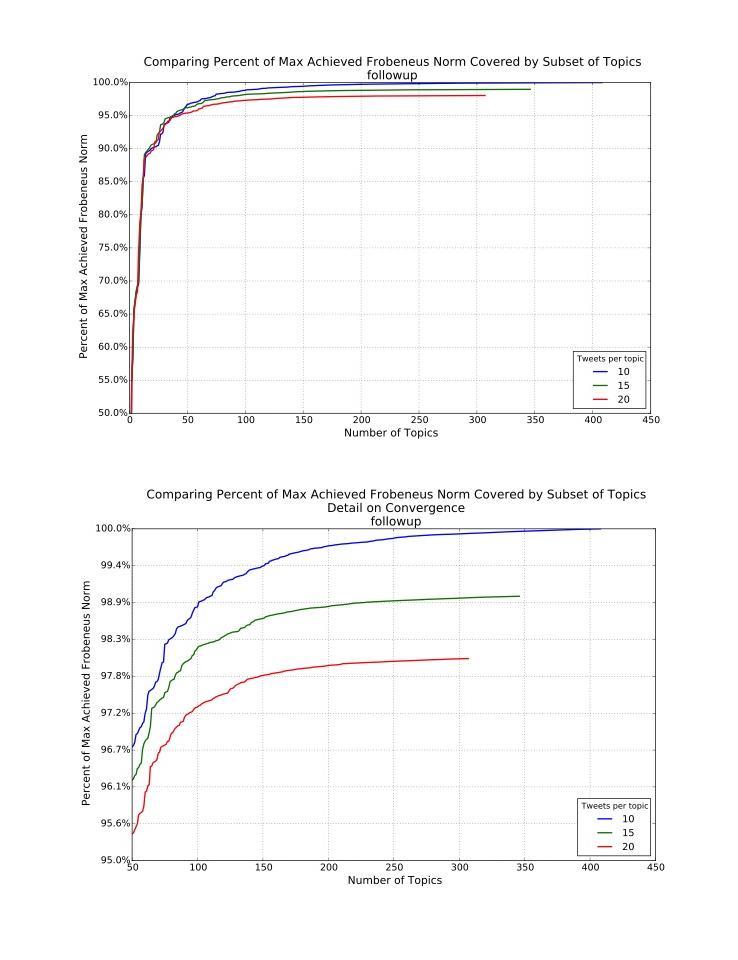
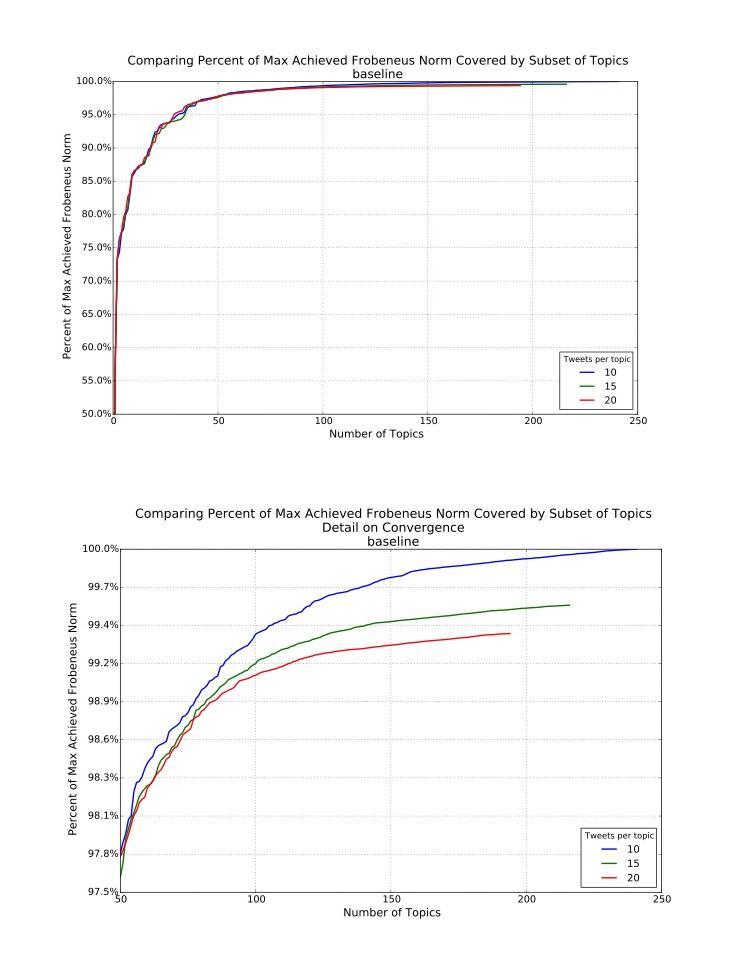
We applied statistical methodologies, known as sparse machine learning algorithms, to summarize Twitter messages about cervical cancer before and after the 2012 change in Pap smear screening guidelines by the US Preventive Services Task Force (USPSTF). All messages containing the search terms "cervical cancer," "Pap smear," and "Pap test" were analyzed during: (1) January 1-March 13, 2012, and (2) March 14-June 30, 2012. Topic modeling was used to discern the most common topics from each time period, and determine the singular value criterion for each topic. The results were then qualitatively coded from top 10 relevant topics to determine the efficiency of clustering method in grouping distinct ideas, and how the discussion differed before vs. after the change in guidelines .
This machine learning method was effective in grouping the relevant discussion topics about cervical cancer during the respective time periods (~20% overall irrelevant content in both time periods). Qualitative analysis determined that a significant portion of the top discussion topics in the second time period directly reflected the USPSTF guideline change (eg, "New Screening Guidelines for Cervical Cancer"), and many topics in both time periods were addressing basic screening promotion and education (eg, "It is Cervical Cancer Awareness Month! Click the link to see where you can receive a free or low cost Pap test.")
It was demonstrated that machine learning tools can be useful in cervical cancer prevention and screening discussions on Twitter. This method allowed us to prove that there is publicly available significant information about cervical cancer screening on social media sites. Moreover, we observed a direct impact of the guideline change within the Twitter messages.
从社交媒体网站上获取大量文本数据是很困难的。通过社交媒体捕捉真实世界的讨论,可以深入了解个人的观点和决策过程。
我们进行了一项序贯混合方法研究,以确定稀疏机器学习技术在总结 Twitter 对话中的效用。我们选择了一个狭义的主题来进行这种方法:在 2012 年美国预防服务工作组(USPSTF)改变巴氏涂片筛查指南的 6 个月期间,围绕宫颈癌讨论。
我们应用了统计方法,称为稀疏机器学习算法,来总结 2012 年 USPSTF 改变巴氏涂片筛查指南前后 Twitter 上关于宫颈癌的信息。分析了包含搜索词“宫颈癌”、“巴氏涂片”和“巴氏试验”的所有消息:(1)2012 年 1 月 1 日至 3 月 13 日,(2)2012 年 3 月 14 日至 6 月 30 日。主题建模用于从每个时间段中辨别出最常见的主题,并确定每个主题的奇异值标准。然后,从前 10 个相关主题中对结果进行定性编码,以确定聚类方法在分组不同想法方面的效率,以及讨论在指南更改前后的差异。
这种机器学习方法有效地将宫颈癌相关讨论主题分组到相应的时间段内(两个时间段的总无关内容约为 20%)。定性分析确定,第二个时间段中前 10 个热门讨论主题中有很大一部分直接反映了 USPSTF 指南的变化(例如,“宫颈癌新筛查指南”),并且两个时间段中的许多主题都在讨论基本的筛查推广和教育(例如,“这是宫颈癌宣传月!点击链接查看您可以在哪里接受免费或低价巴氏涂片检查。”)
研究表明,机器学习工具在 Twitter 上的宫颈癌预防和筛查讨论中非常有用。这种方法使我们能够证明社交媒体网站上存在有关宫颈癌筛查的大量公开信息。此外,我们观察到指南变化在 Twitter 消息中直接产生了影响。