Garcia-Ceja Enrique, Brena Ramon F
Tecnológico de Monterrey, Campus Monterrey, Av. Eugenio Garza Sada 2501 Sur, Monterrey, N.L. 64849, Mexico.
Sensors (Basel). 2016 Jun 14;16(6):877. doi: 10.3390/s16060877.
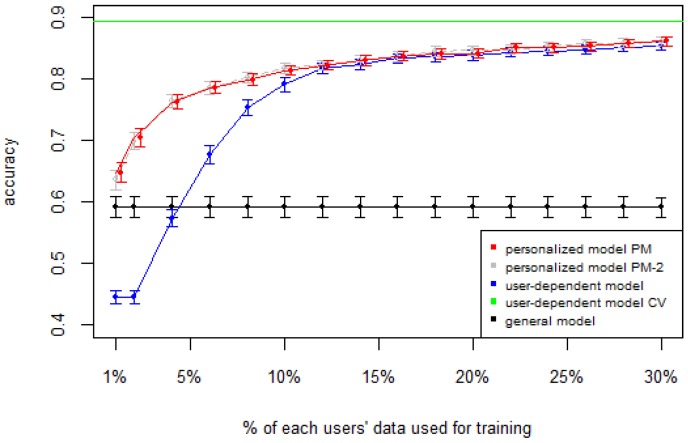
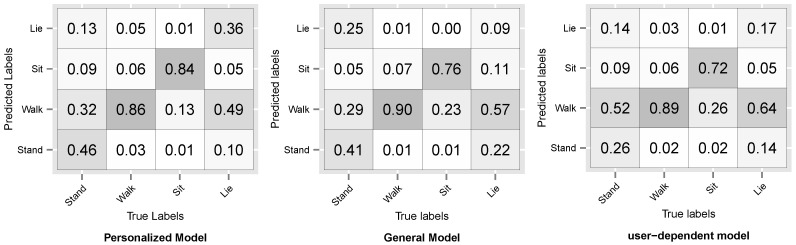
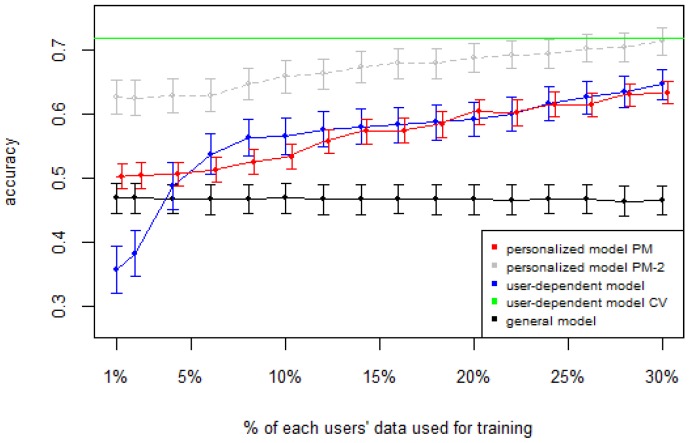
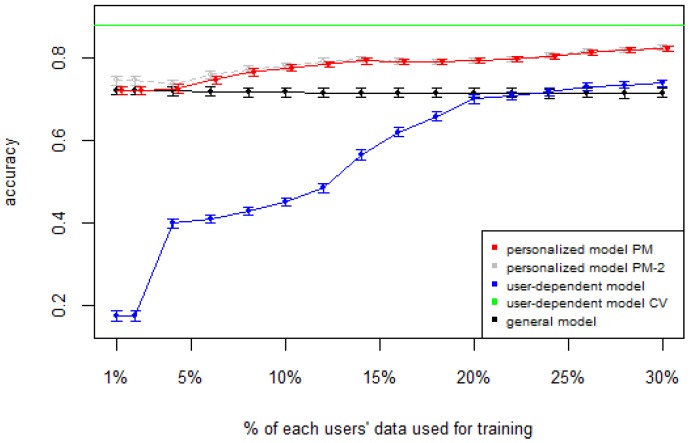
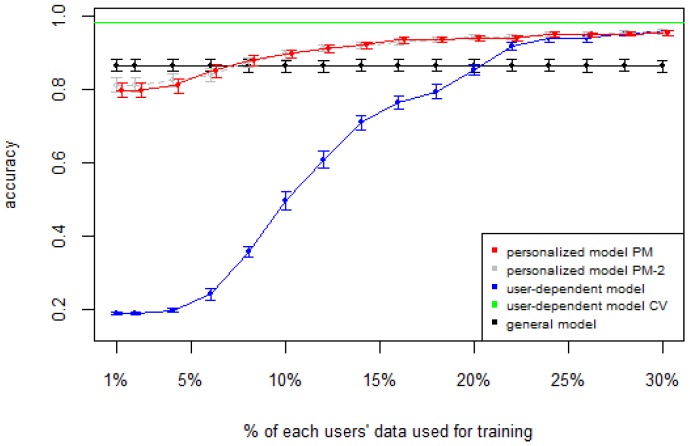
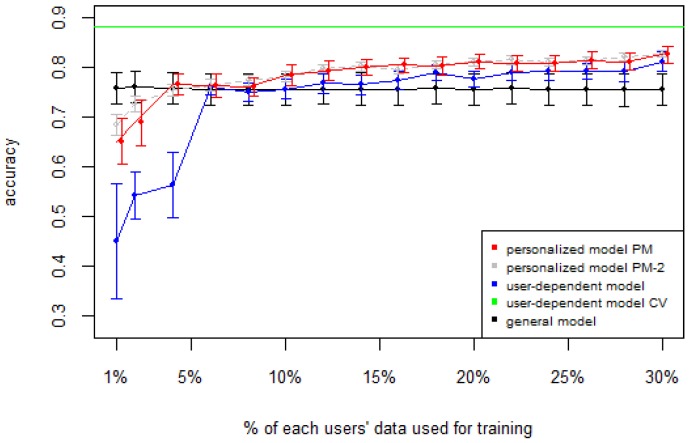
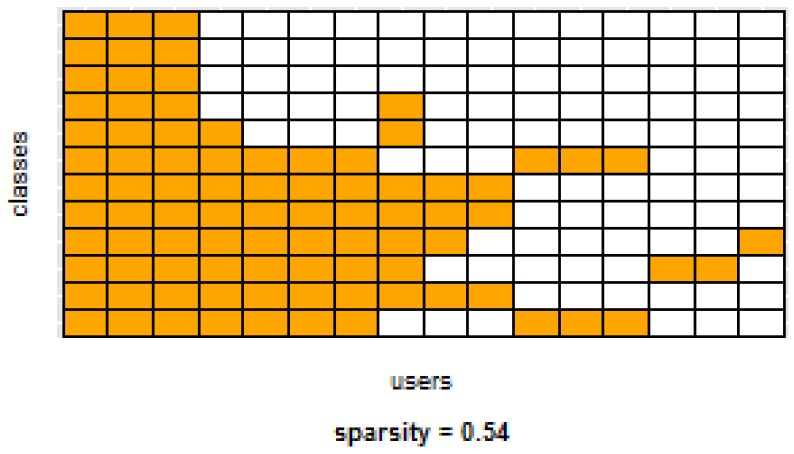
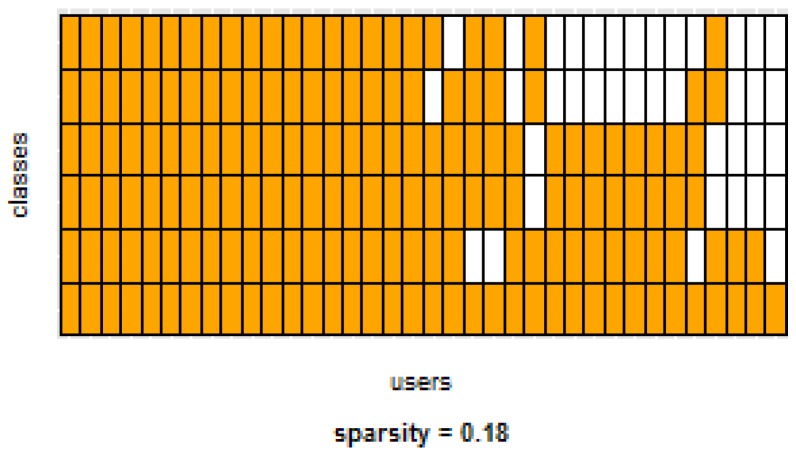
Human Activity Recognition (HAR) is an important part of ambient intelligence systems since it can provide user-context information, thus allowing a greater personalization of services. One of the problems with HAR systems is that the labeling process for the training data is costly, which has hindered its practical application. A common approach is to train a general model with the aggregated data from all users. The problem is that for a new target user, this model can perform poorly because it is biased towards the majority type of users and does not take into account the particular characteristics of the target user. To overcome this limitation, a user-dependent model can be trained with data only from the target user that will be optimal for this particular user; however, this requires a considerable amount of labeled data, which is cumbersome to obtain. In this work, we propose a method to build a personalized model for a given target user that does not require large amounts of labeled data. Our method uses data already labeled by a community of users to complement the scarce labeled data of the target user. Our results showed that the personalized model outperformed the general and the user-dependent models when labeled data is scarce.
人类活动识别(HAR)是环境智能系统的重要组成部分,因为它可以提供用户上下文信息,从而实现服务的更大程度个性化。HAR系统的问题之一是训练数据的标注过程成本高昂,这阻碍了其实际应用。一种常见的方法是使用来自所有用户的聚合数据训练一个通用模型。问题在于,对于新的目标用户,该模型可能表现不佳,因为它偏向大多数类型的用户,没有考虑目标用户的特定特征。为克服这一限制,可以仅使用来自目标用户的数据训练一个依赖用户的模型,该模型对该特定用户而言是最优的;然而,这需要大量的标注数据,获取起来很麻烦。在这项工作中,我们提出一种方法,为给定的目标用户构建一个不需要大量标注数据的个性化模型。我们的方法使用由用户群体已经标注的数据来补充目标用户稀缺的标注数据。我们的结果表明,在标注数据稀缺时,个性化模型的表现优于通用模型和依赖用户的模型。