Tang Hua, Zou Ping, Zhang Chunmei, Chen Rong, Chen Wei, Lin Hao
Department of Pathophysiology, Southwest Medical University, Luzhou 646000, China.
Key Laboratory for NeuroInformation of Ministry of Education, School of Life Science and Technology and Center for Informational Biology, University of Electronic Science and Technology of China, Chengdu 610054, China.
Sci Rep. 2016 Jul 22;6:30441. doi: 10.1038/srep30441.
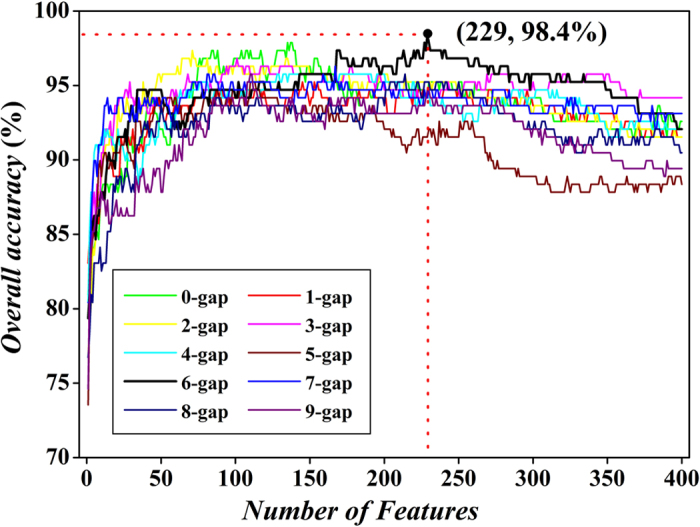
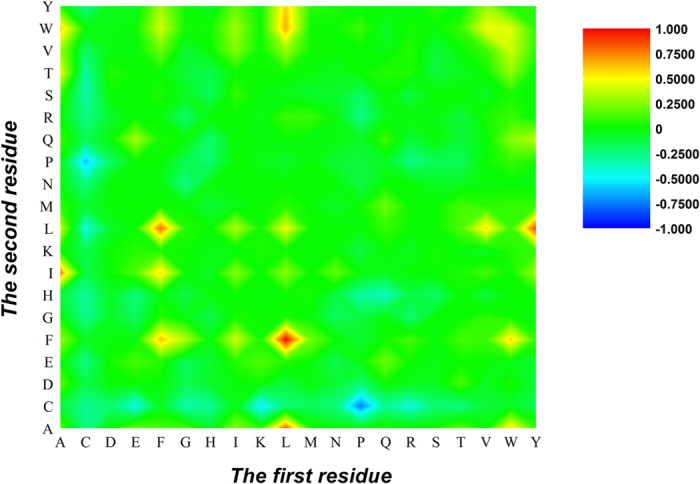
Apolipoprotein is a kind of protein which can transport the lipids through the lymphatic and circulatory systems. The abnormal expression level of apolipoprotein always causes angiocardiopathy. Thus, correct recognition of apolipoprotein from proteomic data is very crucial to the comprehension of cardiovascular system and drug design. This study is to develop a computational model to predict apolipoproteins. In the model, the apolipoproteins and non-apolipoproteins were collected to form benchmark dataset. On the basis of the dataset, we extracted the g-gap dipeptide composition information from residue sequences to formulate protein samples. To exclude redundant information or noise, the analysis of various (ANOVA)-based feature selection technique was proposed to find out the best feature subset. The support vector machine (SVM) was selected as discrimination algorithm. Results show that 96.2% of sensitivity and 99.3% of specificity were achieved in five-fold cross-validation. These findings open new perspectives to improve apolipoproteins prediction by considering the specific dipeptides. We expect that these findings will help to improve drug development in anti-angiocardiopathy disease.
载脂蛋白是一种能够通过淋巴系统和循环系统运输脂质的蛋白质。载脂蛋白的异常表达水平常常会引发心血管疾病。因此,从蛋白质组学数据中准确识别载脂蛋白对于理解心血管系统和药物设计至关重要。本研究旨在开发一种预测载脂蛋白的计算模型。在该模型中,收集载脂蛋白和非载脂蛋白以形成基准数据集。基于该数据集,我们从残基序列中提取g-gap二肽组成信息来构建蛋白质样本。为了排除冗余信息或噪声,提出了基于方差分析(ANOVA)的特征选择技术来找出最佳特征子集。选择支持向量机(SVM)作为判别算法。结果表明,在五折交叉验证中,灵敏度达到96.2%,特异性达到99.3%。这些发现为通过考虑特定二肽来改进载脂蛋白预测开辟了新的视角。我们期望这些发现将有助于改善抗心血管疾病药物的研发。