Complete Genomics, Inc., 2071 Stierlin Ct., Mountain View, CA, 94043, USA.
Harvard Personal Genome Project, Harvard Medical School, NRB 238, 77 Avenue Louis Pasteur, Boston, MA, 02115, USA.
Gigascience. 2016 Oct 11;5(1):42. doi: 10.1186/s13742-016-0148-z.
Since the completion of the Human Genome Project in 2003, it is estimated that more than 200,000 individual whole human genomes have been sequenced. A stunning accomplishment in such a short period of time. However, most of these were sequenced without experimental haplotype data and are therefore missing an important aspect of genome biology. In addition, much of the genomic data is not available to the public and lacks phenotypic information.
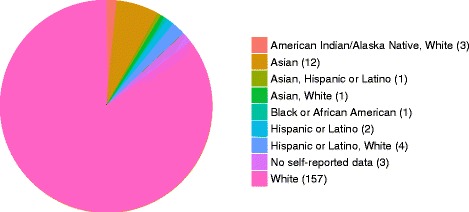
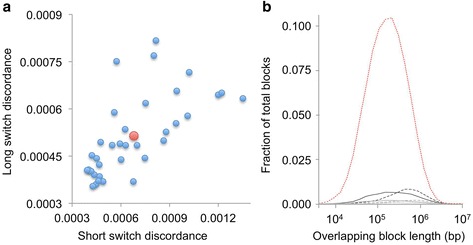
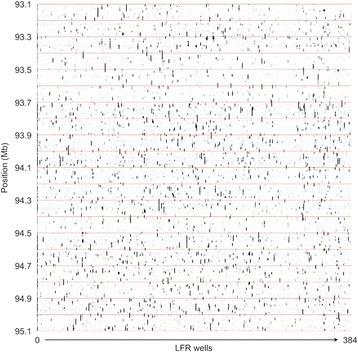
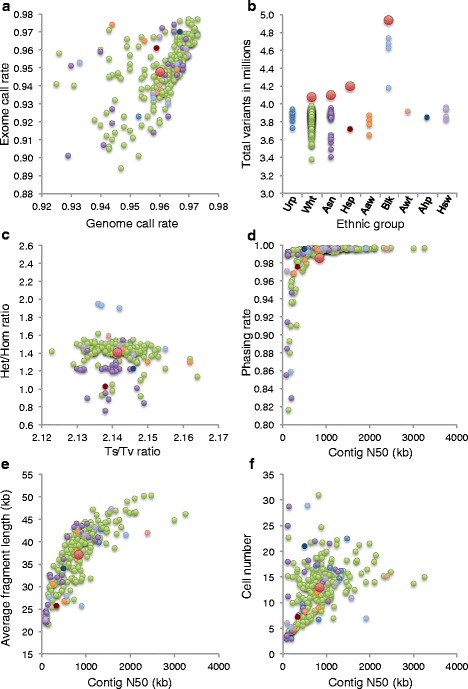
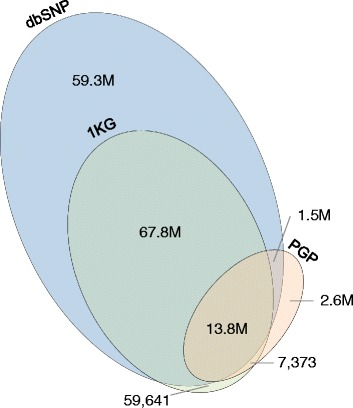
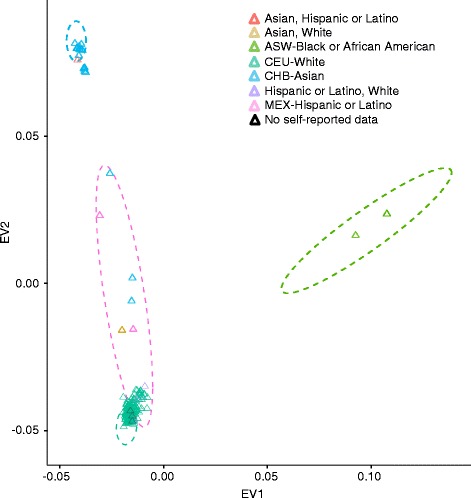
As part of the Personal Genome Project, blood samples from 184 participants were collected and processed using Complete Genomics' Long Fragment Read technology. Here, we present the experimental whole genome haplotyping and sequencing of these samples to an average read coverage depth of 100X. This is approximately three-fold higher than the read coverage applied to most whole human genome assemblies and ensures the highest quality results. Currently, 114 genomes from this dataset are freely available in the GigaDB repository and are associated with rich phenotypic data; the remaining 70 should be added in the near future as they are approved through the PGP data release process. For reproducibility analyses, 20 genomes were sequenced at least twice using independent LFR barcoded libraries. Seven genomes were also sequenced using Complete Genomics' standard non-barcoded library process. In addition, we report 2.6 million high-quality, rare variants not previously identified in the Single Nucleotide Polymorphisms database or the 1000 Genomes Project Phase 3 data.
These genomes represent a unique source of haplotype and phenotype data for the scientific community and should help to expand our understanding of human genome evolution and function.
自 2003 年人类基因组计划完成以来,据估计已经有超过 20 万个完整的人类基因组被测序。在如此短的时间内取得了惊人的成就。然而,其中大多数基因组在测序时没有实验单倍型数据,因此缺少了基因组生物学的一个重要方面。此外,大部分基因组数据公众无法获取,且缺乏表型信息。
作为个人基因组计划的一部分,从 184 名参与者身上采集了血液样本,并用 Complete Genomics 的长片段读取技术对其进行了处理。在这里,我们展示了这些样本的实验性全基因组单倍型测序和测序,平均读取覆盖率达到 100X。这大约是大多数全人类基因组组装应用的读取覆盖率的三倍,可确保最高质量的结果。目前,该数据集的 114 个基因组可在 GigaDB 存储库中免费获取,且与丰富的表型数据相关联;其余 70 个基因组应在不久的将来添加,因为它们将通过 PGP 数据发布过程获得批准。为了进行可重复性分析,使用独立的 LFR 条形码文库至少对 20 个基因组进行了两次测序。还使用 Complete Genomics 的标准非条形码文库过程对 7 个基因组进行了测序。此外,我们报告了 260 万个高质量的罕见变体,这些变体以前未在单核苷酸多态性数据库或 1000 基因组计划第三阶段数据中被识别。
这些基因组代表了单倍型和表型数据的独特来源,可供科学界使用,应该有助于扩大我们对人类基因组进化和功能的理解。