Center for Bioinformatics, University of Tübingen, Sand 14, 72076, Tübingen, Germany.
Life Sciences Institute, National University of Singapore, 28 Medical Drive, Singapore, 117456, Singapore.
Microbiome. 2017 Jan 25;5(1):11. doi: 10.1186/s40168-017-0233-2.
Microbiome sequencing projects typically collect tens of millions of short reads per sample. Depending on the goals of the project, the short reads can either be subjected to direct sequence analysis or be assembled into longer contigs. The assembly of whole genomes from metagenomic sequencing reads is a very difficult problem. However, for some questions, only specific genes of interest need to be assembled. This is then a gene-centric assembly where the goal is to assemble reads into contigs for a family of orthologous genes.
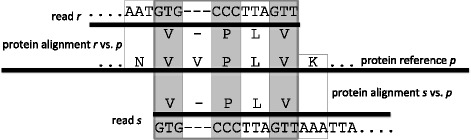
We present a new method for performing gene-centric assembly, called protein-alignment-guided assembly, and provide an implementation in our metagenome analysis tool MEGAN. Genes are assembled on the fly, based on the alignment of all reads against a protein reference database such as NCBI-nr. Specifically, the user selects a gene family based on a classification such as KEGG and all reads binned to that gene family are assembled.
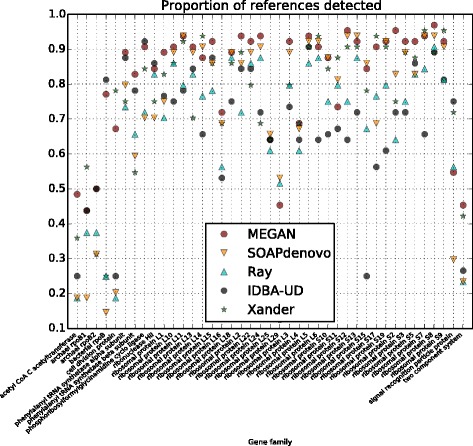
Using published synthetic community metagenome sequencing reads and a set of 41 gene families, we show that the performance of this approach compares favorably with that of full-featured assemblers and that of a recently published HMM-based gene-centric assembler, both in terms of the number of reference genes detected and of the percentage of reference sequence covered.
Protein-alignment-guided assembly of orthologous gene families complements whole-metagenome assembly in a new and very useful way.
微生物组测序项目通常每个样本收集数千万条短读段。根据项目的目标,短读段可以直接进行序列分析,也可以组装成长的连续序列。从宏基因组测序读段组装全基因组是一个非常困难的问题。然而,对于某些问题,只需要组装特定的感兴趣的基因。这是一个以基因为中心的组装,目标是将读段组装成一组同源基因的连续序列。
我们提出了一种新的以基因为中心的组装方法,称为基于蛋白质比对的组装,并在我们的宏基因组分析工具 MEGAN 中提供了实现。根据对 NCBI-nr 等蛋白质参考数据库的所有读段的比对,基因在组装过程中实时组装。具体来说,用户基于分类(如 KEGG)选择一个基因家族,然后将所有分配到该基因家族的读段进行组装。
使用已发表的合成群落宏基因组测序读段和一组 41 个基因家族,我们表明,与全功能组装器和最近发布的基于 HMM 的以基因为中心的组装器相比,这种方法在检测到的参考基因数量和参考序列覆盖百分比方面表现良好。
基于蛋白质比对的同源基因家族组装以一种新的非常有用的方式补充了全基因组组装。