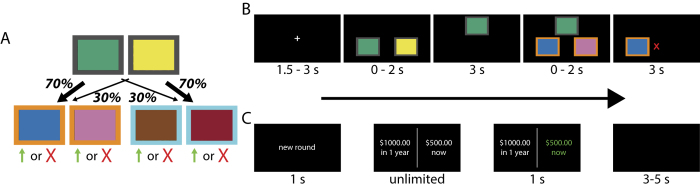
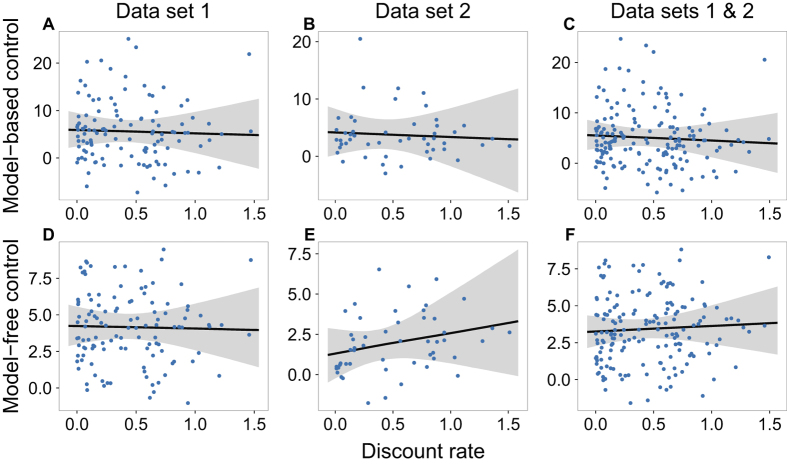
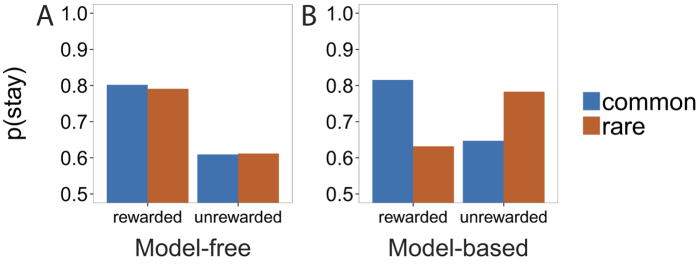
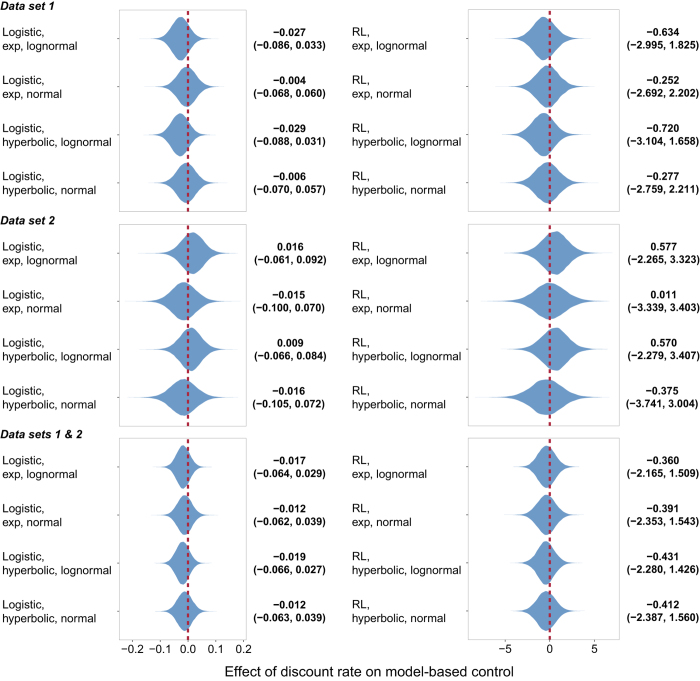
Virginia Tech Carilion Research Institute, Roanoke, VA, USA.
Department of Physics, Virginia Polytechnic Institute and State University, Blacksburg, VA, USA.
Sci Rep. 2017 Feb 22;7:43119. doi: 10.1038/srep43119.
The laboratory study of how humans and other animals trade-off value and time has a long and storied history, and is the subject of a vast literature. However, despite a long history of study, there is no agreed upon mechanistic explanation of how intertemporal choice preferences arise. Several theorists have recently proposed model-based reinforcement learning as a candidate framework. This framework describes a suite of algorithms by which a model of the environment, in the form of a state transition function and reward function, can be converted on-line into a decision. The state transition function allows the model-based system to make decisions based on projected future states, while the reward function assigns value to each state, together capturing the necessary components for successful intertemporal choice. Empirical work has also pointed to a possible relationship between increased prospection and reduced discounting. In the current paper, we look for direct evidence of a relationship between temporal discounting and model-based control in a large new data set (n = 168). However, testing the relationship under several different modeling formulations revealed no indication that the two quantities are related.
人类和其他动物权衡价值和时间的实验室研究有着悠久而丰富的历史,也是大量文献的主题。然而,尽管研究历史悠久,但对于跨期选择偏好是如何产生的,还没有一个公认的机械解释。最近有几位理论家提出基于模型的强化学习作为一个候选框架。该框架描述了一系列算法,通过这些算法,可以在线将环境模型(以状态转移函数和奖励函数的形式)转换为决策。状态转移函数允许基于预测的未来状态做出模型基系统决策,而奖励函数为每个状态赋值,共同捕获成功跨期选择所需的组成部分。实证工作也指出了内省和折扣减少之间可能存在的关系。在当前的论文中,我们在一个大型新数据集(n=168)中寻找时间折扣和基于模型的控制之间关系的直接证据。然而,在几种不同的建模公式下测试这种关系,并没有表明这两个数量之间存在关系。