Barker Daniel, D'Este Catherine, Campbell Michael J, McElduff Patrick
School of Medicine and Public Health, Faculty of Health, University of Newcastle, Newcastle, NSW, Australia.
CCEB, University of Newcastle, HMRI Building, Level 4 West, University Drive, Callaghan, NSW, 2308, Australia.
Trials. 2017 Mar 9;18(1):119. doi: 10.1186/s13063-017-1862-2.
Stepped wedge cluster randomised trials frequently involve a relatively small number of clusters. The most common frameworks used to analyse data from these types of trials are generalised estimating equations and generalised linear mixed models. A topic of much research into these methods has been their application to cluster randomised trial data and, in particular, the number of clusters required to make reasonable inferences about the intervention effect. However, for stepped wedge trials, which have been claimed by many researchers to have a statistical power advantage over the parallel cluster randomised trial, the minimum number of clusters required has not been investigated.
We conducted a simulation study where we considered the most commonly used methods suggested in the literature to analyse cross-sectional stepped wedge cluster randomised trial data. We compared the per cent bias, the type I error rate and power of these methods in a stepped wedge trial setting with a binary outcome, where there are few clusters available and when the appropriate adjustment for a time trend is made, which by design may be confounding the intervention effect.
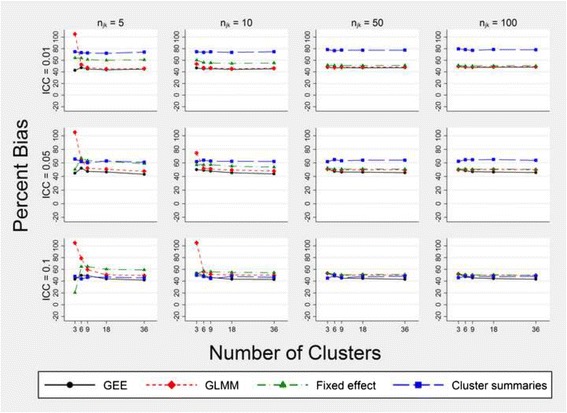
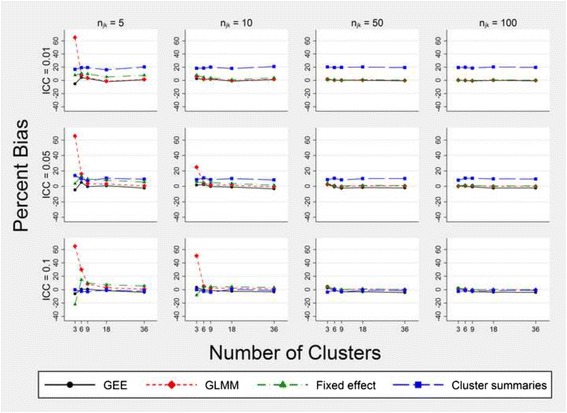
We found that the generalised linear mixed modelling approach is the most consistent when few clusters are available. We also found that none of the common analysis methods for stepped wedge trials were both unbiased and maintained a 5% type I error rate when there were only three clusters.
Of the commonly used analysis approaches, we recommend the generalised linear mixed model for small stepped wedge trials with binary outcomes. We also suggest that in a stepped wedge design with three steps, at least two clusters be randomised at each step, to ensure that the intervention effect estimator maintains the nominal 5% significance level and is also reasonably unbiased.
阶梯楔形整群随机试验通常涉及相对较少数量的群组。用于分析这类试验数据的最常见框架是广义估计方程和广义线性混合模型。对这些方法的大量研究主题之一是它们在整群随机试验数据中的应用,特别是关于对干预效果进行合理推断所需的群组数量。然而,对于许多研究人员声称比平行整群随机试验具有统计功效优势的阶梯楔形试验,所需的最小群组数量尚未得到研究。
我们进行了一项模拟研究,考虑了文献中建议的分析横断面阶梯楔形整群随机试验数据的最常用方法。我们在二元结局的阶梯楔形试验设置中比较了这些方法的偏差百分比、I型错误率和功效,在这种设置中,可用群组较少,并且对时间趋势进行了适当调整,而这种调整在设计上可能会混淆干预效果。
我们发现,当可用群组较少时,广义线性混合建模方法最为一致。我们还发现,当只有三个群组时,阶梯楔形试验的常见分析方法中没有一种既无偏差又能保持5%的I型错误率。
在常用的分析方法中,对于具有二元结局的小型阶梯楔形试验,我们推荐使用广义线性混合模型。我们还建议,在具有三个步骤的阶梯楔形设计中,每个步骤至少随机分配两个群组,以确保干预效果估计器保持名义上的5%显著性水平,并且也具有合理的无偏性。