Li Peng, Redden David T
Department of Biostatistics, School of Public Health, University of Alabama at Birmingham, Birmingham, Alabama, 35294, USA.
BMC Med Res Methodol. 2015 Apr 23;15:38. doi: 10.1186/s12874-015-0026-x.
Small number of clusters and large variation of cluster sizes commonly exist in cluster-randomized trials (CRTs) and are often the critical factors affecting the validity and efficiency of statistical analyses. F tests are commonly used in the generalized linear mixed model (GLMM) to test intervention effects in CRTs. The most challenging issue for the approximate Wald F test is the estimation of the denominator degrees of freedom (DDF). Some DDF approximation methods have been proposed, but their small sample performances in analysing binary outcomes in CRTs with few heterogeneous clusters are not well studied.
The small sample performances of five DDF approximations for the F test are compared and contrasted under CRT frameworks with simulations. Specifically, we illustrate how the intraclass correlation (ICC), sample size, and the variation of cluster sizes affect the type I error and statistical power when different DDF approximation methods in GLMM are used to test intervention effect in CRTs with binary outcomes. The results are also illustrated using a real CRT dataset.
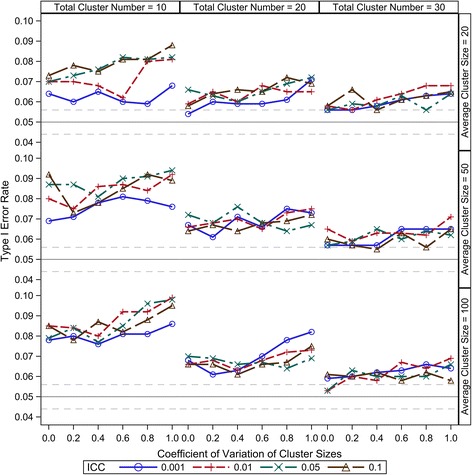
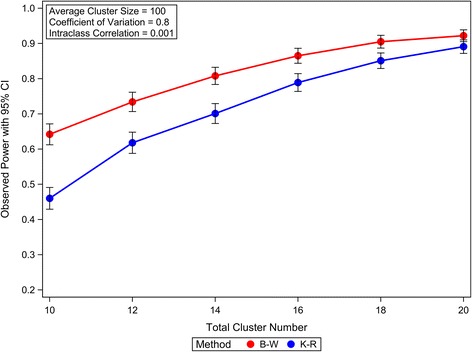
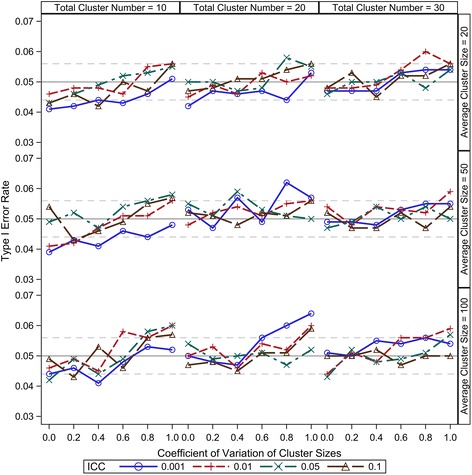
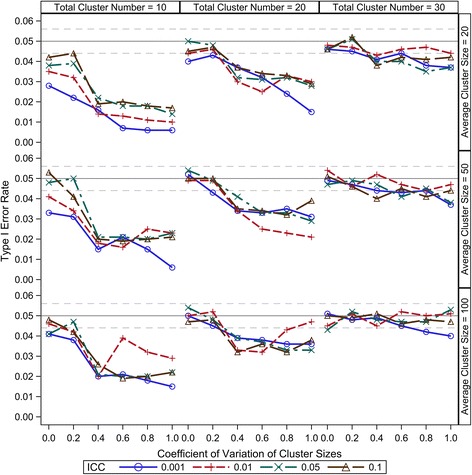
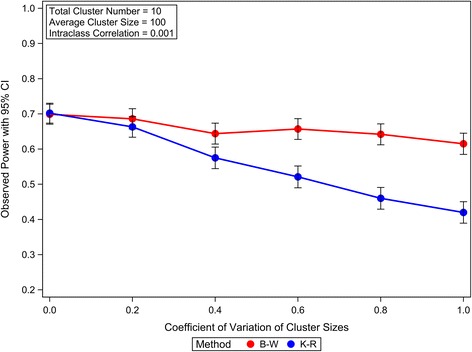
Our simulation results suggest that the Between-Within method maintains the nominal type I error rates even when the total number of clusters is as low as 10 and is robust to the variation of the cluster sizes. The Residual and Containment methods have inflated type I error rates when the cluster number is small (<30) and the inflation becomes more severe with increased variation in cluster sizes. In contrast, the Satterthwaite and Kenward-Roger methods can provide tests with very conservative type I error rates when the total cluster number is small (<30) and the conservativeness becomes more severe as variation in cluster sizes increases. Our simulations also suggest that the Between-Within method is statistically more powerful than the Satterthwaite or Kenward-Roger method in analysing CRTs with heterogeneous cluster sizes, especially when the cluster number is small.
We conclude that the Between-Within denominator degrees of freedom approximation method for F tests should be recommended when the GLMM is used in analysing CRTs with binary outcomes and few heterogeneous clusters, due to its type I error properties and relatively higher power.
整群随机试验(CRT)中通常存在少量聚类且聚类大小差异较大的情况,这往往是影响统计分析有效性和效率的关键因素。F检验常用于广义线性混合模型(GLMM)中以检验CRT中的干预效果。近似Wald F检验最具挑战性的问题是分母自由度(DDF)的估计。已经提出了一些DDF近似方法,但它们在分析具有少量异质性聚类的CRT中的二元结局时的小样本性能尚未得到充分研究。
在CRT框架下通过模拟比较和对比F检验的五种DDF近似方法的小样本性能。具体而言,我们说明了当使用GLMM中的不同DDF近似方法来检验具有二元结局的CRT中的干预效果时,组内相关系数(ICC)、样本量和聚类大小的变化如何影响I型错误率和统计功效。还使用真实的CRT数据集展示了结果。
我们的模拟结果表明,即使聚类总数低至10,组间-组内方法也能保持名义I型错误率,并且对聚类大小的变化具有鲁棒性。当聚类数量较少(<30)时,残差法和包含法的I型错误率会膨胀,并且随着聚类大小变化的增加,这种膨胀会更加严重。相比之下,当聚类总数较少(<30)时,萨特思韦特法和肯沃德-罗杰法会提供非常保守的I型错误率检验,并且随着聚类大小变化的增加,保守性会更加严重。我们的模拟还表明,在分析具有异质性聚类大小的CRT时,组间-组内方法在统计上比萨特思韦特法或肯沃德-罗杰法更具功效,尤其是当聚类数量较少时。
我们得出结论,当使用GLMM分析具有二元结局且异质性聚类较少的CRT时,由于其I型错误特性和相对较高的功效,应推荐使用组间-组内分母自由度近似方法进行F检验。