Tissier Renaud, Tsonaka Roula, Mooijaart Simon P, Slagboom Eline, Houwing-Duistermaat Jeanine J
Department of Medical Statistics and Bioinformatics, Leiden University Medical Centre, Leiden, The Netherlands.
Department of Gerontology and Geriatrics, Leiden University Medical Centre, Leiden, The Netherlands.
Stat Med. 2017 Jun 30;36(14):2288-2301. doi: 10.1002/sim.7281. Epub 2017 Mar 16.
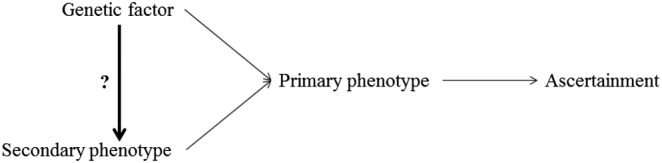
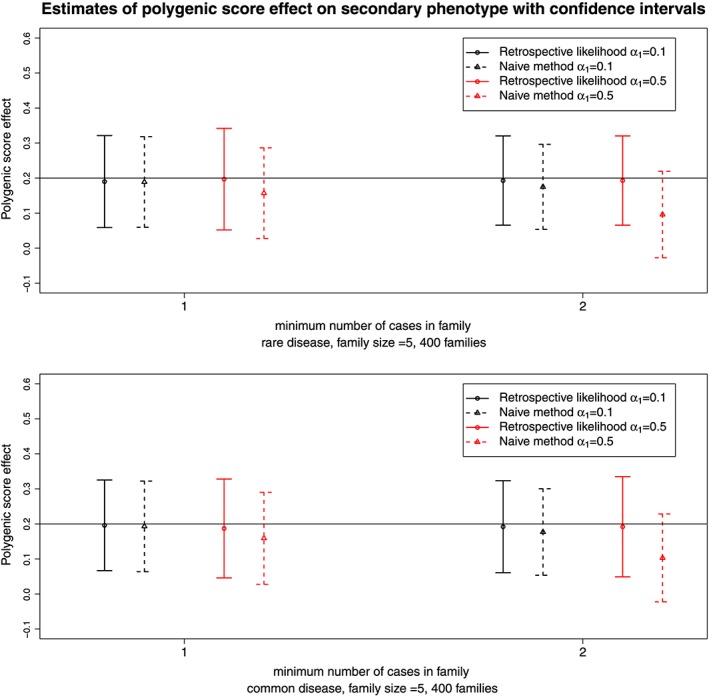
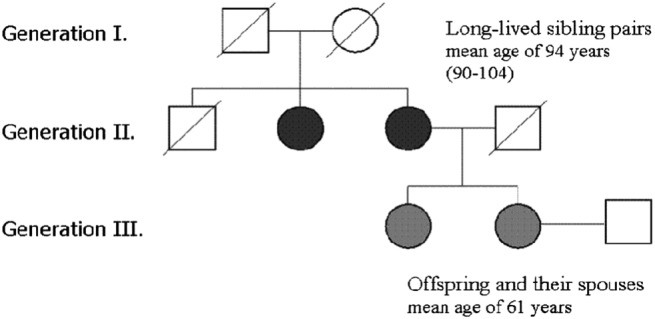
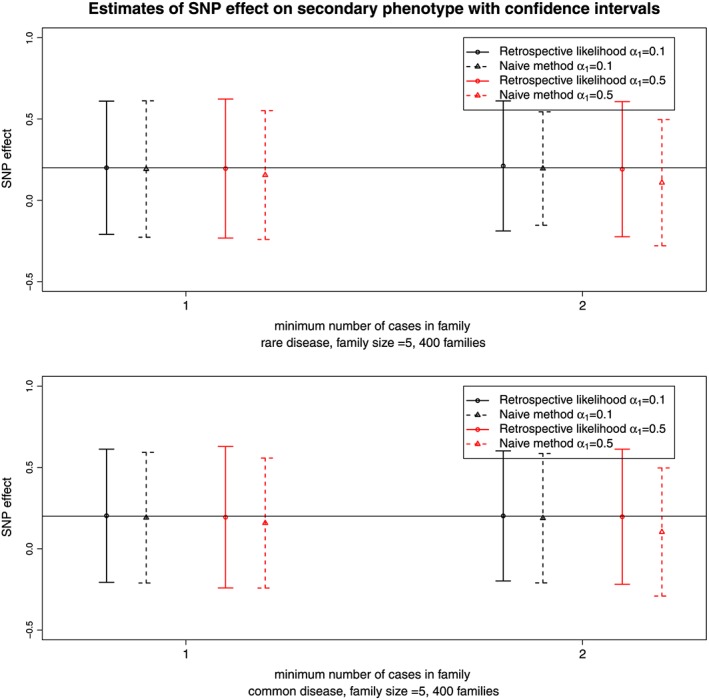
The case-control design is often used to test associations between the case-control status and genetic variants. In addition to this primary phenotype, a number of additional traits, known as secondary phenotypes, are routinely recorded, and typically, associations between genetic factors and these secondary traits are studied too. Analysing secondary phenotypes in case-control studies may lead to biased genetic effect estimates, especially when the marker tested is associated with the primary phenotype and when the primary and secondary phenotypes tested are correlated. Several methods have been proposed in the literature to overcome the problem, but they are limited to case-control studies and not directly applicable to more complex designs, such as the multiple-cases family studies. A proper secondary phenotype analysis, in this case, is complicated by the within families correlations on top of the biased sampling design. We propose a novel approach to accommodate the ascertainment process while explicitly modelling the familial relationships. Our approach pairs existing methods for mixed-effects models with the retrospective likelihood framework and uses a multivariate probit model to capture the association between the mixed type primary and secondary phenotypes. To examine the efficiency and bias of the estimates, we performed simulations under several scenarios for the association between the primary phenotype, secondary phenotype and genetic markers. We will illustrate the method by analysing the association between triglyceride levels and glucose (secondary phenotypes) and genetic markers from the Leiden Longevity Study, a multiple-cases family study that investigates longevity. © 2017 The Authors. Statistics in Medicine Published by JohnWiley & Sons Ltd.
病例对照设计常用于检验病例对照状态与基因变异之间的关联。除了这种主要表型外,还会常规记录许多其他性状,即所谓的次要表型,并且通常也会研究基因因素与这些次要性状之间的关联。在病例对照研究中分析次要表型可能会导致基因效应估计出现偏差,尤其是当所检测的标记与主要表型相关,且所检测的主要和次要表型相互关联时。文献中已经提出了几种方法来克服这个问题,但它们仅限于病例对照研究,不能直接应用于更复杂的设计,如多病例家系研究。在这种情况下,由于偏差抽样设计之上的家系内相关性,合适的次要表型分析变得复杂。我们提出了一种新颖的方法,在明确建模家族关系的同时适应确定过程。我们的方法将混合效应模型的现有方法与回顾性似然框架相结合,并使用多元概率单位模型来捕捉混合型主要和次要表型之间的关联。为了检验估计值的效率和偏差,我们针对主要表型、次要表型和基因标记之间的关联在几种情况下进行了模拟。我们将通过分析甘油三酯水平与葡萄糖(次要表型)之间的关联以及来自莱顿长寿研究(一项调查长寿的多病例家系研究)的基因标记来说明该方法。© 2017作者。《医学统计学》由约翰威立父子有限公司出版