Clément Yves, Sarah Gautier, Holtz Yan, Homa Felix, Pointet Stéphanie, Contreras Sandy, Nabholz Benoit, Sabot François, Sauné Laure, Ardisson Morgane, Bacilieri Roberto, Besnard Guillaume, Berger Angélique, Cardi Céline, De Bellis Fabien, Fouet Olivier, Jourda Cyril, Khadari Bouchaib, Lanaud Claire, Leroy Thierry, Pot David, Sauvage Christopher, Scarcelli Nora, Tregear James, Vigouroux Yves, Yahiaoui Nabila, Ruiz Manuel, Santoni Sylvain, Labouisse Jean-Pierre, Pham Jean-Louis, David Jacques, Glémin Sylvain
Montpellier SupAgro, UMR AGAP, Montpellier, France.
UMR 5554 ISEM (Université de Montpellier-CNRS-IRD-EPHE), Montpellier, France.
PLoS Genet. 2017 May 22;13(5):e1006799. doi: 10.1371/journal.pgen.1006799. eCollection 2017 May.
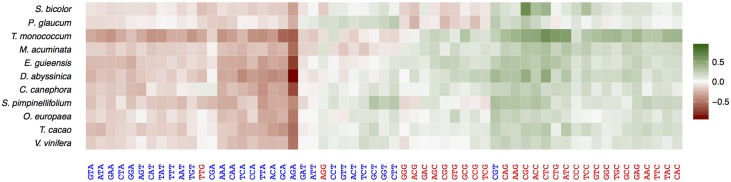
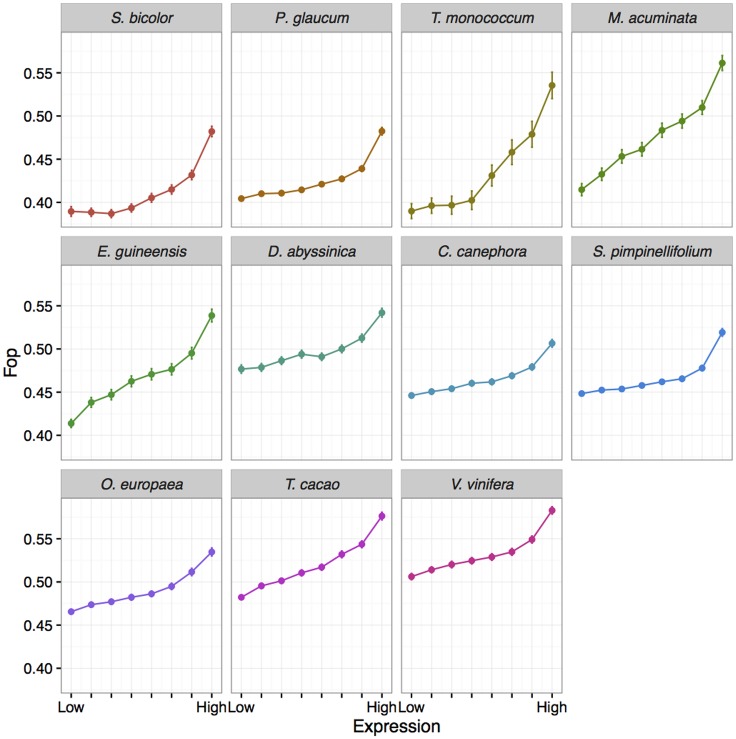
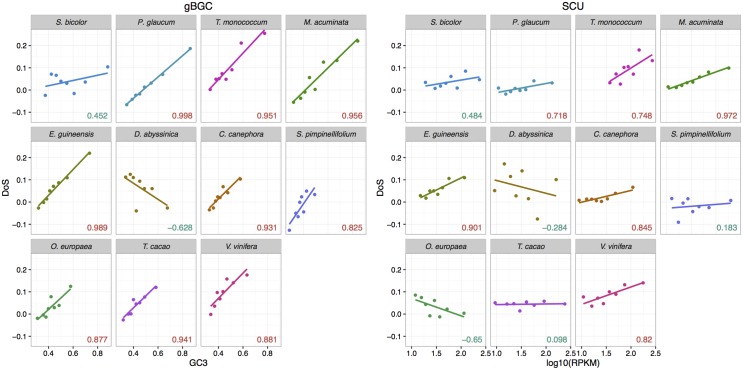
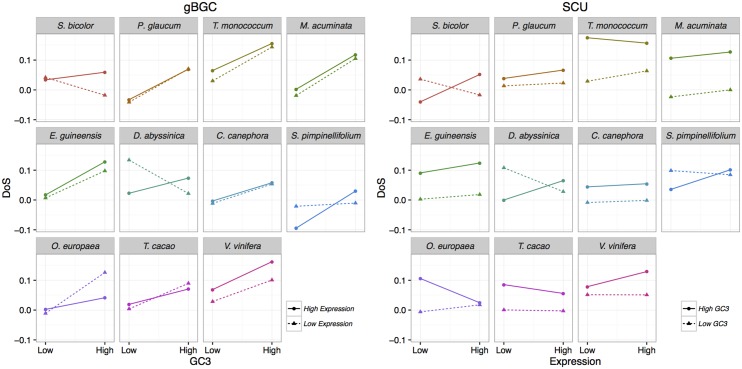
Base composition is highly variable among and within plant genomes, especially at third codon positions, ranging from GC-poor and homogeneous species to GC-rich and highly heterogeneous ones (particularly Monocots). Consequently, synonymous codon usage is biased in most species, even when base composition is relatively homogeneous. The causes of these variations are still under debate, with three main forces being possibly involved: mutational bias, selection and GC-biased gene conversion (gBGC). So far, both selection and gBGC have been detected in some species but how their relative strength varies among and within species remains unclear. Population genetics approaches allow to jointly estimating the intensity of selection, gBGC and mutational bias. We extended a recently developed method and applied it to a large population genomic dataset based on transcriptome sequencing of 11 angiosperm species spread across the phylogeny. We found that at synonymous positions, base composition is far from mutation-drift equilibrium in most genomes and that gBGC is a widespread and stronger process than selection. gBGC could strongly contribute to base composition variation among plant species, implying that it should be taken into account in plant genome analyses, especially for GC-rich ones.
植物基因组之间以及基因组内部的碱基组成差异很大,尤其是在密码子的第三位,范围从低GC含量且同质化的物种到高GC含量且高度异质化的物种(特别是单子叶植物)。因此,即使碱基组成相对同质化,大多数物种的同义密码子使用也存在偏向性。这些变异的原因仍在争论中,可能涉及三种主要力量:突变偏向、选择和GC偏向的基因转换(gBGC)。到目前为止,在一些物种中已经检测到选择和gBGC,但它们在物种之间和物种内部的相对强度如何变化仍不清楚。群体遗传学方法可以联合估计选择强度、gBGC和突变偏向。我们扩展了一种最近开发的方法,并将其应用于一个基于11种被子植物转录组测序的大型群体基因组数据集,这些物种分布在整个系统发育树上。我们发现,在同义位置,大多数基因组的碱基组成远未达到突变 - 漂变平衡,并且gBGC是一个比选择更广泛且更强的过程。gBGC可能对植物物种间的碱基组成变异有很大贡献,这意味着在植物基因组分析中应考虑到它,特别是对于富含GC的基因组。