Ten Hoopen Petra, Finn Robert D, Bongo Lars Ailo, Corre Erwan, Fosso Bruno, Meyer Folker, Mitchell Alex, Pelletier Eric, Pesole Graziano, Santamaria Monica, Willassen Nils Peder, Cochrane Guy
European Molecular Biology Laboratory, European Bioinformatics Institute, Wellcome Genome Campus, Hinxton, Cambridge CB10 1SD, United Kingdom.
UiT The Arctic University of Norway, Tromsø N-9037, Norway.
Gigascience. 2017 Aug 1;6(8):1-11. doi: 10.1093/gigascience/gix047.
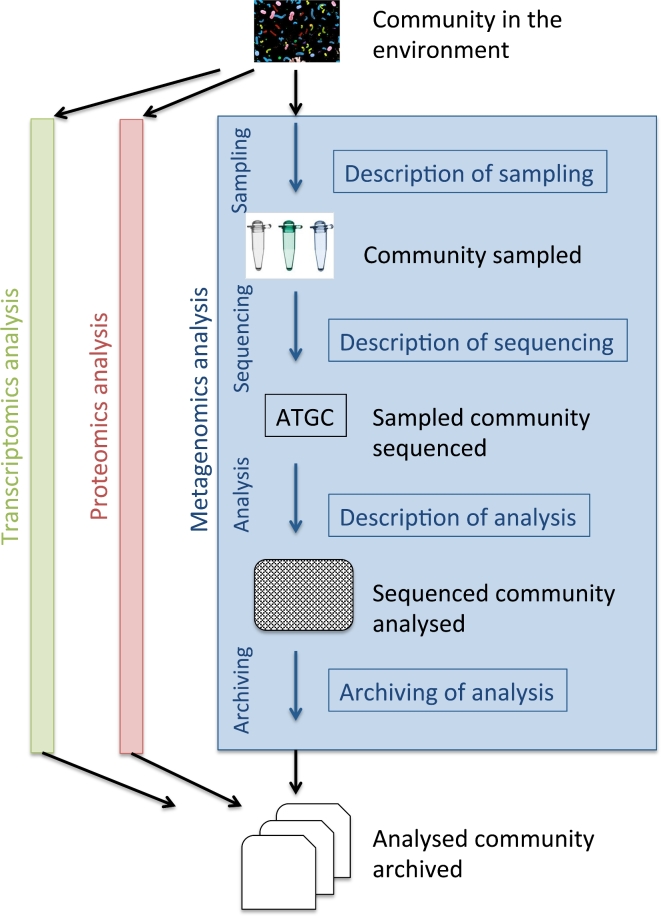
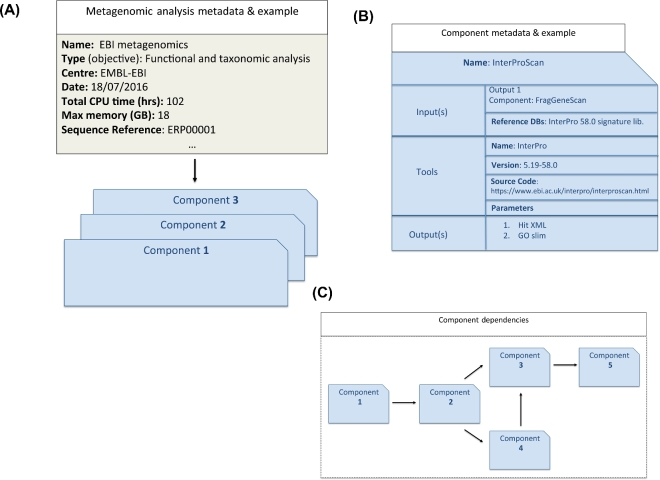
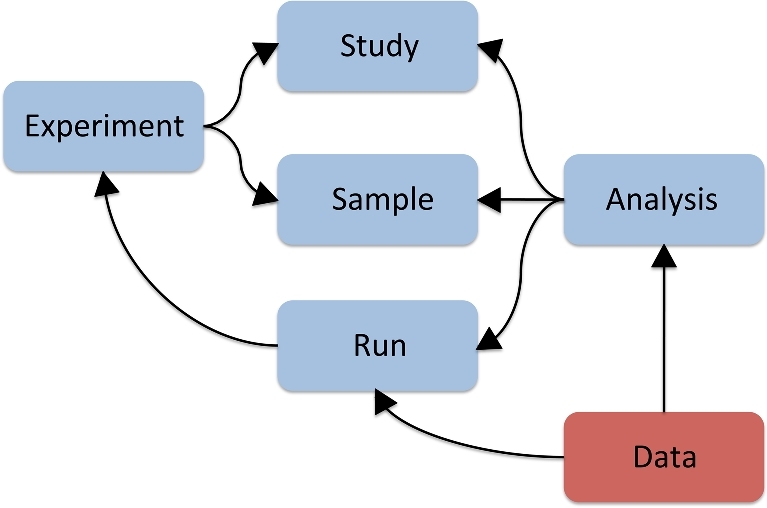
Metagenomics data analyses from independent studies can only be compared if the analysis workflows are described in a harmonized way. In this overview, we have mapped the landscape of data standards available for the description of essential steps in metagenomics: (i) material sampling, (ii) material sequencing, (iii) data analysis, and (iv) data archiving and publishing. Taking examples from marine research, we summarize essential variables used to describe material sampling processes and sequencing procedures in a metagenomics experiment. These aspects of metagenomics dataset generation have been to some extent addressed by the scientific community, but greater awareness and adoption is still needed. We emphasize the lack of standards relating to reporting how metagenomics datasets are analysed and how the metagenomics data analysis outputs should be archived and published. We propose best practice as a foundation for a community standard to enable reproducibility and better sharing of metagenomics datasets, leading ultimately to greater metagenomics data reuse and repurposing.
只有当分析工作流程以统一的方式进行描述时,来自独立研究的宏基因组学数据分析结果才能进行比较。在本综述中,我们梳理了可用于描述宏基因组学关键步骤的数据标准情况:(i)样本采集,(ii)样本测序,(iii)数据分析,以及(iv)数据存档与发布。以海洋研究为例,我们总结了用于描述宏基因组学实验中样本采集过程和测序程序的关键变量。科学界在一定程度上已经关注到宏基因组学数据集生成的这些方面,但仍需要更高的关注度和采用率。我们强调,在报告宏基因组学数据集的分析方式以及宏基因组学数据分析结果应如何存档和发布方面,缺乏相关标准。我们提出将最佳实践作为社区标准的基础,以实现宏基因组学数据集的可重复性和更好的共享,最终促进宏基因组学数据的更多复用和重新利用。