Han Ting-Li, Yang Yang, Zhang Hua, Law Kai P
Mass Spectrometry Centre, China-Canada-New Zealand Joint Laboratory of Maternal and Foetal Medicine, Chongqing Medical University, Chongqing, 400016, China.
Department of Obstetrics, The First Affiliated Hospital of Chongqing Medical University, Chongqing, 400016, China.
F1000Res. 2017 Jun 22;6:967. doi: 10.12688/f1000research.11823.1. eCollection 2017.
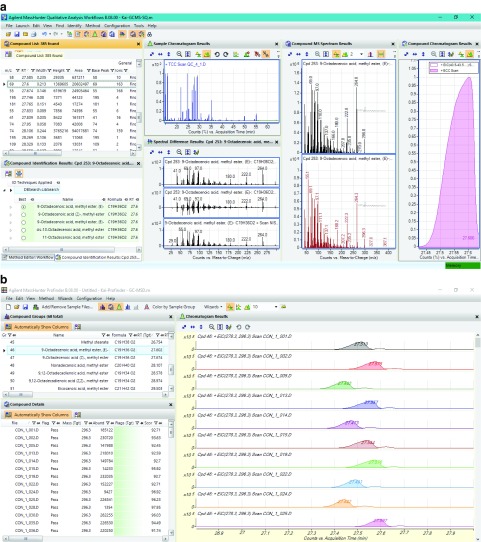
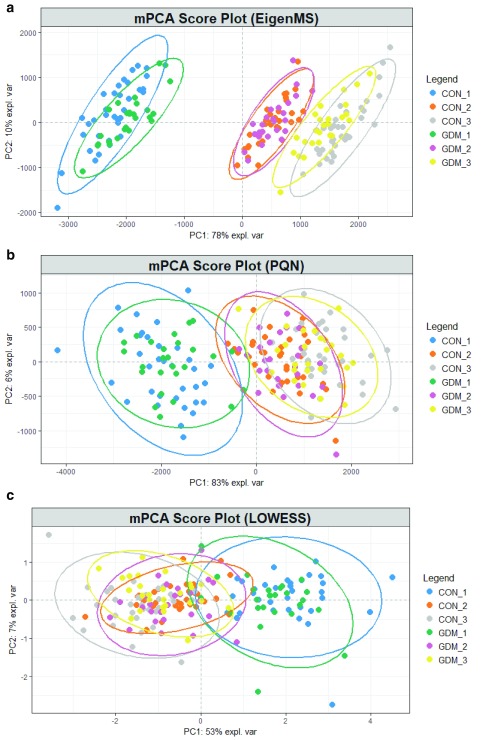
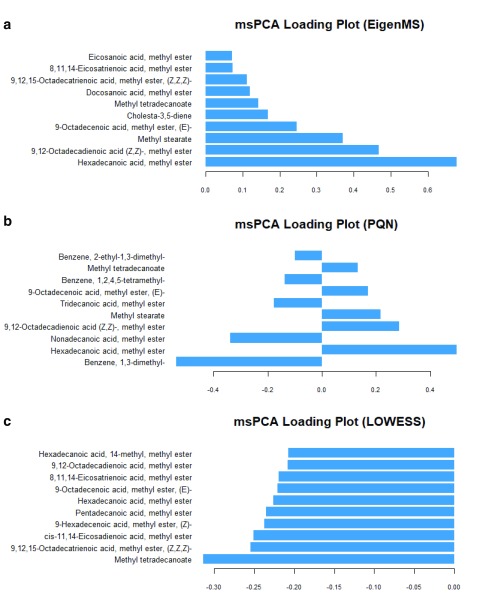
A challenge of metabolomics is data processing the enormous amount of information generated by sophisticated analytical techniques. The raw data of an untargeted metabolomic experiment are composited with unwanted biological and technical variations that confound the biological variations of interest. The art of data normalisation to offset these variations and/or eliminate experimental or biological biases has made significant progress recently. However, published comparative studies are often biased or have omissions. We investigated the issues with our own data set, using five different representative methods of internal standard-based, model-based, and pooled quality control-based approaches, and examined the performance of these methods against each other in an epidemiological study of gestational diabetes using plasma. Our results demonstrated that the quality control-based approaches gave the highest data precision in all methods tested, and would be the method of choice for controlled experimental conditions. But for our epidemiological study, the model-based approaches were able to classify the clinical groups more effectively than the quality control-based approaches because of their ability to minimise not only technical variations, but also biological biases from the raw data. We suggest that metabolomic researchers should optimise and justify the method they have chosen for their experimental condition in order to obtain an optimal biological outcome.
代谢组学面临的一个挑战是对复杂分析技术产生的大量信息进行数据处理。非靶向代谢组学实验的原始数据包含不需要的生物学和技术变异,这些变异混淆了感兴趣的生物学变异。为抵消这些变异和/或消除实验或生物学偏差而进行数据标准化的技术最近取得了重大进展。然而,已发表的比较研究往往存在偏差或遗漏。我们使用基于内标、基于模型和基于混合质量控制的五种不同代表性方法,对我们自己的数据集进行了研究,并在一项使用血浆的妊娠期糖尿病流行病学研究中,相互检验了这些方法的性能。我们的结果表明,在所有测试方法中,基于质量控制的方法具有最高的数据精度,并且在受控实验条件下将是首选方法。但对于我们的流行病学研究,基于模型的方法能够比基于质量控制的方法更有效地对临床组进行分类,因为它们不仅能够将技术变异降至最低,还能将原始数据中的生物学偏差降至最低。我们建议代谢组学研究人员应根据实验条件优化并说明所选择的方法,以获得最佳生物学结果。