INRA, UMR1019, UNH-MAPPING Clermont-Ferrand, France.
INRA, UMR1019, Plateforme d'Exploration du Métabolisme Clermont-Ferrand, France.
Front Mol Biosci. 2016 Jul 8;3:30. doi: 10.3389/fmolb.2016.00030. eCollection 2016.
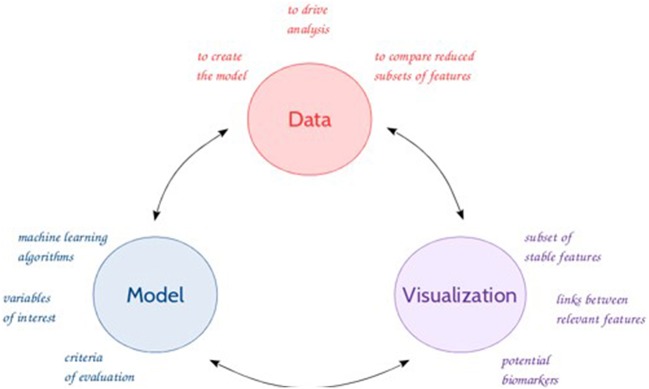
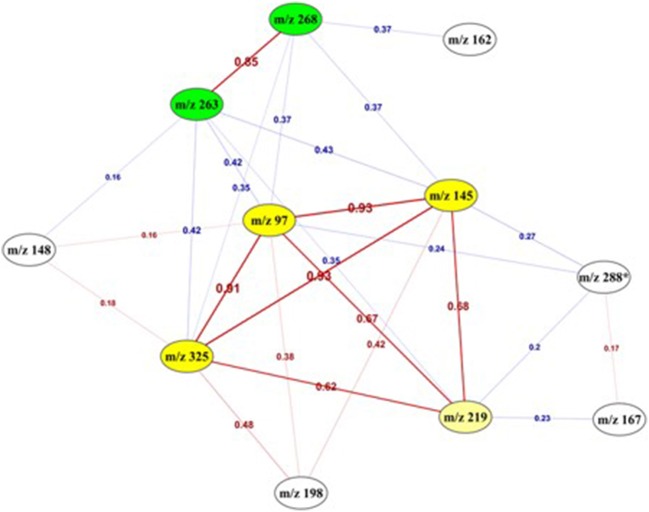
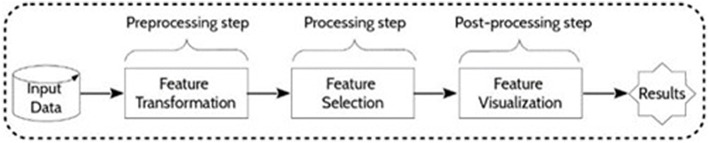
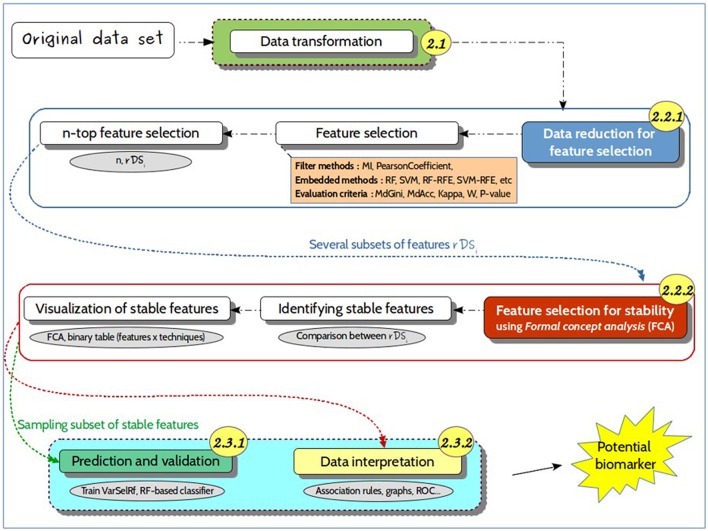
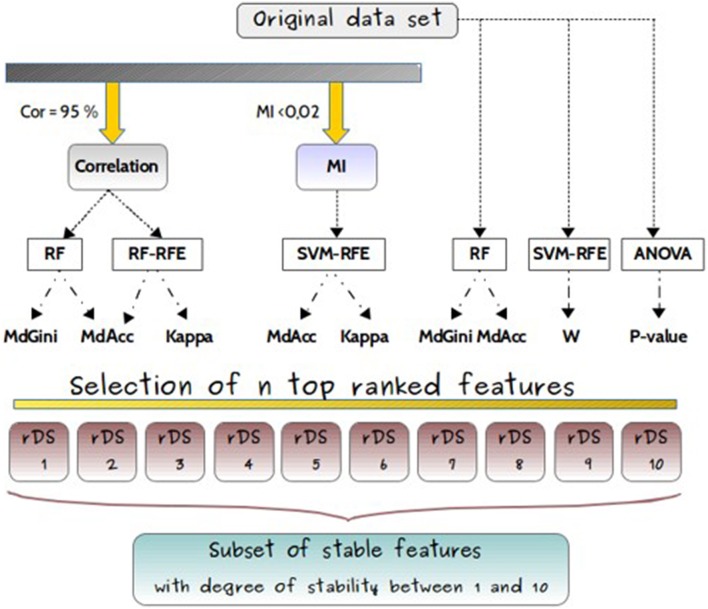
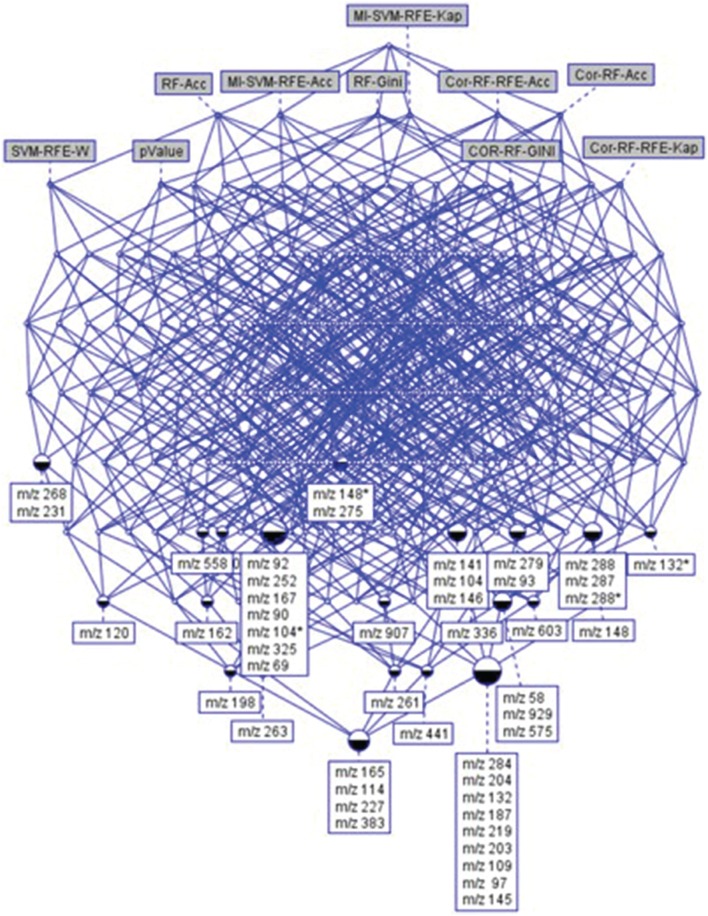
Untargeted metabolomics is a powerful phenotyping tool for better understanding biological mechanisms involved in human pathology development and identifying early predictive biomarkers. This approach, based on multiple analytical platforms, such as mass spectrometry (MS), chemometrics and bioinformatics, generates massive and complex data that need appropriate analyses to extract the biologically meaningful information. Despite various tools available, it is still a challenge to handle such large and noisy datasets with limited number of individuals without risking overfitting. Moreover, when the objective is focused on the identification of early predictive markers of clinical outcome, few years before occurrence, it becomes essential to use the appropriate algorithms and workflow to be able to discover subtle effects among this large amount of data. In this context, this work consists in studying a workflow describing the general feature selection process, using knowledge discovery and data mining methodologies to propose advanced solutions for predictive biomarker discovery. The strategy was focused on evaluating a combination of numeric-symbolic approaches for feature selection with the objective of obtaining the best combination of metabolites producing an effective and accurate predictive model. Relying first on numerical approaches, and especially on machine learning methods (SVM-RFE, RF, RF-RFE) and on univariate statistical analyses (ANOVA), a comparative study was performed on an original metabolomic dataset and reduced subsets. As resampling method, LOOCV was applied to minimize the risk of overfitting. The best k-features obtained with different scores of importance from the combination of these different approaches were compared and allowed determining the variable stabilities using Formal Concept Analysis. The results revealed the interest of RF-Gini combined with ANOVA for feature selection as these two complementary methods allowed selecting the 48 best candidates for prediction. Using linear logistic regression on this reduced dataset enabled us to obtain the best performances in terms of prediction accuracy and number of false positive with a model including 5 top variables. Therefore, these results highlighted the interest of feature selection methods and the importance of working on reduced datasets for the identification of predictive biomarkers issued from untargeted metabolomics data.
非靶向代谢组学是一种强大的表型工具,可用于更好地了解人类病理学发展中涉及的生物学机制,并识别早期预测性生物标志物。这种方法基于多种分析平台,如质谱(MS)、化学计量学和生物信息学,生成大量复杂的数据,需要进行适当的分析以提取有生物学意义的信息。尽管有各种可用的工具,但在没有过度拟合风险的情况下,处理个体数量有限的大型和嘈杂数据集仍然是一个挑战。此外,当目标是集中在识别临床结果的早期预测性生物标志物时,在发生前几年,使用适当的算法和工作流程来发现大量数据中的细微影响变得至关重要。在这种情况下,这项工作包括研究描述一般特征选择过程的工作流程,使用知识发现和数据挖掘方法来提出用于预测生物标志物发现的高级解决方案。该策略侧重于评估组合数值符号方法进行特征选择,目的是获得产生有效和准确预测模型的最佳代谢物组合。首先依赖于数值方法,特别是机器学习方法(SVM-RFE、RF、RF-RFE)和单变量统计分析(ANOVA),对原始代谢组学数据集和简化子集进行了比较研究。作为重采样方法,LOOCV 用于最小化过度拟合的风险。从这些不同方法的组合中获得的不同分数的重要性的最佳 k 个特征进行了比较,并使用形式概念分析确定了变量的稳定性。结果表明,RF-Gini 与 ANOVA 结合用于特征选择很有趣,因为这两种互补方法允许选择 48 个最佳预测候选物。在这个简化数据集上使用线性逻辑回归使我们能够获得最佳的预测准确性和假阳性数量的性能,模型包括 5 个顶级变量。因此,这些结果强调了特征选择方法的重要性以及针对从非靶向代谢组学数据中识别预测性生物标志物而处理简化数据集的重要性。