Machné Rainer, Murray Douglas B, Stadler Peter F
Institute for Synthetic Microbiology, Cluster of Excellence on Plant Sciences (CEPLAS), Heinrich Heine University Düsseldorf, Universitätsstraße 1, D-40225, Düsseldorf, Germany.
Department of Theoretical Chemistry of the University of Vienna, Währingerstrasse 17, Vienna, A-1090, Austria.
Sci Rep. 2017 Sep 27;7(1):12355. doi: 10.1038/s41598-017-12401-8.
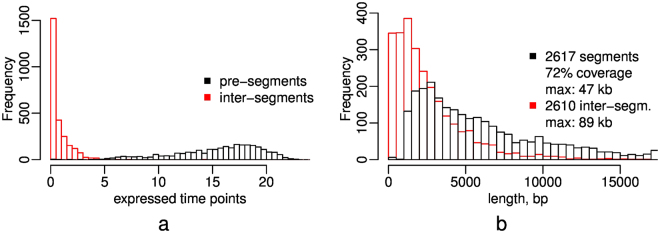
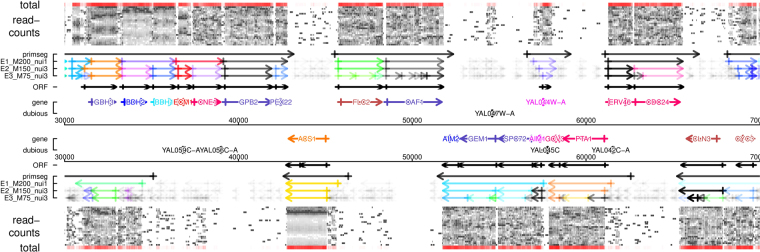
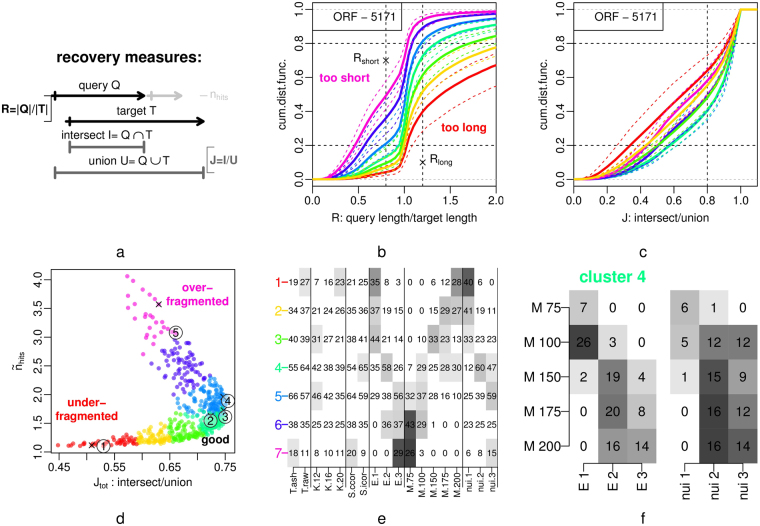
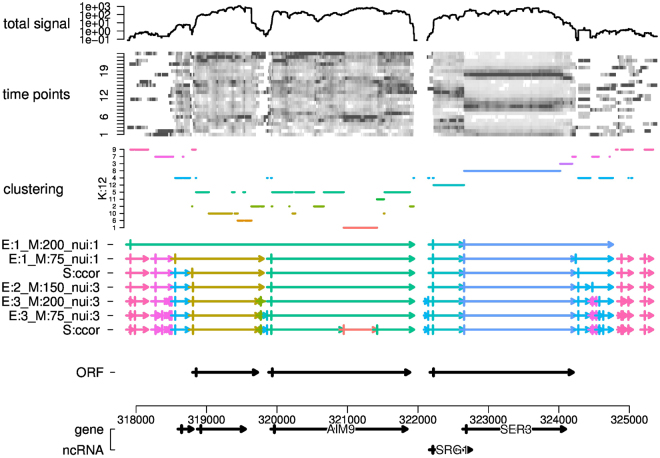
The segmentation of time series and genomic data is a common problem in computational biology. With increasingly complex measurement procedures individual data points are often not just numbers or simple vectors in which all components are of the same kind. Analysis methods that capitalize on slopes in a single real-valued data track or that make explicit use of the vectorial nature of the data are not applicable in such scenaria. We develop here a framework for segmentation in arbitrary data domains that only requires a minimal notion of similarity. Using unsupervised clustering of (a sample of) the input yields an approximate segmentation algorithm that is efficient enough for genome-wide applications. As a showcase application we segment a time-series of transcriptome sequencing data from budding yeast, in high temporal resolution over ca. 2.5 cycles of the short-period respiratory oscillation. The algorithm is used with a similarity measure focussing on periodic expression profiles across the metabolic cycle rather than coverage per time point.
时间序列和基因组数据的分割是计算生物学中的一个常见问题。随着测量程序日益复杂,单个数据点往往不只是数字或所有分量都属于同一类型的简单向量。利用单个实值数据轨迹中的斜率或明确利用数据的向量性质的分析方法在此类情况下并不适用。我们在此开发了一个用于任意数据域分割的框架,该框架仅需要最小的相似性概念。对输入(的一个样本)进行无监督聚类可产生一种近似分割算法,该算法对于全基因组应用而言效率足够高。作为一个展示应用,我们对来自芽殖酵母的转录组测序数据的时间序列进行分割,该数据具有高时间分辨率,跨越约2.5个短周期呼吸振荡循环。该算法使用的相似性度量侧重于代谢循环中的周期性表达谱,而非每个时间点的覆盖度。