Shi Jian-Yu, Li Jia-Xin, Gao Ke, Lei Peng, Yiu Siu-Ming
School of Life Sciences, Northwestern Polytechnical University, Xi'an, 710072, China.
School of Computer Science, Northwestern Polytechnical University, Xi'an, China.
BMC Bioinformatics. 2017 Oct 16;18(Suppl 12):409. doi: 10.1186/s12859-017-1818-2.
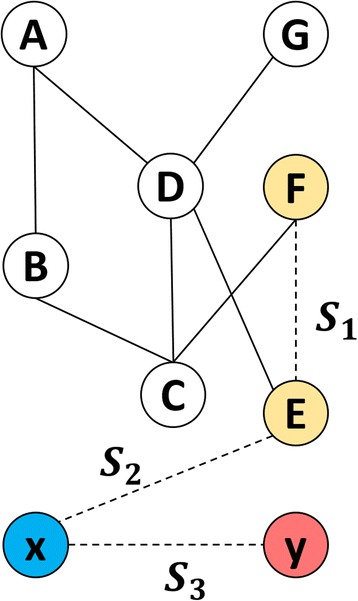
Drug Combination is one of the effective approaches for treating complex diseases. However, determining combinative drug pairs in clinical trials is still costly. Thus, computational approaches are used to identify potential drug pairs in advance. Existing computational approaches have the following shortcomings: (i) the lack of an effective integration of heterogeneous features leads to a time-consuming training and even results in an over-fitted classifier; and (ii) the narrow consideration of predicting potential drug combinations only among known drugs having known combinations cannot meet the demand of realistic screenings, which pay more attention to potential combinative pairs among newly-coming drugs that have no approved combination with other drugs at all.
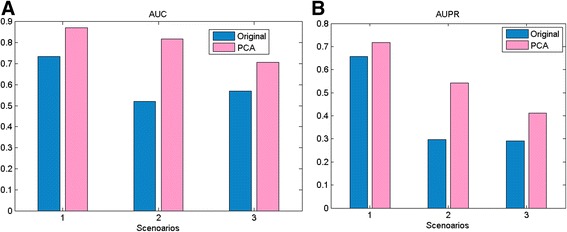
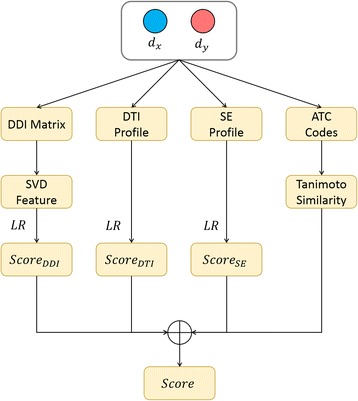
In this paper, to tackle the above two problems, we propose a novel drug-driven approach for predicting potential combinative pairs on a large scale. We define four new features based on heterogeneous data and design an efficient fusion scheme to integrate these feature. Moreover importantly, we elaborate appropriate cross-validations towards realistic screening scenarios of drug combinations involving both known drugs and new drugs. In addition, we perform an extra investigation to show how each kind of heterogeneous features is related to combinative drug pairs. The investigation inspires the design of our approach. Experiments on real data demonstrate the effectiveness of our fusion scheme for integrating heterogeneous features and its predicting power in three scenarios of realistic screening. In terms of both AUC and AUPR, the prediction among known drugs achieves 0.954 and 0.821, that between known drugs and new drugs achieves 0.909 and 0.635, and that among new drugs achieves 0.809 and 0.592 respectively.
Our approach provides not only an effective tool to integrate heterogeneous features but also the first tool to predict potential combinative pairs among new drugs.
药物联合是治疗复杂疾病的有效方法之一。然而,在临床试验中确定联合用药对的成本仍然很高。因此,采用计算方法提前识别潜在的药物对。现有的计算方法存在以下缺点:(i)缺乏对异构特征的有效整合导致训练耗时,甚至导致分类器过拟合;(ii)仅在已知有联合用药的已知药物之间预测潜在药物组合的考虑范围狭窄,无法满足实际筛选的需求,实际筛选更关注新出现的、与其他药物完全没有获批联合用药的潜在联合对。
在本文中,为了解决上述两个问题,我们提出了一种新颖的药物驱动方法,用于大规模预测潜在的联合对。我们基于异构数据定义了四个新特征,并设计了一种有效的融合方案来整合这些特征。更重要的是,我们针对涉及已知药物和新药的药物组合的实际筛选场景精心设计了适当的交叉验证。此外,我们进行了额外的研究,以展示每种异构特征与联合用药对的关系。该研究启发了我们方法的设计。对真实数据的实验证明了我们融合异构特征的方案在三种实际筛选场景中的有效性及其预测能力。在AUC和AUPR方面,已知药物之间的预测分别达到0.954和0.821,已知药物和新药之间的预测分别达到0.909和0.635,新药之间的预测分别达到0.809和0.592。
我们的方法不仅提供了一种整合异构特征的有效工具,而且是第一种预测新药之间潜在联合对的工具。