Department of Computer Engineering and Computer Science, University of Louisville, KY, USA.
Department of Electrical and Computer Engineering, University of Louisville, KY, USA.
Int J Med Inform. 2017 Dec;108:1-8. doi: 10.1016/j.ijmedinf.2017.09.013. Epub 2017 Sep 25.
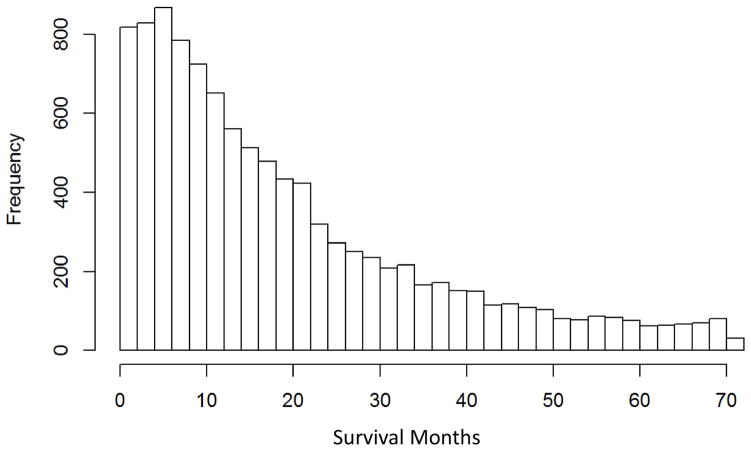
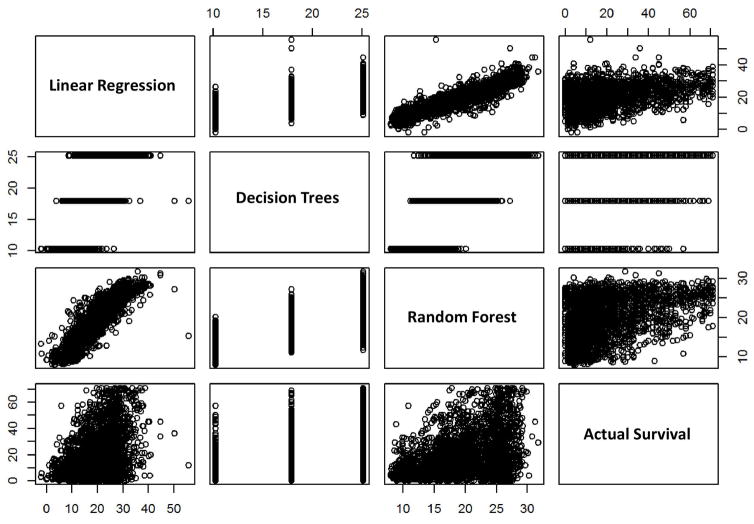
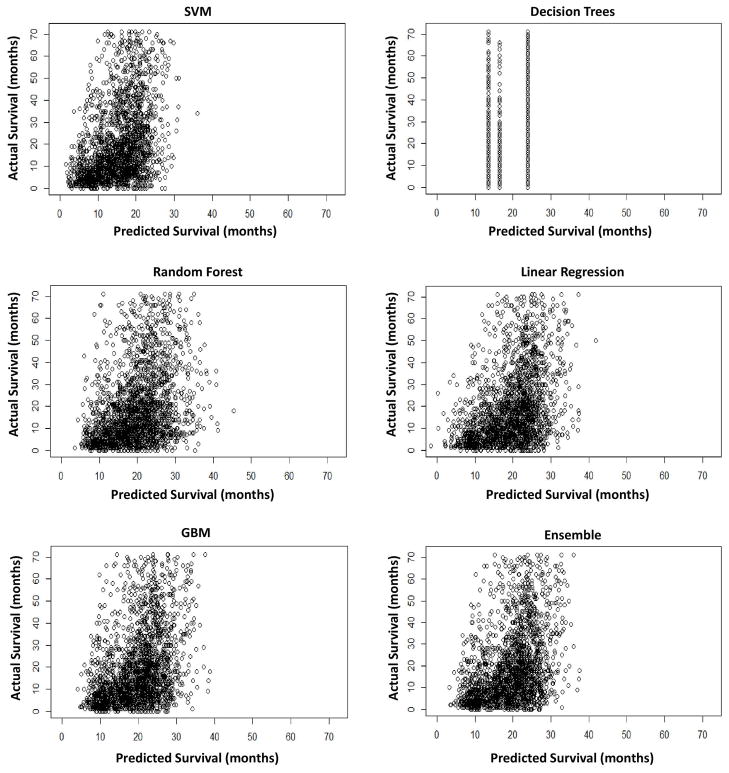
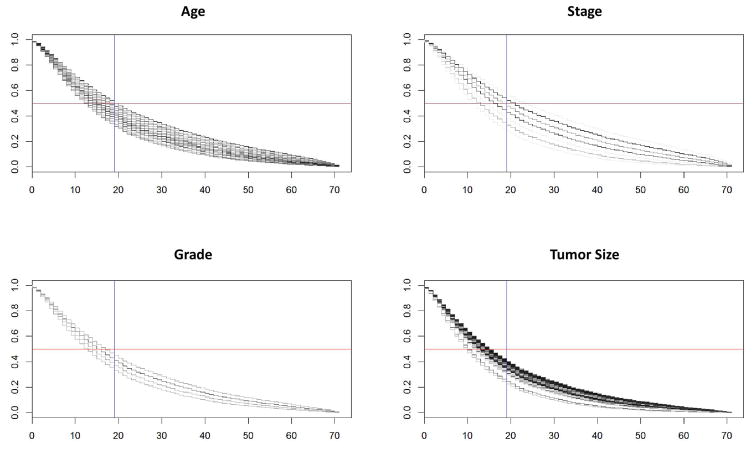
Outcomes for cancer patients have been previously estimated by applying various machine learning techniques to large datasets such as the Surveillance, Epidemiology, and End Results (SEER) program database. In particular for lung cancer, it is not well understood which types of techniques would yield more predictive information, and which data attributes should be used in order to determine this information. In this study, a number of supervised learning techniques is applied to the SEER database to classify lung cancer patients in terms of survival, including linear regression, Decision Trees, Gradient Boosting Machines (GBM), Support Vector Machines (SVM), and a custom ensemble. Key data attributes in applying these methods include tumor grade, tumor size, gender, age, stage, and number of primaries, with the goal to enable comparison of predictive power between the various methods The prediction is treated like a continuous target, rather than a classification into categories, as a first step towards improving survival prediction. The results show that the predicted values agree with actual values for low to moderate survival times, which constitute the majority of the data. The best performing technique was the custom ensemble with a Root Mean Square Error (RMSE) value of 15.05. The most influential model within the custom ensemble was GBM, while Decision Trees may be inapplicable as it had too few discrete outputs. The results further show that among the five individual models generated, the most accurate was GBM with an RMSE value of 15.32. Although SVM underperformed with an RMSE value of 15.82, statistical analysis singles the SVM as the only model that generated a distinctive output. The results of the models are consistent with a classical Cox proportional hazards model used as a reference technique. We conclude that application of these supervised learning techniques to lung cancer data in the SEER database may be of use to estimate patient survival time with the ultimate goal to inform patient care decisions, and that the performance of these techniques with this particular dataset may be on par with that of classical methods.
先前,人们已经通过将各种机器学习技术应用于大型数据集(如监测、流行病学和最终结果 (SEER) 计划数据库)来估计癌症患者的预后。特别是对于肺癌,人们还不太清楚哪种类型的技术可以提供更多的预测信息,以及为了确定这些信息应该使用哪些数据属性。在这项研究中,将多种监督学习技术应用于 SEER 数据库,根据生存情况对肺癌患者进行分类,包括线性回归、决策树、梯度提升机 (GBM)、支持向量机 (SVM) 和自定义集成。应用这些方法的关键数据属性包括肿瘤等级、肿瘤大小、性别、年龄、阶段和原发灶数量,目的是比较各种方法的预测能力。该预测被视为连续目标,而不是分类为类别,作为提高生存预测的第一步。结果表明,预测值与低至中度生存时间的实际值相符,这构成了数据的大部分。表现最好的技术是自定义集成,其均方根误差 (RMSE) 值为 15.05。在自定义集成中,最有影响力的模型是 GBM,而决策树可能不适用,因为它的离散输出太少。结果进一步表明,在生成的五个单独模型中,最准确的是 GBM,其 RMSE 值为 15.32。尽管 SVM 的 RMSE 值为 15.82,但表现不佳,但统计分析表明,SVM 是唯一生成独特输出的模型。模型的结果与用作参考技术的经典 Cox 比例风险模型一致。我们得出结论,将这些监督学习技术应用于 SEER 数据库中的肺癌数据,可能有助于估计患者的生存时间,最终目标是为患者护理决策提供信息,并且这些技术在特定数据集上的性能可能与经典方法相当。