Department of Computer Engineering, Urmia University, Urmia, Iran.
Center for Health Informatics and Technology, The Maersk Mc-Kinney Moller Institute, University of Southern Denmark, Odense, Denmark.
BMC Med Inform Decis Mak. 2022 Dec 30;22(1):345. doi: 10.1186/s12911-022-02087-y.
Ovarian cancer is the fifth leading cause of mortality among women in the United States. Ovarian cancer is also known as forgotten cancer or silent disease. The survival of ovarian cancer patients depends on several factors, including the treatment process and the prognosis.
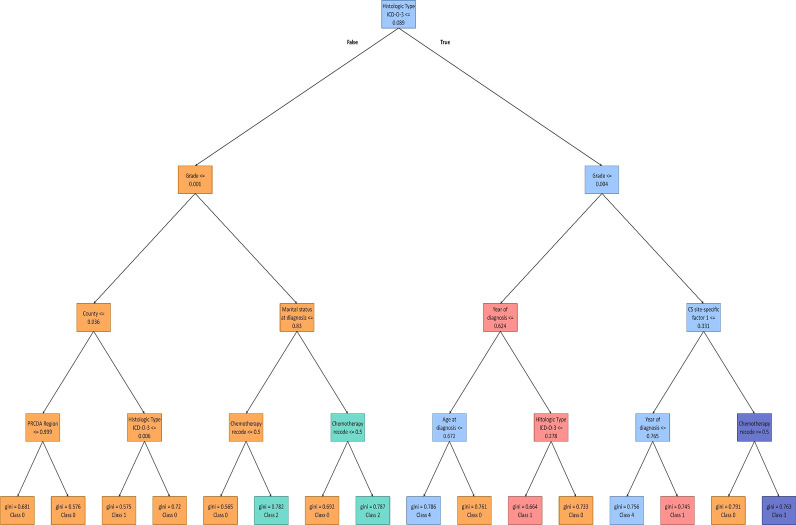
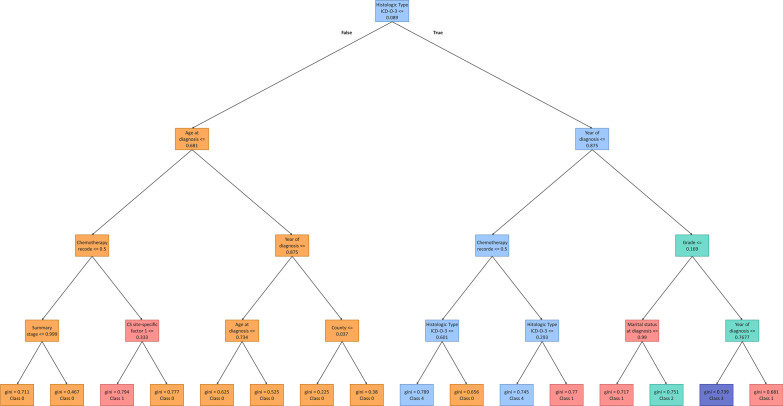
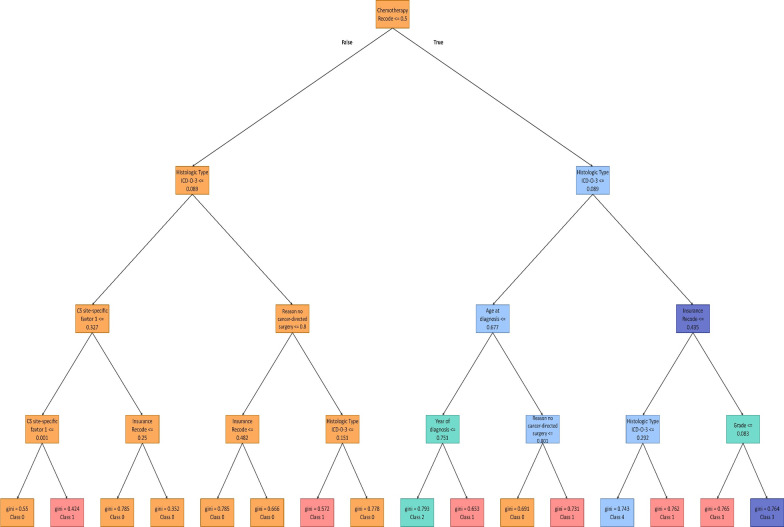
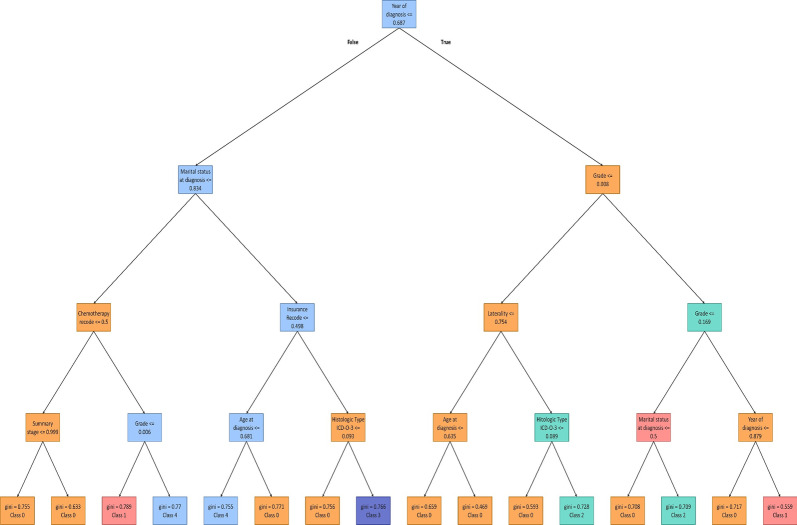
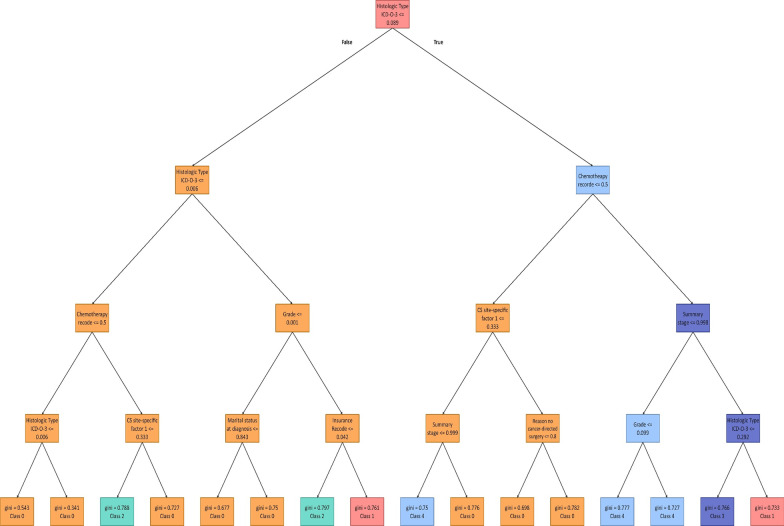
The ovarian cancer patients' dataset is compiled from the Surveillance, Epidemiology, and End Results (SEER) database. With the help of a clinician, the dataset is curated, and the most relevant features are selected. Pearson's second coefficient of skewness test is used to evaluate the skewness of the dataset. Pearson correlation coefficient is also used to investigate the associations between features. Statistical test is utilized to evaluate the significance of the features. Six Machine Learning (ML) models, including K-Nearest Neighbors , Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), Adaptive Boosting (AdaBoost), and Extreme Gradient Boosting (XGBoost), are implemented for survival prediction in both classification and regression approaches. An interpretable method, Shapley Additive Explanations (SHAP), is applied to clarify the decision-making process and determine the importance of each feature in prediction. Additionally, DTs of the RF model are displayed to show how the model predicts the survival intervals.
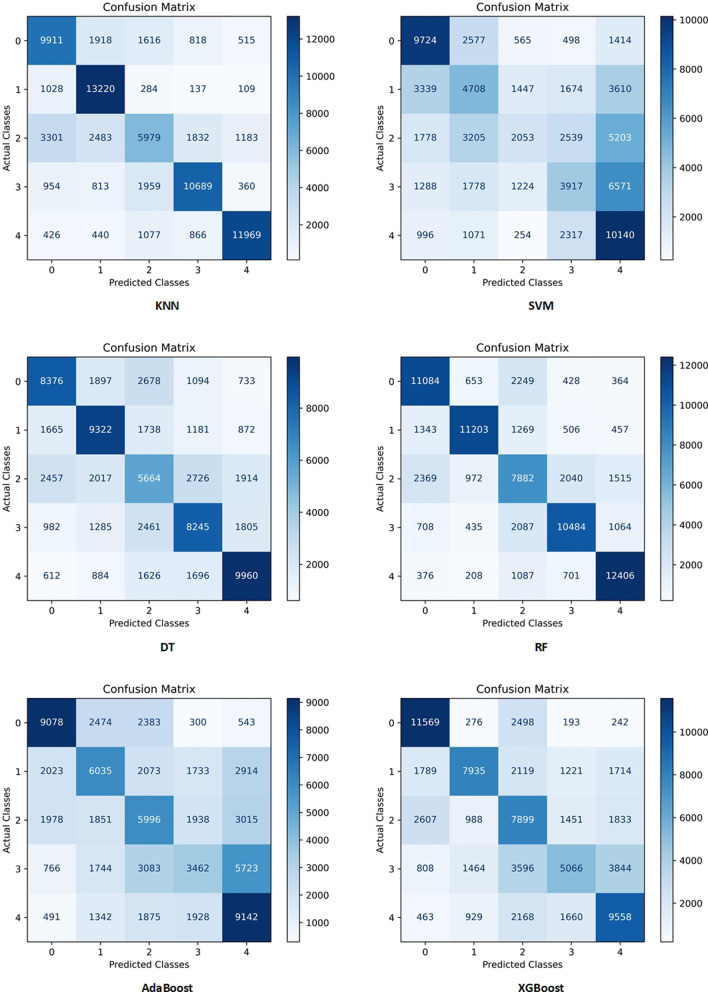
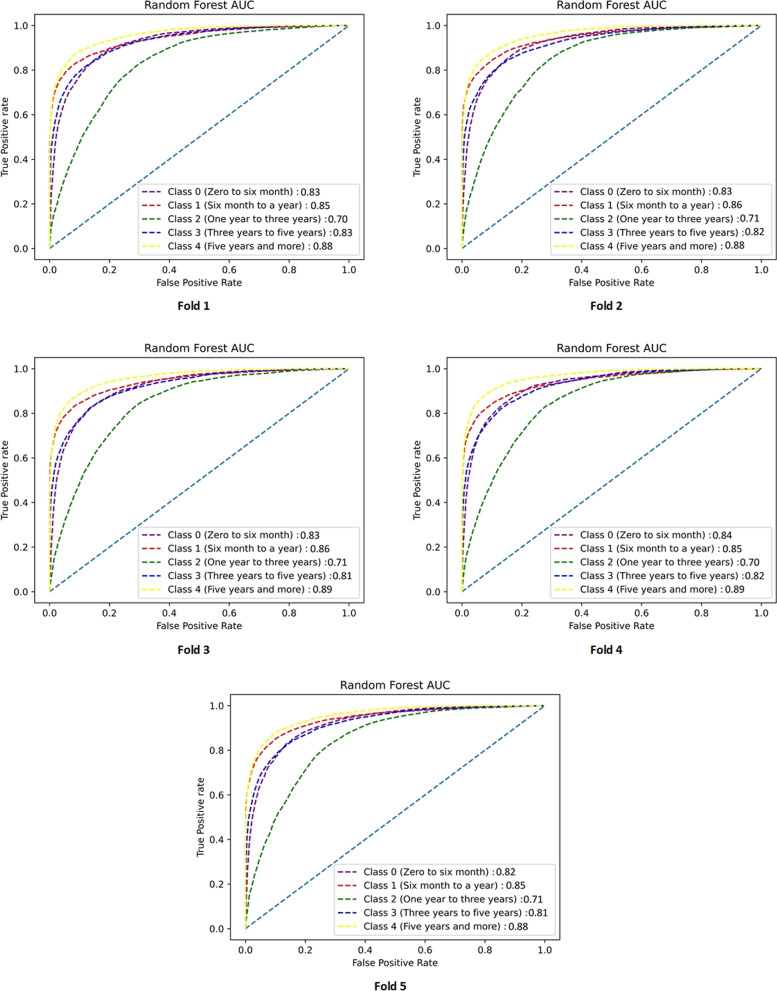
Our results show that RF (Accuracy = 88.72%, AUC = 82.38%) and XGBoost (Root Mean Squad Error (RMSE)) = 20.61%, R = 0.4667) have the best performance for classification and regression approaches, respectively. Furthermore, using the SHAP method along with extracted DTs of the RF model, the most important features in the dataset are identified. Histologic type ICD-O-3, chemotherapy recode, year of diagnosis, age at diagnosis, tumor stage, and grade are the most important determinant factors in survival prediction.
To the best of our knowledge, our study is the first study that develops various ML models to predict ovarian cancer patients' survival on the SEER database in both classification and regression approaches. These ML algorithms also achieve more accurate results and outperform statistical methods. Furthermore, our study is the first study to use the SHAP method to increase confidence and transparency of the proposed models' prediction for clinicians. Moreover, our developed models, as an automated auxiliary tool, can help clinicians to have a better understanding of the estimated survival as well as important features that affect survival.
卵巢癌是美国女性死亡的第五大主要原因。卵巢癌也被称为被遗忘的癌症或无声的疾病。卵巢癌患者的生存取决于多个因素,包括治疗过程和预后。
卵巢癌患者数据集是从监测、流行病学和最终结果(SEER)数据库中编译而来的。在临床医生的帮助下,对数据集进行了整理,并选择了最相关的特征。使用皮尔逊第二偏度系数检验来评估数据集的偏度。还使用皮尔逊相关系数来研究特征之间的相关性。统计检验用于评估特征的显著性。实施了六种机器学习(ML)模型,包括 K-最近邻、支持向量机(SVM)、决策树(DT)、随机森林(RF)、自适应提升(AdaBoost)和极端梯度提升(XGBoost),以进行分类和回归方法的生存预测。应用可解释方法 Shapley 加性解释(SHAP)来阐明决策过程,并确定预测中每个特征的重要性。此外,还显示了 RF 模型的 DT,以显示模型如何预测生存间隔。
我们的结果表明,RF(准确度=88.72%,AUC=82.38%)和 XGBoost(均方根误差(RMSE)=20.61%,R=0.4667)在分类和回归方法中分别具有最佳性能。此外,使用 SHAP 方法以及 RF 模型提取的 DT,可以确定数据集中最重要的特征。组织学类型 ICD-O-3、化疗编码、诊断年份、诊断时的年龄、肿瘤分期和分级是生存预测中最重要的决定因素。
据我们所知,我们的研究是第一项在 SEER 数据库中使用各种 ML 模型进行分类和回归方法的卵巢癌患者生存预测的研究。这些 ML 算法还实现了更准确的结果,并优于统计方法。此外,我们的研究是第一项使用 SHAP 方法来提高临床医生对所提出模型预测的信心和透明度的研究。此外,我们开发的模型作为一种自动化辅助工具,可以帮助临床医生更好地了解估计的生存以及影响生存的重要特征。