Mohammed Akram, Biegert Greyson, Adamec Jiri, Helikar Tomáš
Department of Biochemistry, University of Nebraska-Lincoln, Lincoln, Nebraska, United States of America.
Oncotarget. 2017 Dec 20;9(2):2565-2573. doi: 10.18632/oncotarget.23511. eCollection 2018 Jan 5.
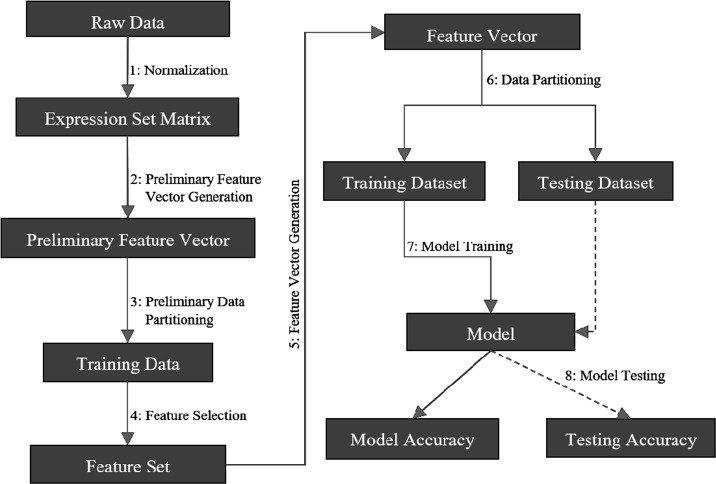
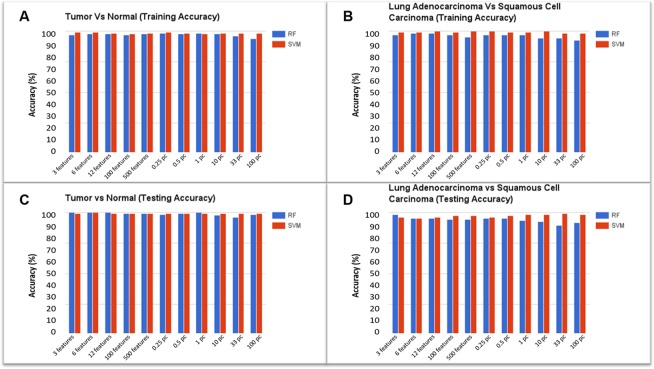
Accurate identification of cancer biomarkers and classification of cancer type and subtype from High Throughput Sequencing (HTS) data is a challenging problem because it requires manual processing of raw HTS data from various sequencing platforms, quality control, and normalization, which are both tedious and time-consuming. Machine learning techniques for cancer class prediction and biomarker discovery can hasten cancer detection and significantly improve prognosis. To date, great research efforts have been taken for cancer biomarker identification and cancer class prediction. However, currently available tools and pipelines lack flexibility in data preprocessing, running multiple feature selection methods and learning algorithms, therefore, developing a freely available and easy-to-use program is strongly demanded by researchers. Here, we propose CancerDiscover, an integrative open-source software pipeline that allows users to automatically and efficiently process large high-throughput raw datasets, normalize, and selects best performing features from multiple feature selection algorithms. Additionally, the integrative pipeline lets users apply different feature thresholds to identify cancer biomarkers and build various training models to distinguish different types and subtypes of cancer. The open-source software is available at https://github.com/HelikarLab/CancerDiscover and is free for use under the GPL3 license.
从高通量测序(HTS)数据中准确识别癌症生物标志物以及对癌症类型和亚型进行分类是一个具有挑战性的问题,因为这需要对来自各种测序平台的原始HTS数据进行人工处理、质量控制和标准化,这些工作既繁琐又耗时。用于癌症类别预测和生物标志物发现的机器学习技术可以加快癌症检测并显著改善预后。迄今为止,在癌症生物标志物识别和癌症类别预测方面已经进行了大量的研究工作。然而,目前可用的工具和流程在数据预处理、运行多种特征选择方法和学习算法方面缺乏灵活性,因此,研究人员强烈需要开发一个免费且易于使用的程序。在此,我们提出了CancerDiscover,这是一个集成的开源软件流程,允许用户自动高效地处理大型高通量原始数据集,进行标准化,并从多种特征选择算法中选择性能最佳的特征。此外,该集成流程允许用户应用不同的特征阈值来识别癌症生物标志物,并构建各种训练模型以区分不同类型和亚型的癌症。该开源软件可在https://github.com/HelikarLab/CancerDiscover获取,并且在GPL3许可下可免费使用。