Department of Biology, ETH Zurich, Zürich, Switzerland.
Department of Chemistry and Chemical Biology, Northeastern University, Boston, Massachusetts, USA.
Nat Chem Biol. 2018 Feb 14;14(3):206-214. doi: 10.1038/nchembio.2576.
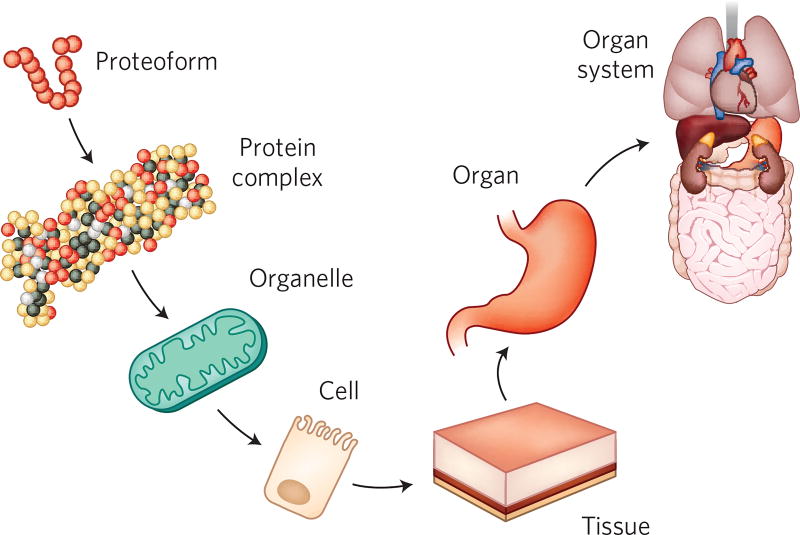
Despite decades of accumulated knowledge about proteins and their post-translational modifications (PTMs), numerous questions remain regarding their molecular composition and biological function. One of the most fundamental queries is the extent to which the combinations of DNA-, RNA- and PTM-level variations explode the complexity of the human proteome. Here, we outline what we know from current databases and measurement strategies including mass spectrometry-based proteomics. In doing so, we examine prevailing notions about the number of modifications displayed on human proteins and how they combine to generate the protein diversity underlying health and disease. We frame central issues regarding determination of protein-level variation and PTMs, including some paradoxes present in the field today. We use this framework to assess existing data and to ask the question, "How many distinct primary structures of proteins (proteoforms) are created from the 20,300 human genes?" We also explore prospects for improving measurements to better regularize protein-level biology and efficiently associate PTMs to function and phenotype.
尽管人们对蛋白质及其翻译后修饰(PTMs)已经积累了数十年的知识,但关于它们的分子组成和生物学功能仍有许多问题尚未解决。其中最基本的问题之一是,DNA、RNA 和 PTM 水平变化的组合在多大程度上使人类蛋白质组的复杂性呈爆炸式增长。在这里,我们概述了从当前数据库和测量策略(包括基于质谱的蛋白质组学)中了解到的情况。在这样做的过程中,我们检查了关于人类蛋白质上显示的修饰数量的流行观念,以及它们如何组合生成健康和疾病背后的蛋白质多样性。我们构建了关于确定蛋白质水平变化和 PTM 的核心问题,包括该领域当前存在的一些悖论。我们使用这个框架来评估现有数据,并提出问题,“从 20300 个人类基因中创建了多少种不同的蛋白质(蛋白异构体)一级结构?”我们还探讨了改善测量的前景,以更好地规范蛋白质水平生物学并将 PTM 有效地关联到功能和表型。