From the Department of Anesthesiology, VU University Medical Center, Amsterdam, the Netherlands.
Department of Surgery and Perioperative Care, Dell Medical School at the University of Texas at Austin, Austin, Texas.
Anesth Analg. 2018 Aug;127(2):569-575. doi: 10.1213/ANE.0000000000003511.
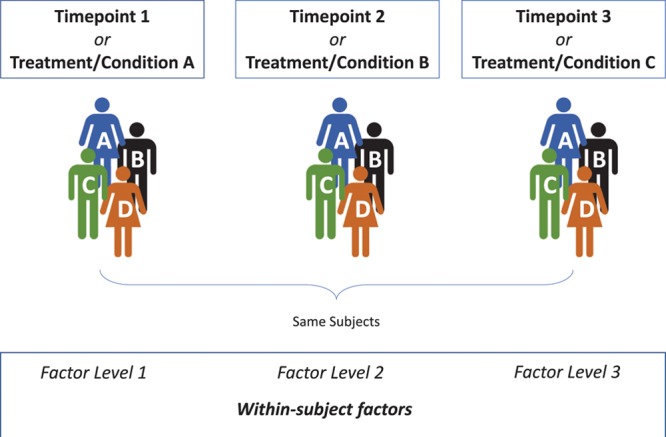
Anesthesia, critical care, perioperative, and pain research often involves study designs in which the same outcome variable is repeatedly measured or observed over time on the same patients. Such repeatedly measured data are referred to as longitudinal data, and longitudinal study designs are commonly used to investigate changes in an outcome over time and to compare these changes among treatment groups. From a statistical perspective, longitudinal studies usually increase the precision of estimated treatment effects, thus increasing the power to detect such effects. Commonly used statistical techniques mostly assume independence of the observations or measurements. However, values repeatedly measured in the same individual will usually be more similar to each other than values of different individuals and ignoring the correlation between repeated measurements may lead to biased estimates as well as invalid P values and confidence intervals. Therefore, appropriate analysis of repeated-measures data requires specific statistical techniques. This tutorial reviews 3 classes of commonly used approaches for the analysis of longitudinal data. The first class uses summary statistics to condense the repeatedly measured information to a single number per subject, thus basically eliminating within-subject repeated measurements and allowing for a straightforward comparison of groups using standard statistical hypothesis tests. The second class is historically popular and comprises the repeated-measures analysis of variance type of analyses. However, strong assumptions that are seldom met in practice and low flexibility limit the usefulness of this approach. The third class comprises modern and flexible regression-based techniques that can be generalized to accommodate a wide range of outcome data including continuous, categorical, and count data. Such methods can be further divided into so-called "population-average statistical models" that focus on the specification of the mean response of the outcome estimated by generalized estimating equations, and "subject-specific models" that allow a full specification of the distribution of the outcome by using random effects to capture within-subject correlations. The choice as to which approach to choose partly depends on the aim of the research and the desired interpretation of the estimated effects (population-average versus subject-specific interpretation). This tutorial discusses aspects of the theoretical background for each technique, and with specific examples of studies published in Anesthesia & Analgesia, demonstrates how these techniques are used in practice.
麻醉、重症监护、围手术期和疼痛研究通常涉及研究设计,其中相同的结果变量在同一患者身上随着时间的推移被重复测量或观察。这种重复测量的数据被称为纵向数据,纵向研究设计通常用于研究随着时间的推移,结果的变化,并比较治疗组之间的这些变化。从统计学的角度来看,纵向研究通常可以提高估计治疗效果的精度,从而提高检测这些效果的能力。常用的统计技术大多假设观察值或测量值是独立的。然而,在同一个个体中重复测量的值通常比不同个体的值更相似,忽略重复测量之间的相关性可能会导致有偏差的估计以及无效的 P 值和置信区间。因此,对重复测量数据的适当分析需要特定的统计技术。本教程回顾了常用于分析纵向数据的 3 类常用方法。第一类方法使用汇总统计数据将重复测量的信息压缩到每个受试者的单个数字中,从而基本上消除了个体内的重复测量,并允许使用标准统计假设检验对组进行直接比较。第二类方法历史上很流行,包括重复测量方差分析类型的分析。然而,在实践中很少满足的强假设和低灵活性限制了这种方法的有用性。第三类方法包括基于现代和灵活的回归的技术,这些技术可以推广到包括连续、分类和计数数据在内的广泛的结果数据。这种方法可以进一步分为所谓的“群体平均统计模型”,重点是通过广义估计方程估计的结果的平均响应的规范,以及“个体特定模型”,允许通过使用随机效应来捕获个体内相关性来充分规范结果的分布。选择采用哪种方法在一定程度上取决于研究的目的和对估计效果的期望解释(群体平均解释与个体特定解释)。本教程讨论了每种技术的理论背景的各个方面,并以发表在《麻醉与镇痛》杂志上的研究的具体实例为例,展示了如何在实践中使用这些技术。