Department of Computer Science, Sangmyung University, Seoul, South Korea.
PLoS One. 2018 Aug 3;13(8):e0201933. doi: 10.1371/journal.pone.0201933. eCollection 2018.
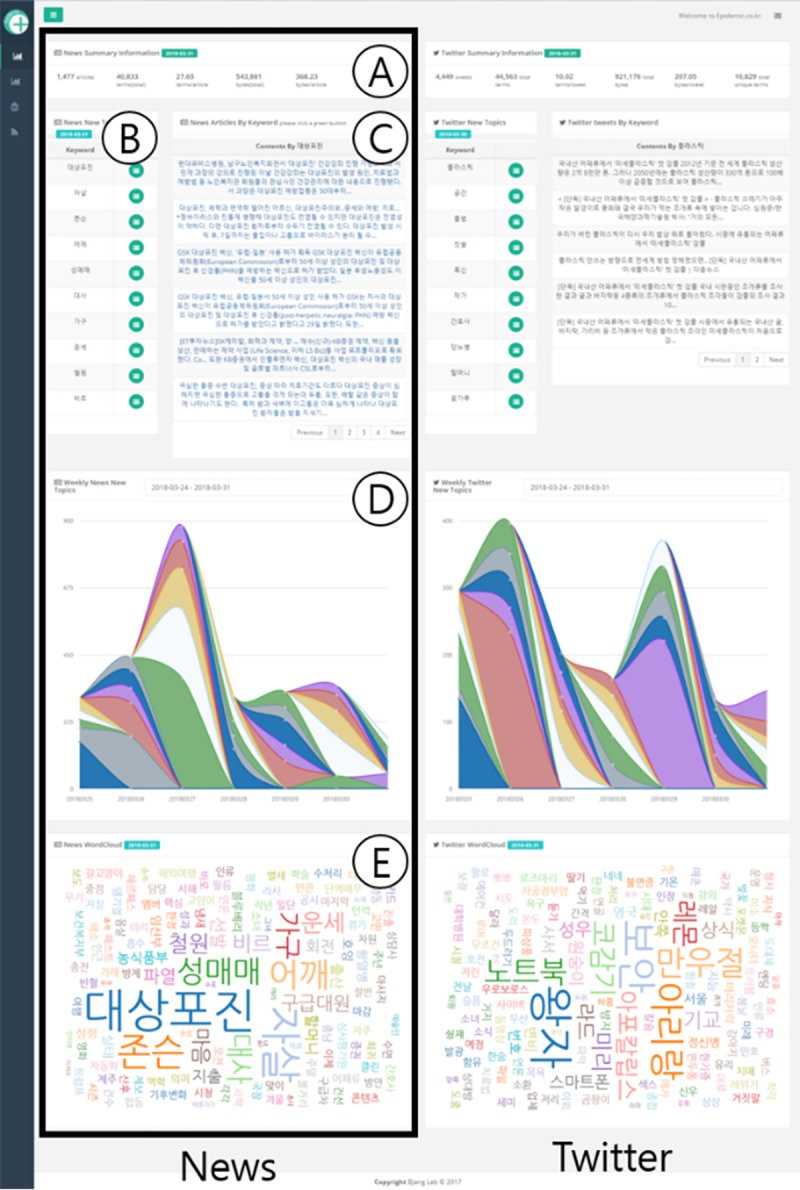
This paper describes the web-based automated disease-related topic extraction system, called to DiTeX, which monitors important disease-related topics and provides associated information. National disease surveillance systems require a considerable amount of time to inform people of recent outbreaks of diseases. To solve this problem, many studies have used Internet-based sources such as news and Social Network Service (SNS). However, these sources contain many intentional elements that disturb extracting important topics. To address this challenge, we employ Natural Language Processing and an effective ranking algorithm, and develop DiTeX that provides important disease-related topics. This report describes the web front-end and back-end architecture, implementation, performance of the ranking algorithm, and captured topics of DiTeX. We describe processes for collecting Internet-based data and extracting disease-related topics based on search keywords. Our system then applies a ranking algorithm to evaluate the importance of disease-related topics extracted from these data. Finally, we conduct analysis based on real-world incidents to evaluate the performance and the effectiveness of DiTeX. To evaluate DiTeX, we analyze the ranking of well-known disease-related incidents for various ranking algorithms. The topic extraction rate of our ranking algorithm is superior to those of others. We demonstrate the validity of DiTeX by summarizing the disease-related topics of each day extracted by our system. To our knowledge, DiTeX is the world's first automated web-based real-time service system that extracts and presents disease-related topics, trends and related data through web-based sources. DiTeX is now available on the web through http://epidemic.co.kr/media/topics.
本文描述了一个基于网络的自动化疾病相关主题提取系统,称为 DiTeX,它可以监测重要的疾病相关主题,并提供相关信息。国家疾病监测系统需要相当长的时间来告知人们最近的疾病爆发情况。为了解决这个问题,许多研究都使用了基于互联网的来源,如新闻和社交网络服务 (SNS)。然而,这些来源包含了许多干扰提取重要主题的故意元素。为了解决这个挑战,我们使用了自然语言处理和有效的排名算法,并开发了 DiTeX,提供了重要的疾病相关主题。本报告描述了 DiTeX 的网络前端和后端架构、实现、排名算法的性能以及捕获的主题。我们描述了基于搜索关键字从互联网数据中提取疾病相关主题的过程。我们的系统然后应用排名算法来评估从这些数据中提取的疾病相关主题的重要性。最后,我们根据真实事件进行分析,以评估 DiTeX 的性能和有效性。为了评估 DiTeX,我们分析了各种排名算法中著名疾病相关事件的排名。我们的排名算法的主题提取率优于其他算法。我们通过总结我们系统每天提取的疾病相关主题来证明 DiTeX 的有效性。据我们所知,D iTeX 是世界上第一个通过基于网络的实时服务系统,通过基于网络的来源提取和呈现疾病相关主题、趋势和相关数据。D iTeX 现在可以通过 http://epidemic.co.kr/media/topics 在网络上访问。