Donoho David L, Gavish Matan, Johnstone Iain M
Department of Statistics, Stanford University.
School of Computer Science and Engineering, Hebrew University of Jerusalem.
Ann Stat. 2018 Aug;46(4):1742-1778. doi: 10.1214/17-AOS1601. Epub 2018 Jun 27.
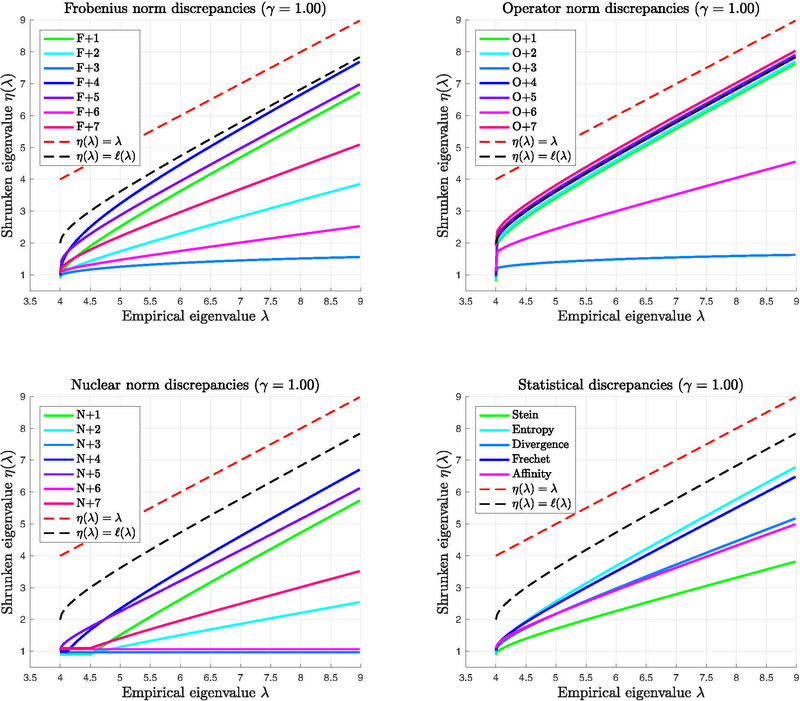
We show that in a common high-dimensional covariance model, the choice of loss function has a profound effect on optimal estimation. In an asymptotic framework based on the Spiked Covariance model and use of orthogonally invariant estimators, we show that optimal estimation of the population covariance matrix boils down to design of an optimal shrinker that acts elementwise on the sample eigenvalues. Indeed, to each loss function there corresponds a unique admissible eigenvalue shrinker * dominating all other shrinkers. The shape of the optimal shrinker is determined by the choice of loss function and, crucially, by inconsistency of both eigenvalues eigenvectors of the sample covariance matrix. Details of these phenomena and closed form formulas for the optimal eigenvalue shrinkers are worked out for a menagerie of 26 loss functions for covariance estimation found in the literature, including the Stein, Entropy, Divergence, Fréchet, Bhattacharya/Matusita, Frobenius Norm, Operator Norm, Nuclear Norm and Condition Number losses.
我们表明,在一个常见的高维协方差模型中,损失函数的选择对最优估计有深远影响。在基于尖峰协方差模型的渐近框架以及使用正交不变估计器的情况下,我们表明总体协方差矩阵的最优估计归结为设计一个对样本特征值逐元素起作用的最优收缩器。实际上,对于每个损失函数,都对应一个唯一的可容许特征值收缩器*,它优于所有其他收缩器。最优收缩器的形状由损失函数的选择决定,关键是由样本协方差矩阵的特征值和特征向量的不一致性决定。对于文献中发现的用于协方差估计的26种损失函数,包括斯坦因、熵、散度、弗雷歇、巴塔查里亚/马图西塔、弗罗贝尼乌斯范数、算子范数、核范数和条件数损失,详细阐述了这些现象以及最优特征值收缩器的闭式公式。