Department of Cardiology, Amsterdam UMC, Vrije Universiteit Amsterdam, Amsterdam, the Netherlands.
HorAIzon BV, Rotterdam, the Netherlands; Department of Vascular Medicine, Amsterdam UMC, University of Amsterdam, Amsterdam, the Netherlands.
EBioMedicine. 2019 Jan;39:109-117. doi: 10.1016/j.ebiom.2018.12.033. Epub 2018 Dec 23.
Risk stratification is crucial to improve tailored therapy in patients with suspected coronary artery disease (CAD). This study investigated the ability of targeted proteomics to predict presence of high-risk plaque or absence of coronary atherosclerosis in patients with suspected CAD, defined by coronary computed tomography angiography (CCTA).
Patients with suspected CAD (n = 203) underwent CCTA. Plasma levels of 358 proteins were used to generate machine learning models for the presence of CCTA-defined high-risk plaques or complete absence of coronary atherosclerosis. Performance was tested against a clinical model containing generally available clinical characteristics and conventional biomarkers.
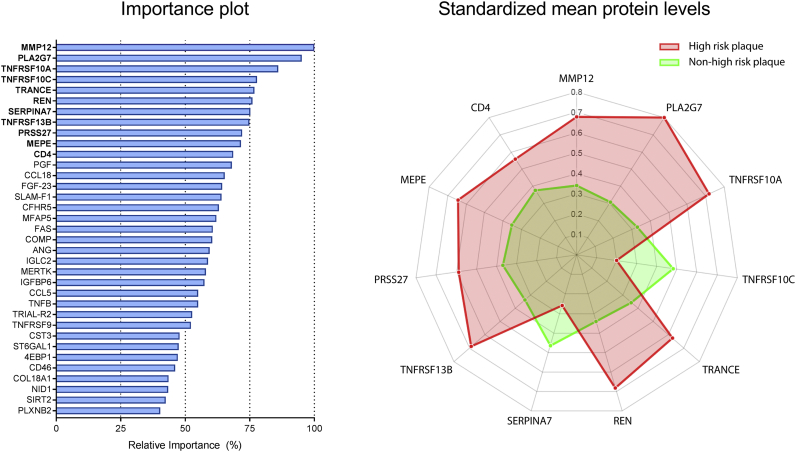
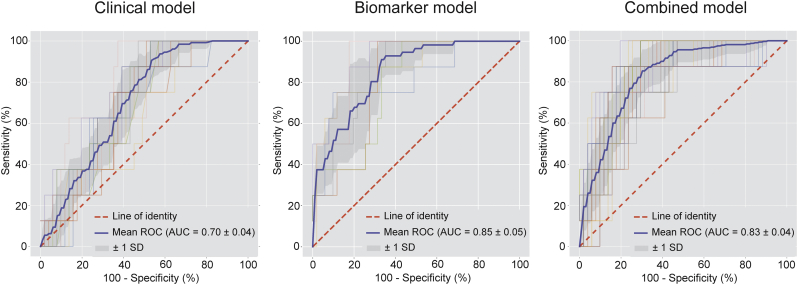
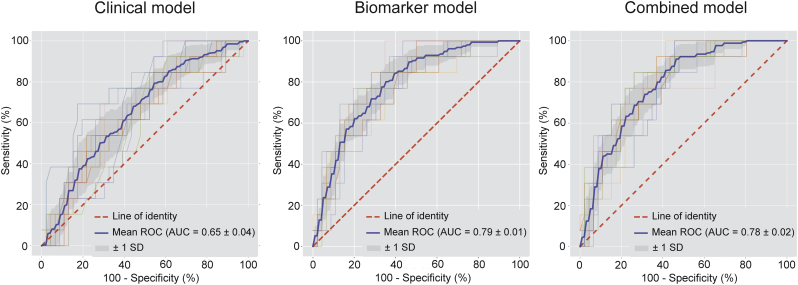
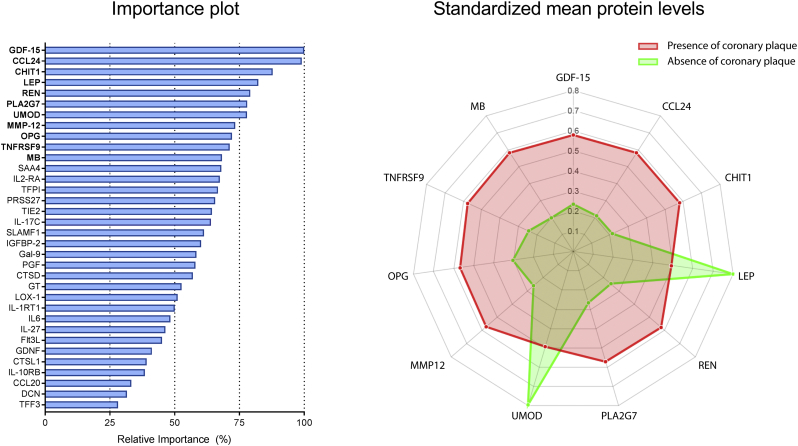
A total of 196 patients with analyzable protein levels (n = 332) was included for analysis. A subset of 35 proteins was identified predicting the presence of high-risk plaques. The developed machine learning model had fair diagnostic performance with an area under the curve (AUC) of 0·79 ± 0·01, outperforming prediction with generally available clinical characteristics (AUC = 0·65 ± 0·04, p < 0·05). Conversely, a different subset of 34 proteins was predictive for the absence of CAD (AUC = 0·85 ± 0·05), again outperforming prediction with generally available characteristics (AUC = 0·70 ± 0·04, p < 0·05).
Using machine learning models, trained on targeted proteomics, we defined two complementary protein signatures: one for identification of patients with high-risk plaques and one for identification of patients with absence of CAD. Both biomarker subsets were superior to generally available clinical characteristics and conventional biomarkers in predicting presence of high-risk plaque or absence of coronary atherosclerosis. These promising findings warrant external validation of the value of targeted proteomics to identify cardiovascular risk in outcome studies. FUND: This study was supported by an unrestricted research grant from HeartFlow Inc. and partly supported by a European Research Area Network on Cardiovascular Diseases (ERA-CVD) grant (ERA CVD JTC2017, OPERATION). Funders had no influence on trial design, data evaluation, and interpretation.
风险分层对于改善疑似冠心病(CAD)患者的靶向治疗至关重要。本研究通过冠状动脉计算机断层扫描血管造影(CCTA)来探讨靶向蛋白质组学预测疑似 CAD 患者(定义为)高危斑块存在或冠状动脉粥样硬化缺失的能力。
对 203 例疑似 CAD 患者进行 CCTA。利用 358 种蛋白的血浆水平生成机器学习模型,以预测 CCTA 定义的高危斑块的存在或冠状动脉粥样硬化的完全缺失。通过包含通常可用的临床特征和常规生物标志物的临床模型来测试性能。
共纳入了 196 例具有可分析蛋白水平的患者(n=332)进行分析。鉴定出一组 35 种蛋白,可预测高危斑块的存在。开发的机器学习模型具有较好的诊断性能,曲线下面积(AUC)为 0.79±0.01,优于通常可用的临床特征预测(AUC=0.65±0.04,p<0.05)。相反,另一组 34 种蛋白可预测 CAD 的缺失(AUC=0.85±0.05),同样优于通常可用的特征预测(AUC=0.70±0.04,p<0.05)。
使用基于机器学习的靶向蛋白质组学模型,我们定义了两个互补的蛋白质特征:一个用于识别高危斑块患者,另一个用于识别无 CAD 患者。这两个生物标志物子集在预测高危斑块或冠状动脉粥样硬化缺失的存在方面均优于通常可用的临床特征和常规生物标志物。这些有希望的发现需要在预后研究中对靶向蛋白质组学识别心血管风险的价值进行外部验证。
本研究得到了 HeartFlow Inc. 的一项不受限制的研究资助,部分得到了心血管疾病欧洲研究区网络(ERA-CVD)的资助(ERA CVD JTC2017,OPERATION)。资助者对试验设计、数据评估和解释没有影响。