Associação Fraunhofer Portugal Research, Rua Alfredo Allen 455/461, 4200-135 Porto, Portugal.
Laboratório de Instrumentação, Engenharia Biomédica e Física da Radiação (LIBPhys-UNL), Departamento de Física, Faculdade de Ciências e Tecnologia, FCT, Universidade Nova de Lisboa, 2829-516 Caparica, Portugal.
Sensors (Basel). 2019 Jan 25;19(3):501. doi: 10.3390/s19030501.
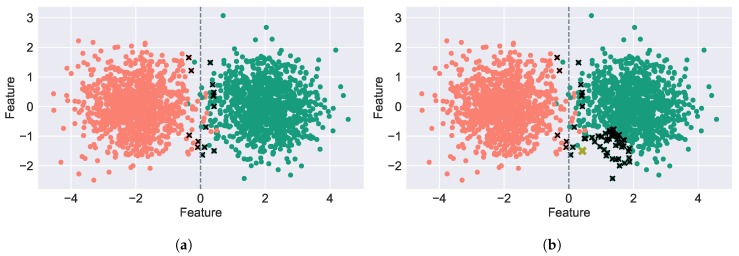
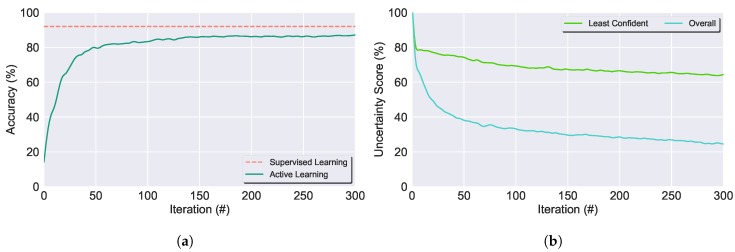
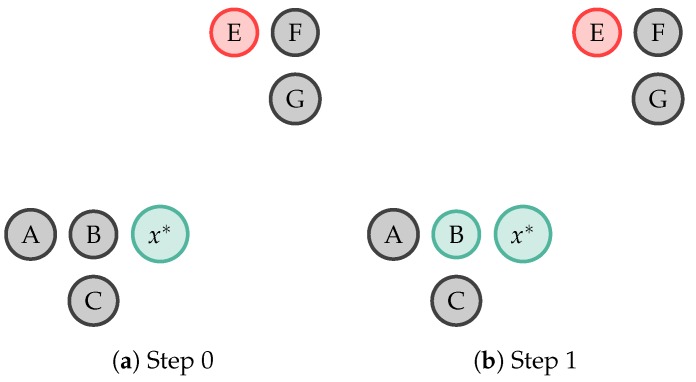
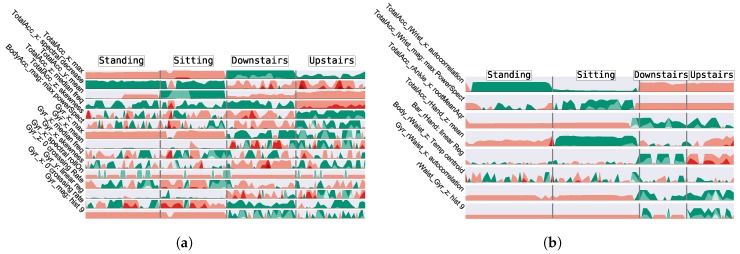
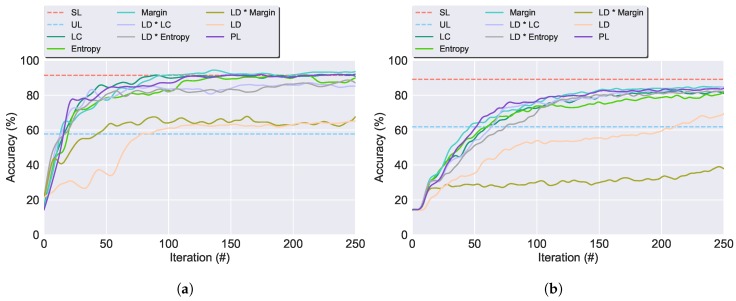
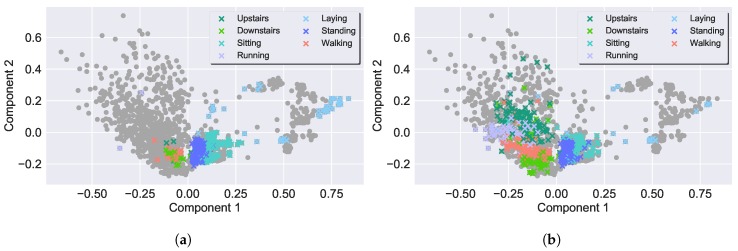
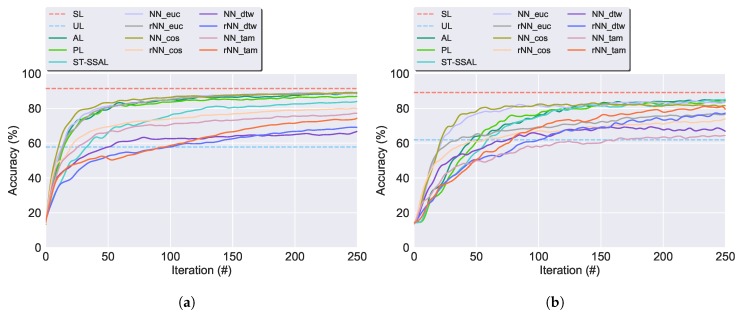
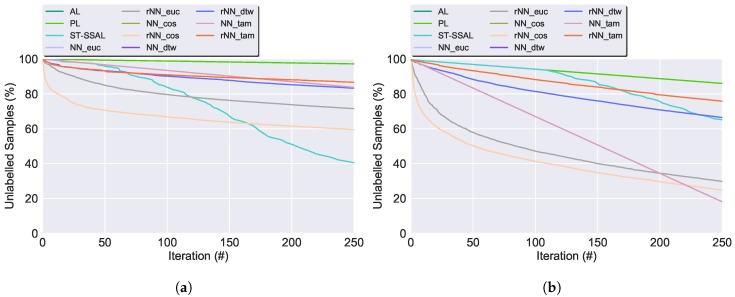
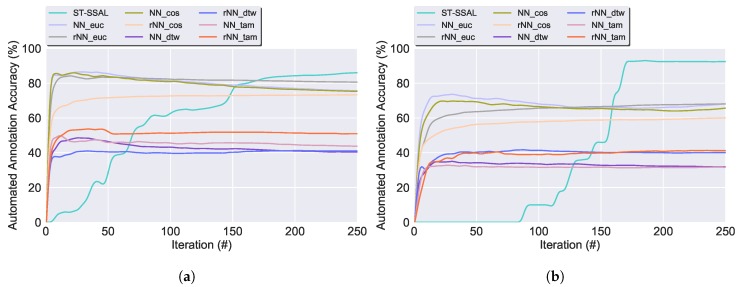
Modern smartphones and wearables often contain multiple embedded sensors which generate significant amounts of data. This information can be used for body monitoring-based areas such as healthcare, indoor location, user-adaptive recommendations and transportation. The development of Human Activity Recognition (HAR) algorithms involves the collection of a large amount of labelled data which should be annotated by an expert. However, the data annotation process on large datasets is expensive, time consuming and difficult to obtain. The development of a HAR approach which requires low annotation effort and still maintains adequate performance is a relevant challenge. We introduce a Semi-Supervised Active Learning (SSAL) based on Self-Training (ST) approach for Human Activity Recognition to partially automate the annotation process, reducing the annotation effort and the required volume of annotated data to obtain a high performance classifier. Our approach uses a criterion to select the most relevant samples for annotation by the expert and propagate their label to the most confident samples. We present a comprehensive study comparing supervised and unsupervised methods with our approach on two datasets composed of daily living activities. The results showed that it is possible to reduce the required annotated data by more than 89% while still maintaining an accurate model performance.
现代智能手机和可穿戴设备通常包含多个嵌入式传感器,这些传感器会生成大量数据。这些信息可用于基于身体监测的领域,例如医疗保健、室内定位、用户自适应推荐和交通。人类活动识别 (HAR) 算法的开发涉及到大量标记数据的收集,这些数据应由专家进行注释。然而,在大型数据集上进行数据注释的过程既昂贵又耗时,并且难以获得。开发一种需要低注释工作量但仍保持足够性能的 HAR 方法是一个相关的挑战。我们引入了一种基于自训练 (ST) 的半监督主动学习 (SSAL) 方法,用于人类活动识别,以部分实现注释过程的自动化,减少注释工作量和所需的注释数据量,从而获得高性能分类器。我们的方法使用一种标准来选择最相关的样本由专家进行注释,并将其标签传播到最有信心的样本。我们在两个由日常生活活动组成的数据集上进行了全面的研究,比较了监督和无监督方法与我们方法的性能。结果表明,在保持准确的模型性能的同时,我们可以将所需的注释数据减少 89%以上。