Centre for Neuroscience, Indian Institute of Science, Bangalore, 560012, India.
Donders Institute for Brain, Cognition and Behaviour in Nijmegen, Nijmegen, The Netherlands.
Sci Rep. 2019 Feb 14;9(1):2112. doi: 10.1038/s41598-018-38427-0.
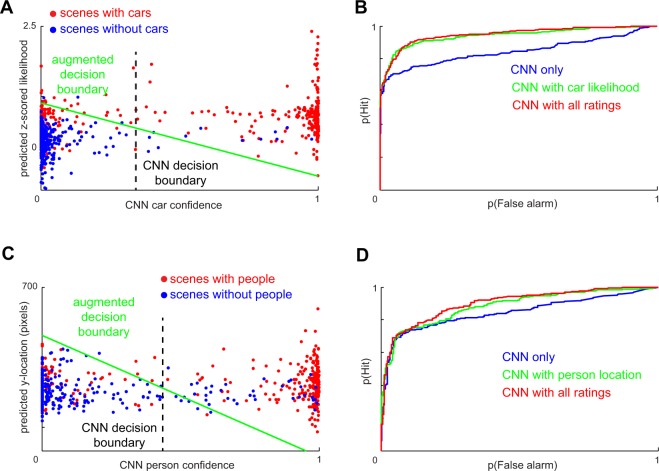
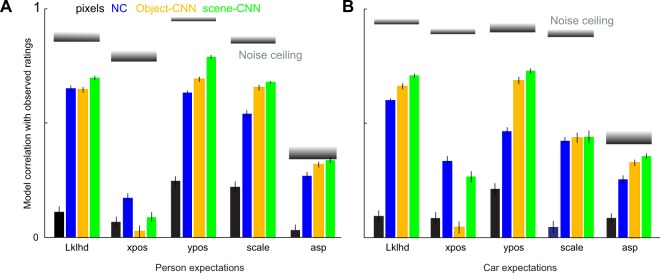
Scene context is known to facilitate object recognition in both machines and humans, suggesting that the underlying representations may be similar. Alternatively, they may be qualitatively different since the training experience of machines and humans are strikingly different. Machines are typically trained on images containing objects and their context, whereas humans frequently experience scenes without objects (such as highways without cars). If these context representations are indeed different, machine vision algorithms will be improved on augmenting them with human context representations, provided these expectations can be measured and are systematic. Here, we developed a paradigm to measure human contextual expectations. We asked human subjects to indicate the scale, location and likelihood at which cars or people might occur in scenes without these objects. This yielded highly systematic expectations that we could then accurately predict using scene features. This allowed us to predict human expectations on novel scenes without requiring explicit measurements. Next we augmented decisions made by deep neural networks with these predicted human expectations and obtained substantial gains in accuracy for detecting cars and people (1-3%) as well as on detecting associated objects (3-20%). In contrast, augmenting deep network decisions with other conventional computer vision features yielded far smaller gains. Taken together, our results show that augmenting deep neural networks with human-derived contextual expectations improves their performance, suggesting that contextual representations are qualitatively different in humans and deep neural networks.
场景上下文已知可促进机器和人类的物体识别,这表明潜在的表示可能是相似的。或者,它们可能在质量上有所不同,因为机器和人类的训练经验截然不同。机器通常在包含物体及其上下文的图像上进行训练,而人类则经常在没有物体的场景中体验(例如没有汽车的高速公路)。如果这些上下文表示确实不同,那么通过将人类上下文表示与机器视觉算法相结合,机器视觉算法将得到改进,前提是这些期望可以被测量并且是系统的。在这里,我们开发了一种衡量人类上下文期望的范式。我们要求人类受试者指出在没有这些物体的场景中,汽车或人可能出现的规模、位置和可能性。这产生了高度系统的期望,我们可以使用场景特征准确地预测这些期望。这使我们能够在不需要显式测量的情况下预测人类对新场景的期望。接下来,我们使用这些预测的人类期望来增强深度神经网络的决策,并在检测汽车和人(1-3%)以及检测相关物体(3-20%)方面获得了显著的准确性增益。相比之下,使用其他常规计算机视觉特征增强深度网络决策的增益要小得多。总之,我们的结果表明,通过使用人类生成的上下文期望来增强深度神经网络可以提高其性能,这表明上下文表示在人类和深度神经网络中在质量上有所不同。