MOE Key Lab of Bioinformatics/Bioinformatics Division, BNRIST (Beijing National Research Center for Information Science and Technology), Department of Automation, Tsinghua University, Beijing, 100084, China.
Centre for Molecular Medicine Norway (NCMM), Nordic EMBL Partnership, University of Oslo, 0349, Oslo, Norway.
Sci Rep. 2019 Feb 27;9(1):2877. doi: 10.1038/s41598-019-38979-9.
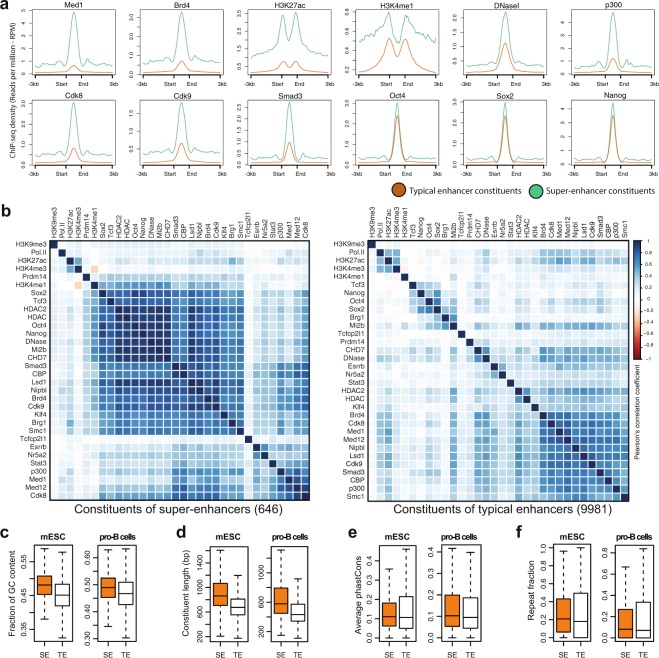
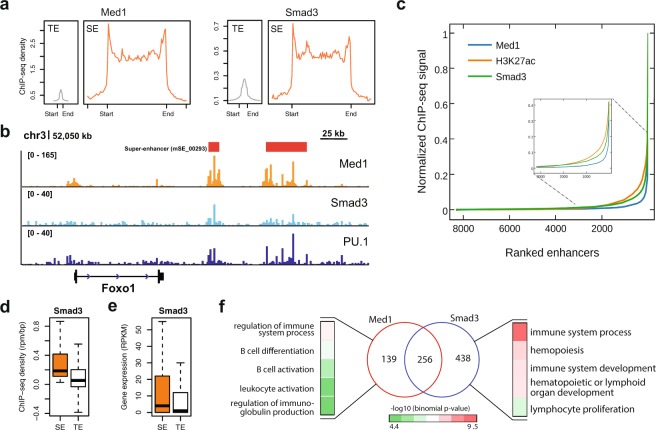
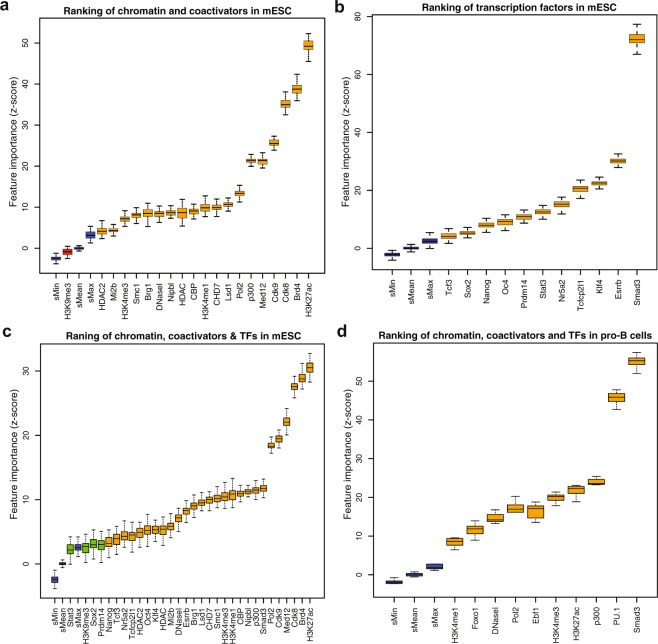
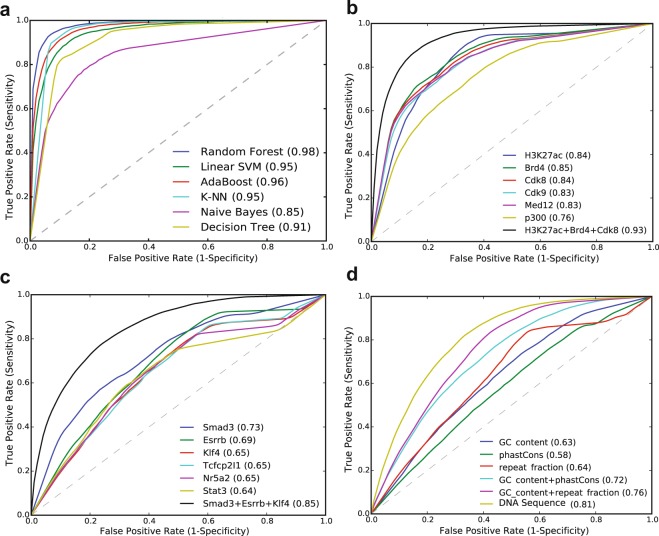
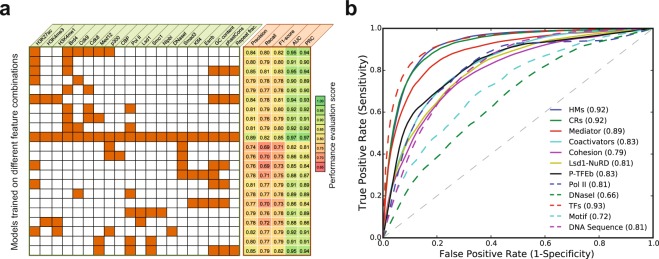
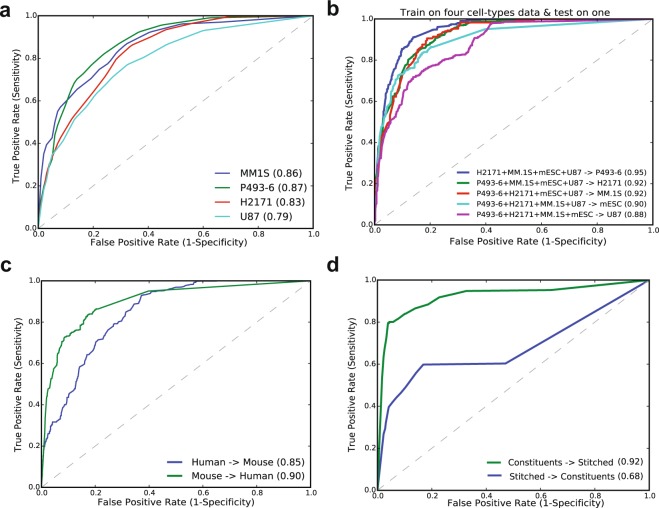
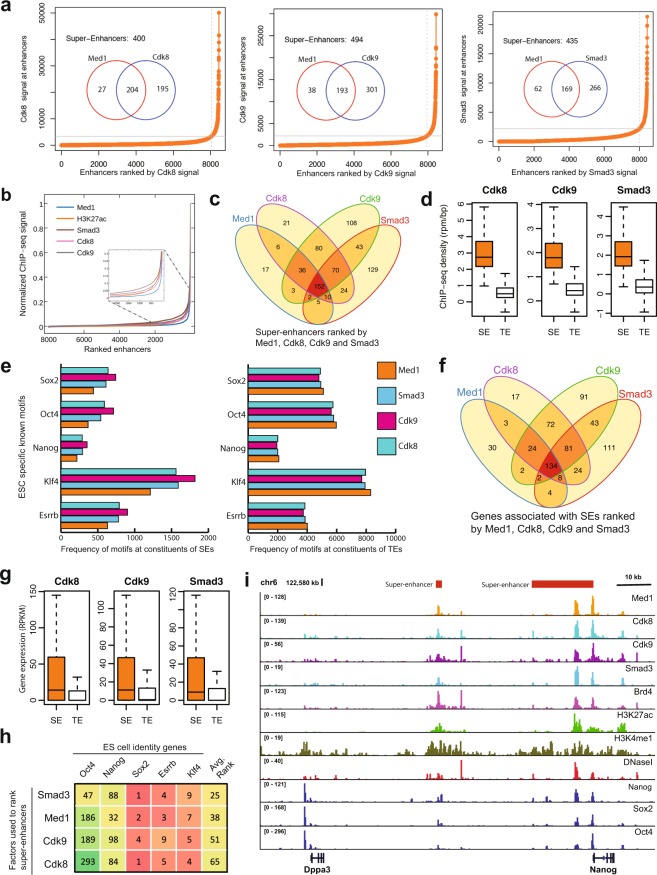
Super-enhancers (SEs) are clusters of transcriptional enhancers which control the expression of cell identity and disease-associated genes. Current studies demonstrated the role of multiple factors in SE formation; however, a systematic analysis to assess the relative predictive importance of chromatin and sequence features of SEs and their constituents is lacking. In addition, a predictive model that integrates various types of data to predict SEs has not been established. Here, we integrated diverse types of genomic and epigenomic datasets to identify key signatures of SEs and investigated their predictive importance. Through integrative modeling, we found Cdk8, Cdk9, and Smad3 as new features of SEs, which can define known and new SEs in mouse embryonic stem cells and pro-B cells. We compared six state-of-the-art machine learning models to predict SEs and showed that non-parametric ensemble models performed better as compared to parametric. We validated these models using cross-validation and also independent datasets in four human cell-types. Taken together, our systematic analysis and ranking of features can be used as a platform to define and understand the biology of SEs in other cell-types.
超级增强子 (SEs) 是转录增强子簇,可控制细胞身份和与疾病相关基因的表达。目前的研究表明,多种因素在 SE 形成中起作用;然而,缺乏对 SE 及其组成部分的染色质和序列特征的相对预测重要性进行系统分析。此外,尚未建立一种整合各种类型数据以预测 SE 的预测模型。在这里,我们整合了多种类型的基因组和表观基因组数据集,以识别 SE 的关键特征,并研究了它们的预测重要性。通过整合建模,我们发现 Cdk8、Cdk9 和 Smad3 是 SE 的新特征,可在小鼠胚胎干细胞和原 B 细胞中定义已知和新的 SE。我们比较了六种最先进的机器学习模型来预测 SE,并表明与参数模型相比,非参数集成模型表现更好。我们使用交叉验证和另外四个人类细胞类型中的独立数据集对这些模型进行了验证。总之,我们的系统分析和特征排序可作为一个平台,用于定义和理解其他细胞类型中 SE 的生物学特性。