Human Performance Laboratory, University of Calgary, Calgary, Alberta, Canada.
Hotchkiss Brain Institute, University of Calgary, Calgary, Alberta, Canada.
PLoS Comput Biol. 2019 Mar 4;15(3):e1006839. doi: 10.1371/journal.pcbi.1006839. eCollection 2019 Mar.
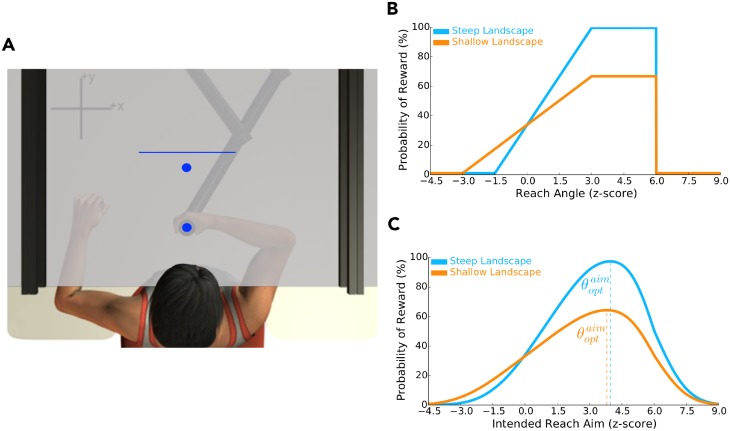
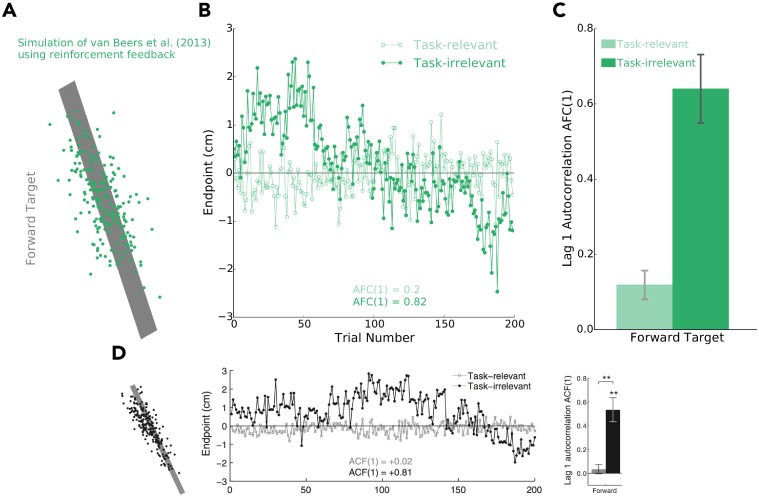
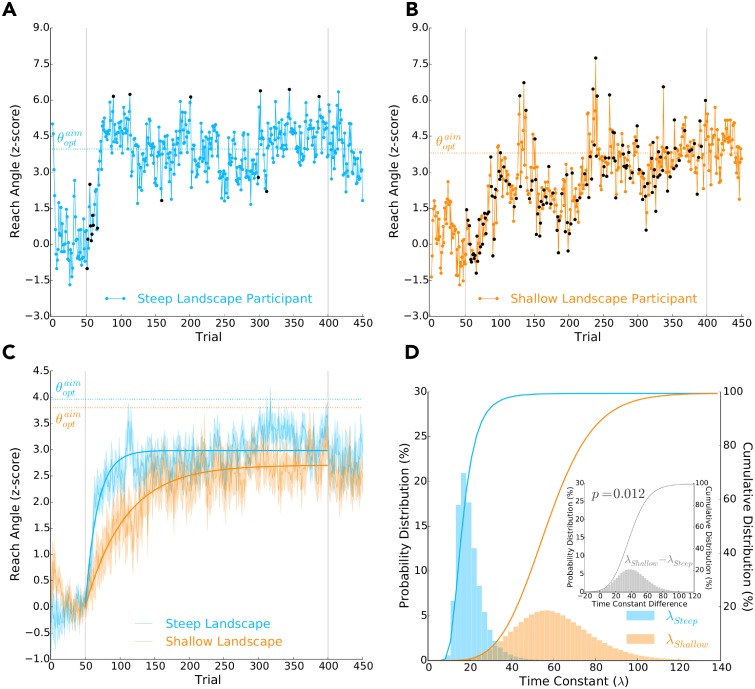
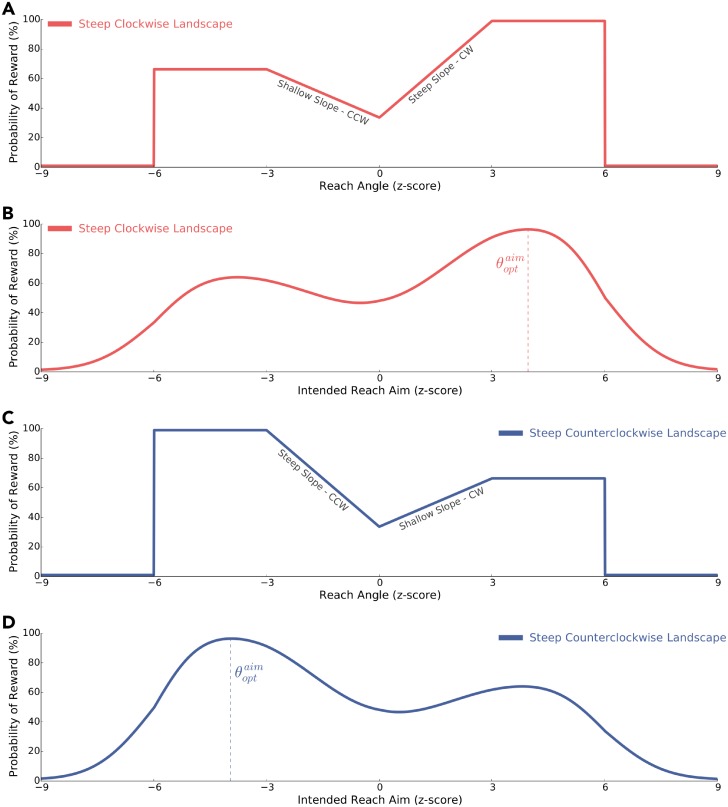
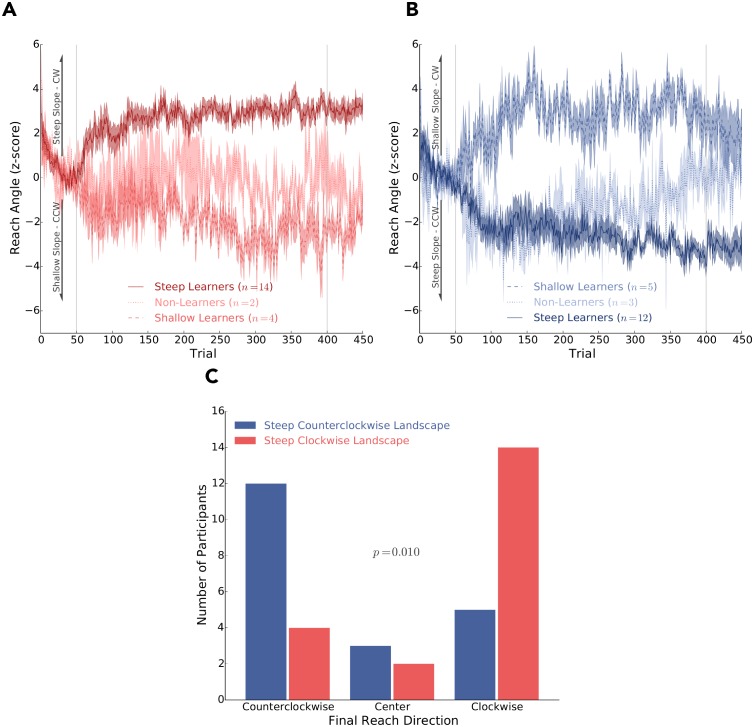
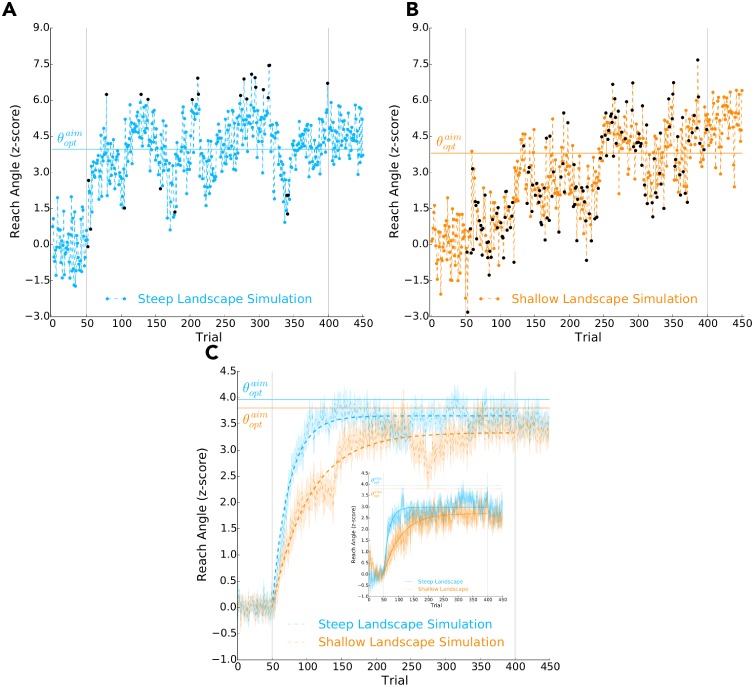
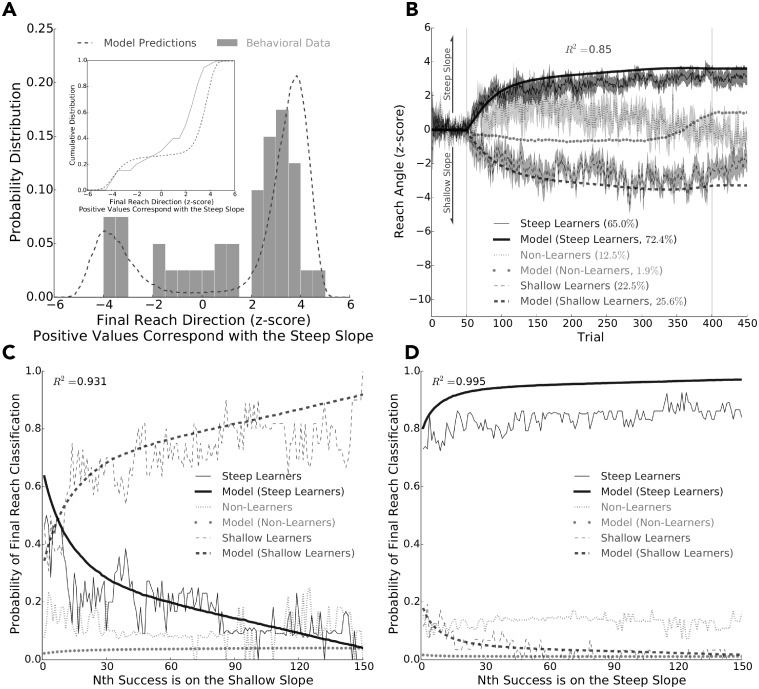
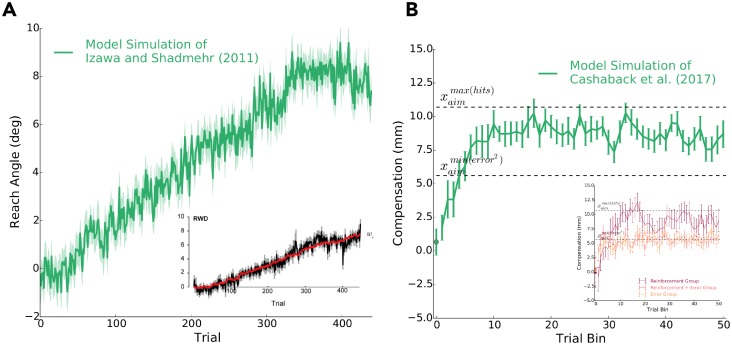
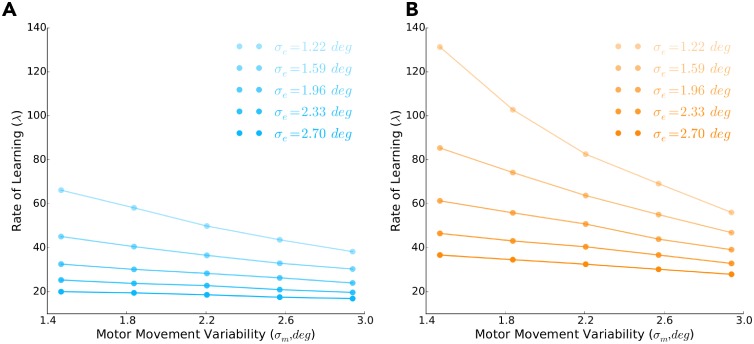
Consideration of previous successes and failures is essential to mastering a motor skill. Much of what we know about how humans and animals learn from such reinforcement feedback comes from experiments that involve sampling from a small number of discrete actions. Yet, it is less understood how we learn through reinforcement feedback when sampling from a continuous set of possible actions. Navigating a continuous set of possible actions likely requires using gradient information to maximize success. Here we addressed how humans adapt the aim of their hand when experiencing reinforcement feedback that was associated with a continuous set of possible actions. Specifically, we manipulated the change in the probability of reward given a change in motor action-the reinforcement gradient-to study its influence on learning. We found that participants learned faster when exposed to a steep gradient compared to a shallow gradient. Further, when initially positioned between a steep and a shallow gradient that rose in opposite directions, participants were more likely to ascend the steep gradient. We introduce a model that captures our results and several features of motor learning. Taken together, our work suggests that the sensorimotor system relies on temporally recent and spatially local gradient information to drive learning.
考虑以前的成功和失败对于掌握运动技能至关重要。我们对人类和动物如何从这种强化反馈中学习的了解很大程度上来自于涉及从少数离散动作中采样的实验。然而,当从连续的可能动作集中采样时,我们通过强化反馈来学习的方式还不太清楚。在连续的可能动作集中导航可能需要使用梯度信息来最大化成功。在这里,我们研究了当人类经历与连续的可能动作集相关的强化反馈时,他们如何调整手部的目标。具体来说,我们操纵了给定运动动作变化时奖励概率的变化(强化梯度),以研究其对学习的影响。我们发现,与浅梯度相比,参与者在暴露于陡峭梯度时学习速度更快。此外,当最初处于一个陡峭的和一个浅的梯度之间,它们的斜率是相反的,参与者更有可能上升到陡峭的梯度。我们提出了一个模型来捕获我们的结果和运动学习的几个特征。总的来说,我们的工作表明,感觉运动系统依赖于时间上最近和空间上局部的梯度信息来驱动学习。