Cashaback Joshua G A, McGregor Heather R, Mohatarem Ayman, Gribble Paul L
Brain and Mind Institute, Department of Psychology, Western University, London, ON, Canada.
Graduate Program in Neuroscience, Western University, London, ON, Canada.
PLoS Comput Biol. 2017 Jul 28;13(7):e1005623. doi: 10.1371/journal.pcbi.1005623. eCollection 2017 Jul.
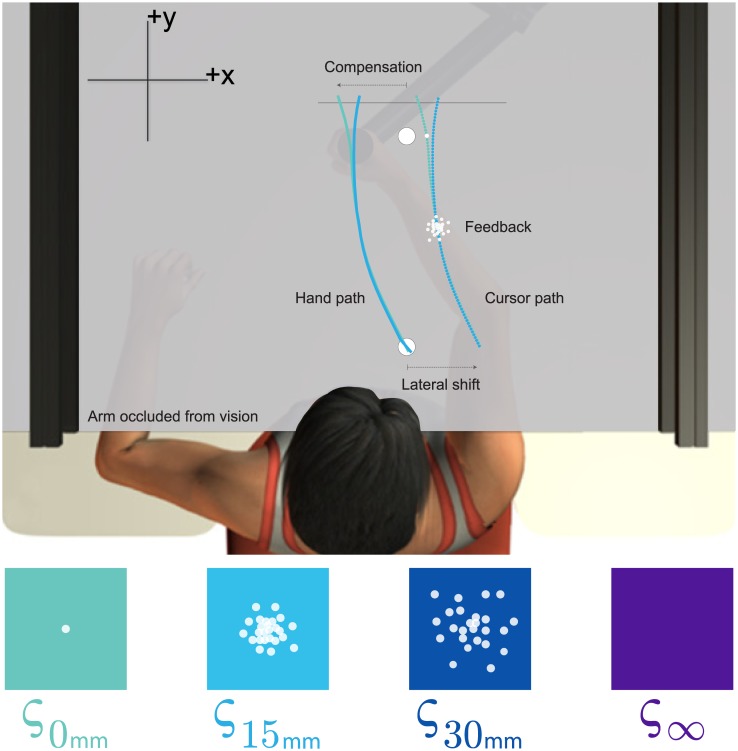
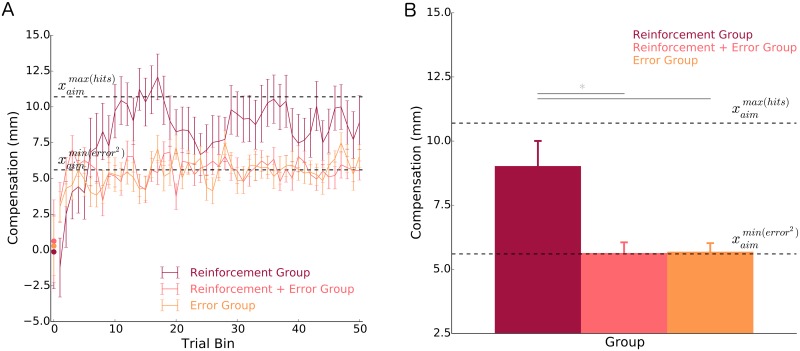
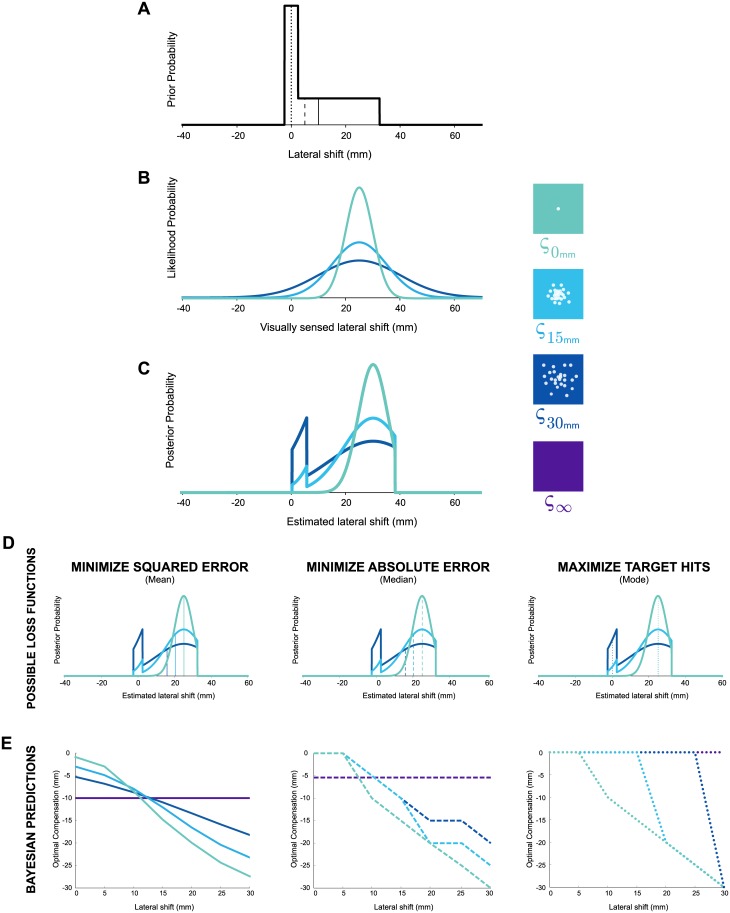
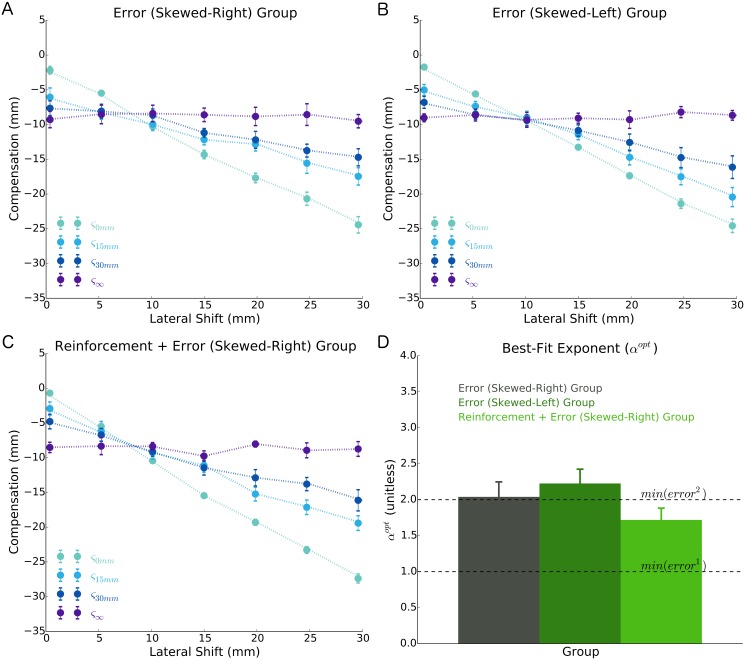
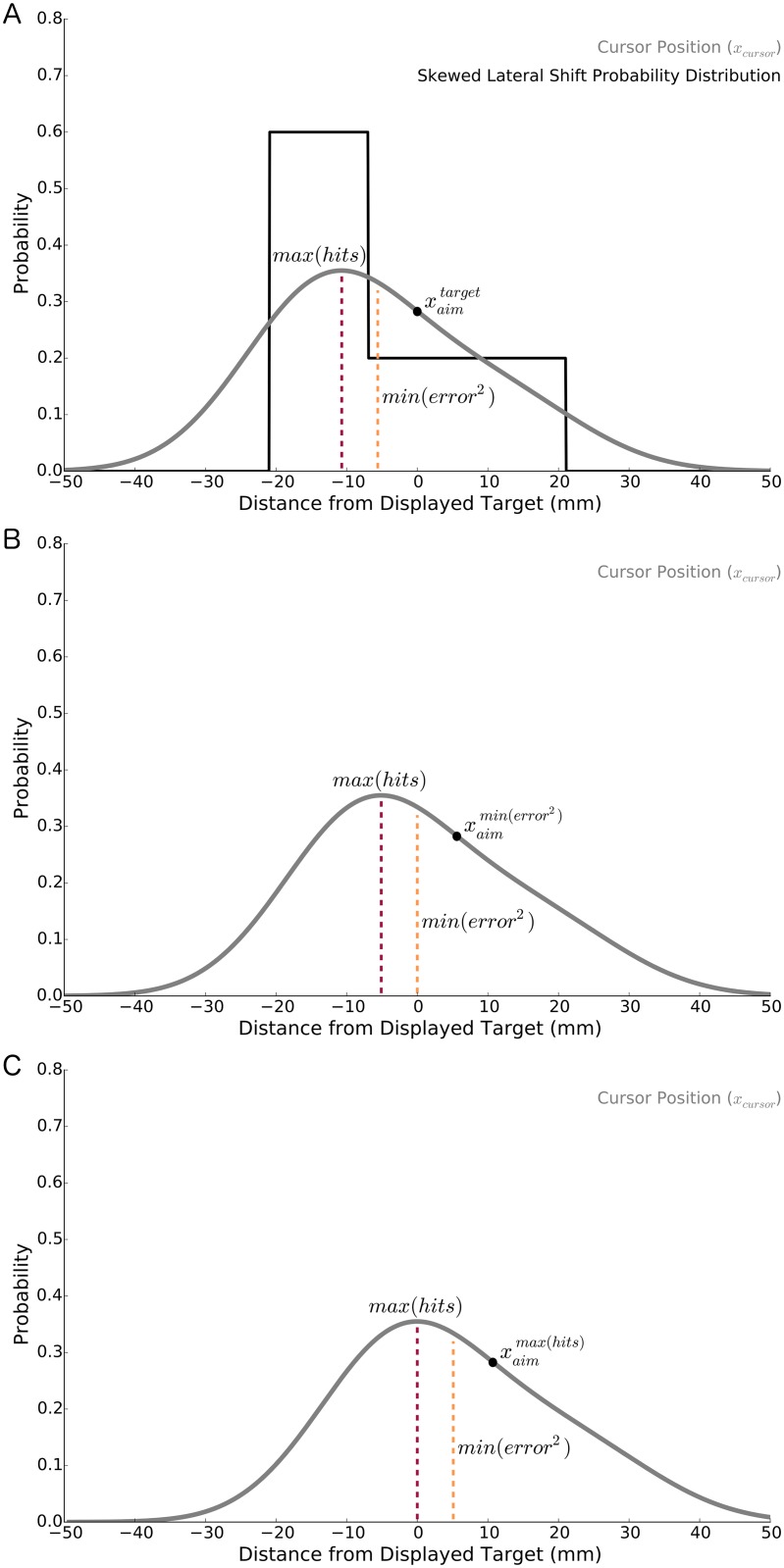
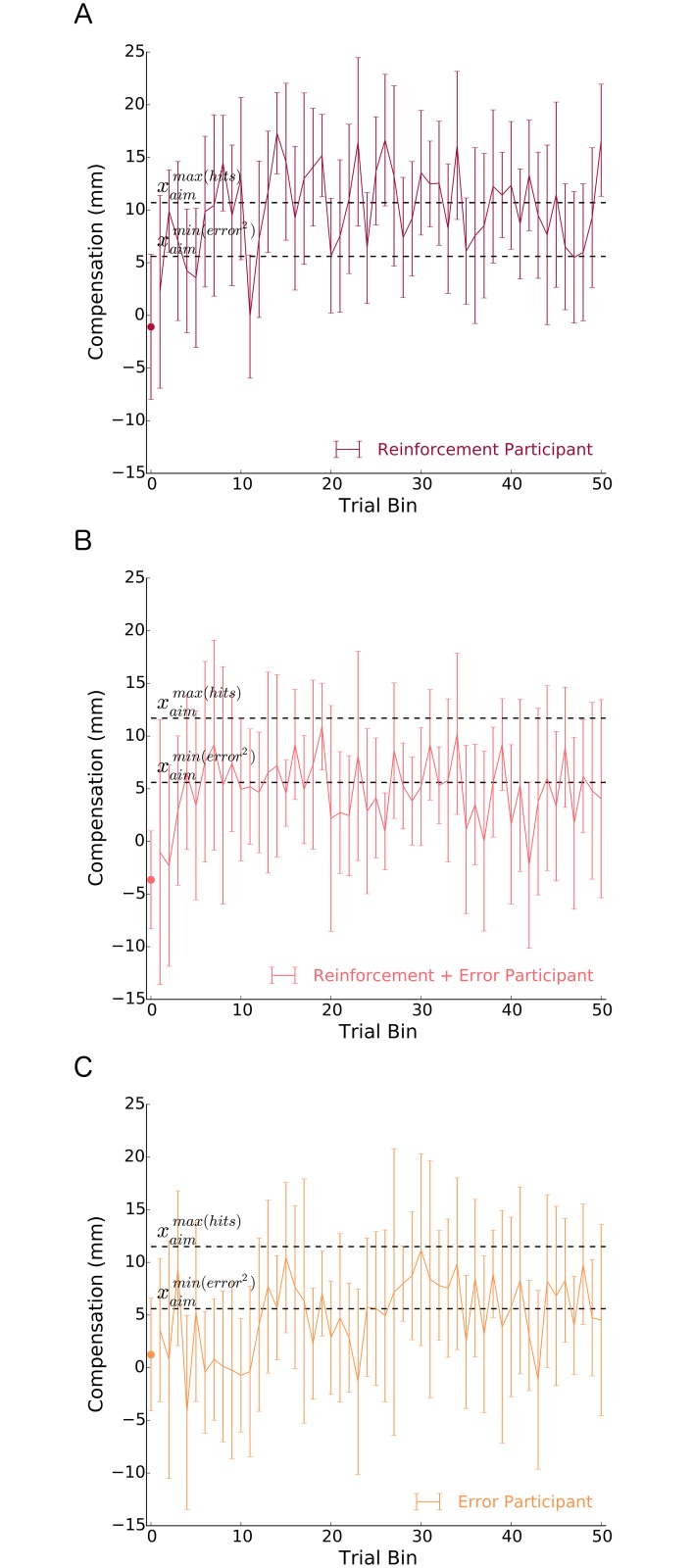
It has been proposed that the sensorimotor system uses a loss (cost) function to evaluate potential movements in the presence of random noise. Here we test this idea in the context of both error-based and reinforcement-based learning. In a reaching task, we laterally shifted a cursor relative to true hand position using a skewed probability distribution. This skewed probability distribution had its mean and mode separated, allowing us to dissociate the optimal predictions of an error-based loss function (corresponding to the mean of the lateral shifts) and a reinforcement-based loss function (corresponding to the mode). We then examined how the sensorimotor system uses error feedback and reinforcement feedback, in isolation and combination, when deciding where to aim the hand during a reach. We found that participants compensated differently to the same skewed lateral shift distribution depending on the form of feedback they received. When provided with error feedback, participants compensated based on the mean of the skewed noise. When provided with reinforcement feedback, participants compensated based on the mode. Participants receiving both error and reinforcement feedback continued to compensate based on the mean while repeatedly missing the target, despite receiving auditory, visual and monetary reinforcement feedback that rewarded hitting the target. Our work shows that reinforcement-based and error-based learning are separable and can occur independently. Further, when error and reinforcement feedback are in conflict, the sensorimotor system heavily weights error feedback over reinforcement feedback.
有人提出,感觉运动系统使用一种损失(成本)函数来评估存在随机噪声时的潜在运动。在此,我们在基于误差和基于强化的学习背景下测试这一观点。在一项伸手够物任务中,我们使用偏态概率分布使光标相对于真实手部位置横向移动。这种偏态概率分布的均值和众数分离,使我们能够区分基于误差的损失函数(对应于横向移动的均值)和基于强化的损失函数(对应于众数)的最优预测。然后,我们研究了感觉运动系统在伸手够物过程中决定手部瞄准位置时如何单独和组合使用误差反馈和强化反馈。我们发现,参与者根据所接收反馈的形式,对相同的偏态横向移动分布做出不同的补偿。当提供误差反馈时,参与者根据偏态噪声的均值进行补偿。当提供强化反馈时,参与者根据众数进行补偿。尽管收到了奖励击中目标的听觉、视觉和金钱强化反馈,但同时收到误差和强化反馈的参与者在反复未击中目标的情况下仍继续根据均值进行补偿。我们的研究表明,基于强化的学习和基于误差的学习是可分离的,并且可以独立发生。此外,当误差反馈和强化反馈发生冲突时,感觉运动系统对误差反馈的权重远高于强化反馈。